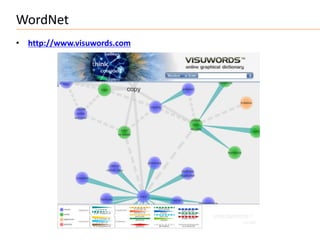
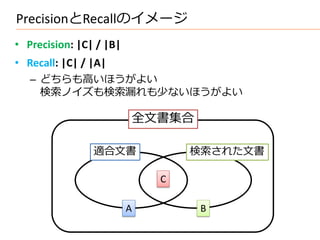
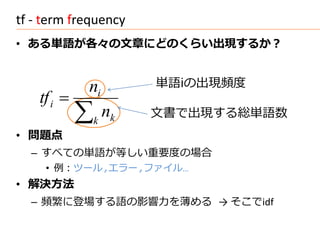
Search Engineでの位置づけ
Text
Browser
user interest
Text
Text Processing and Modeling
logical view logical view
MeCab
Query
NLTK etc. Indexing
user feedback Operations
Crawler
inverted index / Data
query WordNet Access
Searching Index
retrieved docs
Documents
(Web or DB)
Ranking
ranked docs
11.
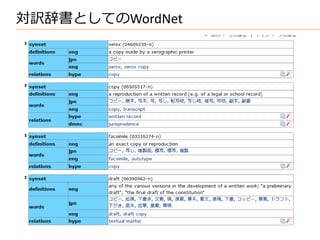
類義語の抽出
• WordNetから類義語抽出手順(日→英の場合)
–MeCabで標準形と品詞を取得
– 名詞・副詞・動詞・形容詞のみ抽出
– SQLにてword→sense→関連sense→関連word
• select * from word where lemma=? and pos=?, (標準形,品詞)
• select * from sense where wordid=?, (word["wordid"],)
• select * from sense where synset=? and lang=?,
(sense["synset"], “en”)
• select * from word where wordid=? and pos=?,
(sense2["wordid"], 品詞)
• これでOK?
– 結論から言うと、そのままではまずかった
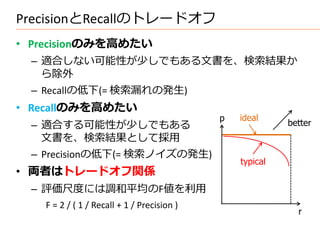
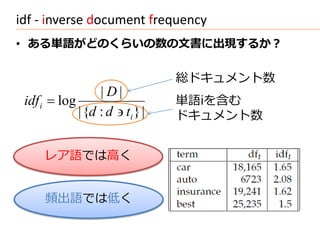
推定例(BIM)
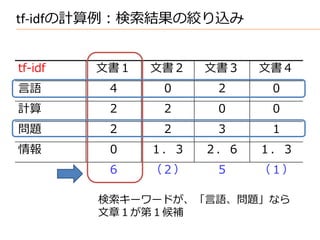
• 文章: 1= “a b c b d”, 2 = “a b e f b”, 3 = “b g c d”,
4 = “b d e”, 5 = “a b e g”, 6 = “b g h”, N=6
word a b c d e f g h
2 6 2 3 3 1 3 1
− + 0.5 4.5 0.5 4.5 3.5 3.5 5.5 3.5 5.5
+ 0.5 /2.5 /6.5 /2.5 /3.5 /3.5 /1.5 /3.5 /1.5
• クエリ: Q = “a c h” a c
− + 0.5 4.5 4.5
= 1 1 ∼ = ∙
∈1 ∩
+ 0.5 2.5 2.5
• ランキング 6 > 1 > 3 > 5 > 2 > 4
参考文献
• Christopher D.Manning, Prabhakar Raghavan, and Hinrich
Schütze, Introduction to Information Retrieval
• Michael McCandless, Erik Hatcher, and Otis Gospodnetid,
Lucene in Action, Second Edition
• Stephen Robertson, Hugo Zaragoza, SIGIR 2007 Tutorials -
The Probabilistic Relevance Model: BM25 and beyond.
• Donald Metzler, Victor Lavrenko, SIGIR 2009 Tutorials -
Probabilistic Models for Information Retrieval








![類義語の抽出
• WordNetから類義語抽出手順(日→英の場合)
– MeCabで標準形と品詞を取得
– 名詞・副詞・動詞・形容詞のみ抽出
– SQLにてword→sense→関連sense→関連word
• select * from word where lemma=? and pos=?, (標準形,品詞)
• select * from sense where wordid=?, (word["wordid"],)
• select * from sense where synset=? and lang=?,
(sense["synset"], “en”)
• select * from word where wordid=? and pos=?,
(sense2["wordid"], 品詞)
• これでOK?
– 結論から言うと、そのままではまずかった](https://image.slidesharecdn.com/20110416cross-languagesearch-110416082147-phpapp01/85/WordNet-11-320.jpg)






![Binary Independence Model [1]
• 仮定 A0
– 文章Dの適合性は、他の文書に依存しない
• P(R=1|D)によるランク付け
– R={0,1} … 適合度を示す確率変数
– D … 文章の中身(この時点ではクエリは考えない)
– ベイズの定理より
• ∝ ()
• 関係演算子 ∼ を「ランク順位が等しい」とおくと
= 1 = 1 ( = 1)
= 1 ∼ =
= 0 = 0 ( = 0)
与えられたクエリに対して定数。ラ
ンクするだけなら推定の必要なし](https://image.slidesharecdn.com/20110416cross-languagesearch-110416082147-phpapp01/85/WordNet-28-320.jpg)
![Binary Independence Model [2]
• 仮定 A1
– = * + … 文章を0 or 1の2値単語ベクトルで表現
• 仮定 A2
– … はRが与えられた時に相互に独立
• 実際にはそんなわけがない(単語並び替えても同じ?)
• が、仮定しなければ組み合わせ爆発を起こす
• Naive Bayes分類の仮定でもある
• よって
= 1 = 1
= 1 ∼ =
= 0 = 1](https://image.slidesharecdn.com/20110416cross-languagesearch-110416082147-phpapp01/85/WordNet-29-320.jpg)
![Binary Independence Model [3]
• 仮定 A3
– 0 = 1 = 0 = 0
– 空文章は、R=0 or 1どちらのクラスにも等しく出現
• ここで追加定義
– = = 1 = 1
– = = 1 = 0
• よって
1 −
∈
∉ 1 −
(1 − )
= 1 ∼ =
1 − (1 − )
1 − ∈](https://image.slidesharecdn.com/20110416cross-languagesearch-110416082147-phpapp01/85/WordNet-30-320.jpg)


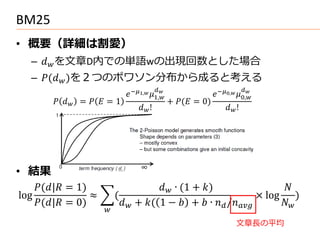
![Binary Independence Model [4]
• 仮定 A4
– = ∉ … クエリに出現しない単語は適合、
不適合文書において同じくらい出現と仮定
• 仮定 A5
– = 0.5 ∈ … クエリに出現する単語は、適合文
章に50%の確率で出現する
• 仮定 A6
– ≈ / … 不適合文章を全体で近似
IDF
• 結果
1 − 1 − − + 0.5
= 1 ∼ = =
∈
1 − ∈∩
∈∩
+ 0.5](https://image.slidesharecdn.com/20110416cross-languagesearch-110416082147-phpapp01/85/WordNet-33-320.jpg)





















![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)

























