More Related Content

PPTX
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ 
PPTX

PPTX

PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築 
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント 
PPTX

PPTX
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜 
PPTX
What's hot
![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
SparkとJupyterNotebookを使った分析処理 [Html5 conference] 
PPTX

PDF
ビッグじゃなくても使えるSpark Streaming 
PDF
Apache NiFi の紹介 #streamctjp 
PDF
SparkやBigQueryなどを用いた�モバイルゲーム分析環境 
PDF

PDF
PySpark Intro Part.2 with SQL Graph 
PDF

PDF
Apache drillを業務利用してみる(までの道のり) 
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話 
PDF
ヤフー発のメッセージキュー「Pulsar」のご紹介 
PPTX

PDF

PDF
Spark Streamingで作る、つぶやきビッグデータのクローン(Hadoop Spark Conference Japan 2016版) 
PDF
Spark 2.0 What's Next (Hadoop / Spark Conference Japan 2016 キーノート講演資料) 
PDF

PPTX
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006 
PDF
Spark勉強会_ibm_20151014-公開版 
PDF

PPTX
Apache cassandraと apache sparkで作るデータ解析プラットフォーム Viewers also liked

PDF

PDF
VMの歩む道。 Dalvik、ART、そしてJava VM 
PDF

PPTX
Kotlin is charming; The reasons Java engineers should start Kotlin. 
PPTX
U-NEXT学生インターン、過激なJavaの学び方と過激な要求 
PDF
Jjugccc2017spring-postgres-ccc_m1 
PDF
Java libraries you can't afford to miss 
PDF
SpotBugs(FindBugs)による 大規模ERPのコード品質改善 
PDF
Polyglot on the JVM with Graal (English) 
PDF
Java Clientで入門する Apache Kafka #jjug_ccc #ccc_e2 
PPTX
新卒2年目から始めるOSSのススメ~明日からできるコミットデビュー~ 
PDF
Javaチョットデキルへの道〜JavaコアSDKに見る真似したいコード10選〜 
PDF
日本Javaグループ2017年定期総会 #jjug 
PPTX
JJUG CCC 2017 Spring Seasar2からSpringへ移行した俺たちのアプリケーションがマイクロサービスアーキテクチャへ歩み始めた 
PPTX
データ履歴管理のためのテンポラルデータモデルとReladomoの紹介 #jjug_ccc #ccc_g3 
PDF
Java8移行は怖くない~エンタープライズ案件でのJava8移行事例~ 
PDF
Introduction of Project Jigsaw 
PPTX

PDF
思ったほど怖くない! Haskell on JVM 超入門 #jjug_ccc #ccc_l8 
PDF
Java8 コーディングベストプラクティス and NetBeansのメモリログから... Similar to Jjug ccc

PDF
Deep Learning On Apache Spark 
PPTX

PDF
BigDLでScala × DeepLearning に入門した話 
PDF
Project Hydrogen and Spark Graph - 分散処理 × AIをより身近にする、Apache Sparkの新機能 - (NTTデ... 
PDF

PDF
Getting Started with Deep Learning using Scala 
PDF
20180110 AI&ロボット勉強会 Deeplearning4J と時系列データの異常検知について 
PDF

PPTX
1028 TECH & BRIDGE MEETING 
PDF
Data Scientist Workbench 入門 
PDF
データ分析に必要なスキルをつけるためのツール~Jupyter notebook、r連携、機械学習からsparkまで~ 
PDF
20161027 hadoop summit Generating Recommendations at Amazon Scale with Apach... Recently uploaded

PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと... 
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1 
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ 
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2 
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool 
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup Jjug ccc
- 1.
© 2016 IBMCorporation
Spark + DeepLearning4J の特長と最新動
向(仮)
Tanaka Y.P
2017-3-21
- 2.
© 2016 IBMCorporation2
自己紹介
田中裕一(yuichi tanaka)
主にアーキテクチャとサーバーサイドプログラムを担当
することが多い。Hadoop/Spark周りをよく触ります。
Node.js、Python、最近はSpark周りの仕事でScalaを書く
ことが多い気がします。
休日はOSS周りで遊んだり。
詳解 Apache Spark
- 3.
© 2016 IBMCorporation3
アジェンダ
• Apache Sparkのおさらい
• DeepLearningのおさらい
• SparkでDeepLearningはどうか?
• 既存のDeepLearningFrameworkの問題はどこにあったのか
• DeepLearning4J on Sparkはどう動いているのか
- 4.
© 2016 IBMCorporation4
Sparkとは
従来Hadoopでは難しかったBigDataにおける
アドホック分析やニアリアルタイム処理を実現するための
InMemory分散並列処理フレームワーク。
• HDFSを筆頭にCassandraなど分散ストレージのデータと相性が良い
• YARN,Mesos,Standaloneの3種類の分散処理基盤の上で動作
• SparkSQL,Streaming,MLlib,GraphXといった処理の拡張を持つ
- 5.
© 2016 IBMCorporation5
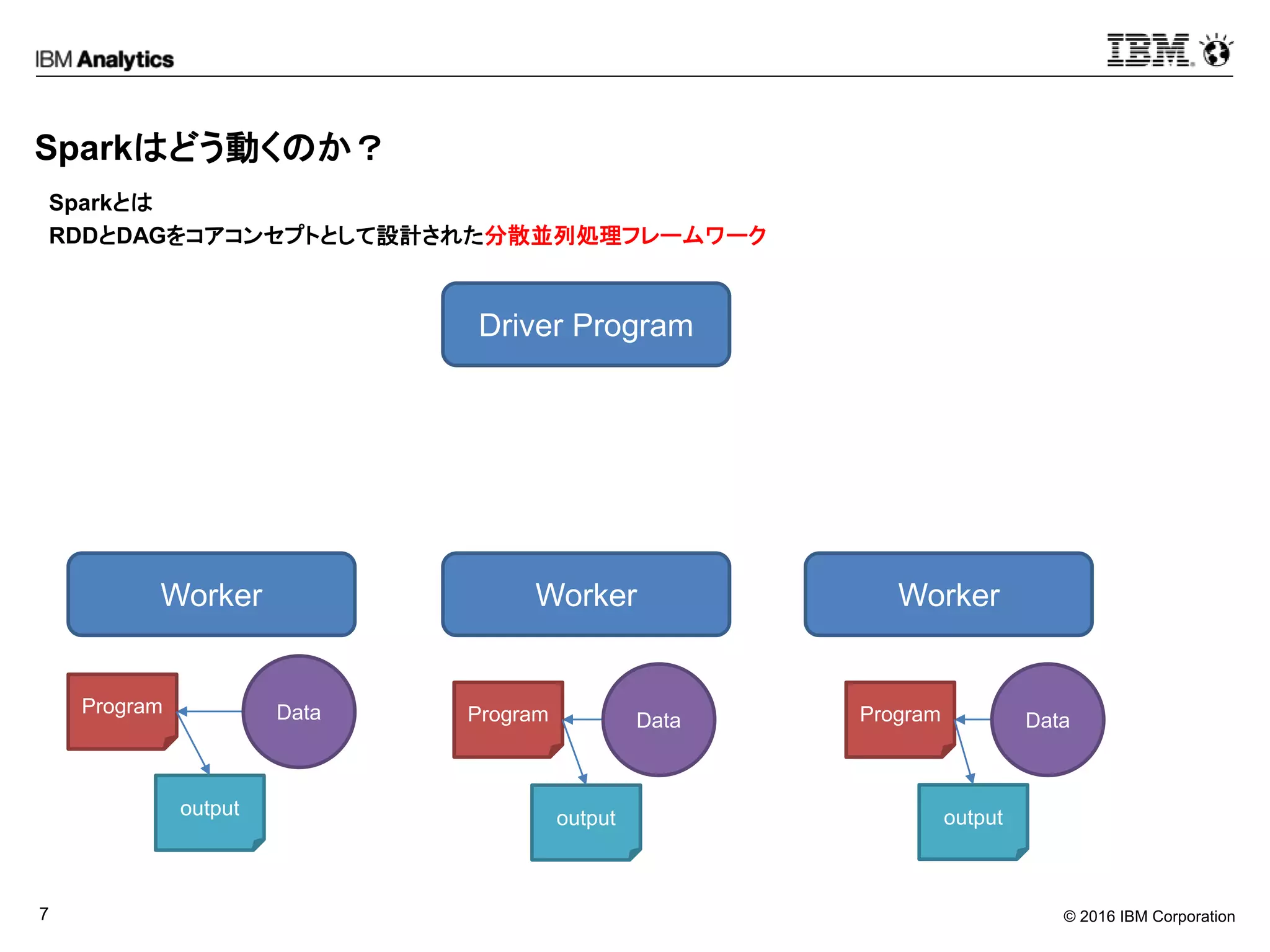
Sparkはどう動くのか?
Sparkとは
RDDとDAGをコアコンセプトとして設計された分散並列処理フレームワーク
Driver Program
Worker Worker Worker
ProgramProgramProgram
DataDataData
- 6.
© 2016 IBMCorporation6
Driver Program
Worker Worker Worker
ProgramProgramProgram
DataDataData
Sparkはどう動くのか?
Sparkとは
RDDとDAGをコアコンセプトとして設計された分散並列処理フレームワーク
- 7.
© 2016 IBMCorporation7
Driver Program
Worker Worker Worker
ProgramProgramProgram
DataDataData
output output output
Sparkはどう動くのか?
Sparkとは
RDDとDAGをコアコンセプトとして設計された分散並列処理フレームワーク
- 8.
© 2016 IBMCorporation8
SparkでMachineLearning
• MLlibは大きく2つの実装に分かれる
• spark.mllib
• spark.ml
• どちらを使えば良いか?
• spark.mlを使うこと!
• spark.mllibは2系でメンテモードになりました。
• 今後新しい機能は追加されません。タブン
• (予定では3.0でremoveされる)
- 9.
© 2016 IBMCorporation9
SparkでMachineLearning
• そもそもMachineLearningとは
• データから新たな価値を見出すための手法の一つ
• MachineLearningでは前処理が重要
• 前処理8割といわれる程、データサイエンスの占める作業のうち、大部分がこの作業
• 前処理の例
• フィールドのコード化(性別変換・カテゴリ変換)
• ID変換(Join,CookieSync,ジオコーディング)
• 集計(GroupBy,Sum,Max,Min)
• 形態素解析系処理(構文解析、分かち書き、ストップワード)
• 名寄せ(表記ゆれ)
• クレンジング(無効値処理、欠損値補完、外れ値補正)
• 画像系処理(特徴抽出、スライス、サイズ変換、グレースケール)
• 背景
データは分析されることを前提としていない。こう言った配慮は事業において負荷となる
- 10.
© 2016 IBMCorporation10
HDFS
従来の課題は何か、Sparkがなぜマッチするのか
• こうした多様な前処理は従来のHadoop Ecosystemでの実現は難しかった
CSV
ETL
中間
DB
Table
中間
MLETL
中間 モデル
APP
Memory
CSV
ETL
DF
DF
Table
DF
MLETL
DF モデル
Streaming
- 11.
© 2016 IBMCorporation11
DeepLearningとは
• 機会学習の一つであるNNの層を重ね高精度な予測・分類処理を行うための手法
• 色々な関数の層を重ねて精度を向上させる
• 画像識別の分野で精度が高くて有名(ResNet/GoogLeNet等)
例)VGG16
- 12.
© 2016 IBMCorporation12
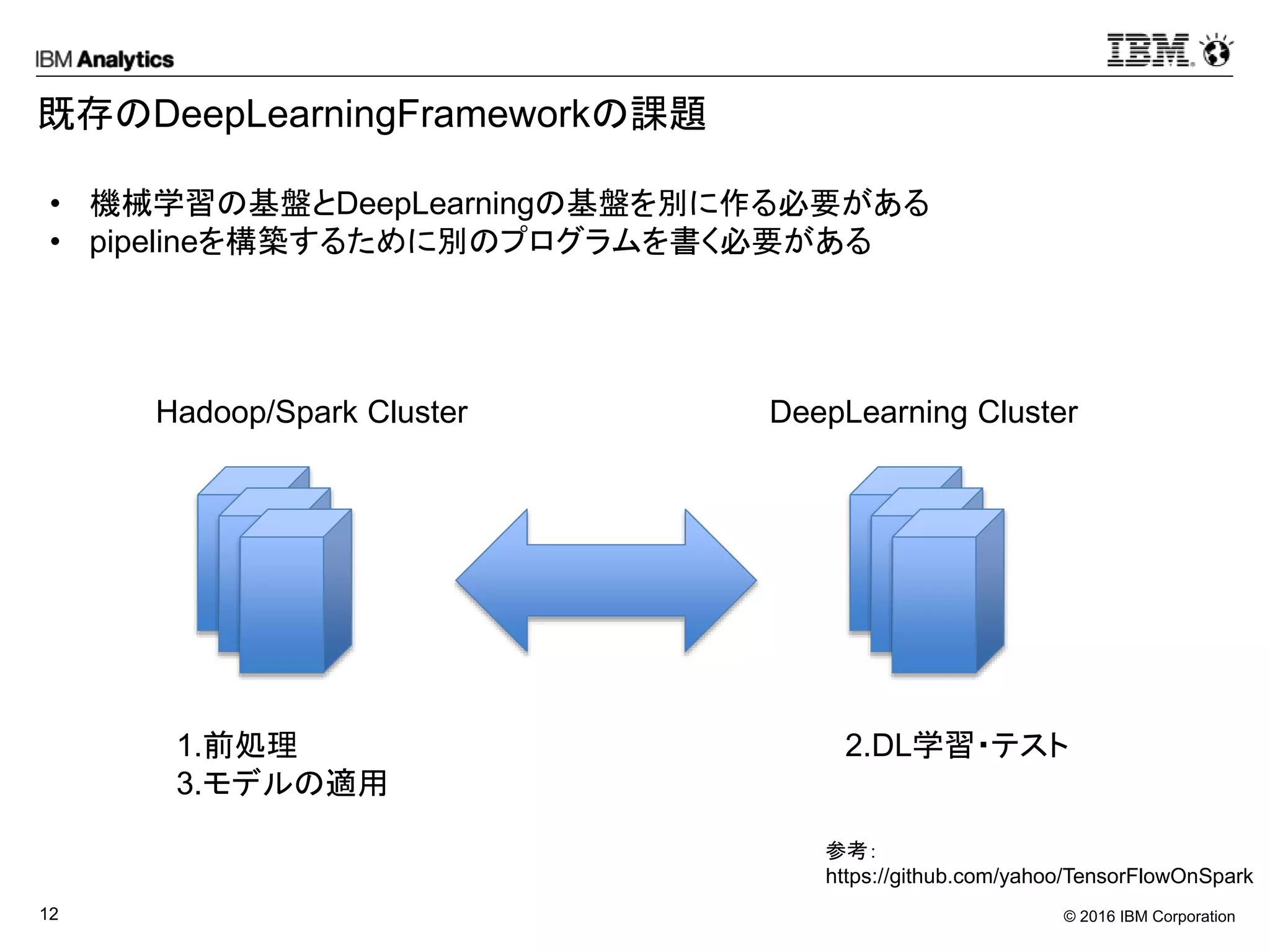
既存のDeepLearningFrameworkの課題
• 機械学習の基盤とDeepLearningの基盤を別に作る必要がある
• pipelineを構築するために別のプログラムを書く必要がある
参考:
https://github.com/yahoo/TensorFlowOnSpark
Hadoop/Spark Cluster DeepLearning Cluster
1.前処理
3.モデルの適用
2.DL学習・テスト
- 13.
© 2016 IBMCorporation13
SparkでDeepLearningはどうか?
• MLlibだけではDeepLearningは難しい(多層パーセプトロンはある)
• Spark v2.1でも難しい
• 16年、17年に各DLフレームワークがSparkに対応
• DL4J on Spark : https://deeplearning4j.org/
• Caffe on Spark : https://github.com/yahoo/CaffeOnSpark
• TensorSpark(Tensorflow on Spark) : https://github.com/adatao/tensorspark
• Distributed Keras : https://github.com/cerndb/dist-keras
• Sparkling Water : https://github.com/h2oai/sparkling-water/tree/rel-2.0
• TensorFlowonSpark : https://github.com/yahoo/TensorFlowOnSpark
その他にも雨後の筍のように。
※Web上でも様々な記事が上がっていますが、すでにメンテされてないリポジトリも
あるので選定する際は注意が必要
- 14.
© 2016 IBMCorporation14
DeepLearning4JはJava,Scalaから利用可能な分散処理型のDeepLearningのライブラリ
• 今現在stable v0.8
Hadoop/Sparkの上で動作可能 ー> 既存のClusterリソースが利用可能
• CPU,GPUが利用可能
• Keras被せればPythonからも利用可能
- 15.
© 2016 IBMCorporation15
DeepLearning4Jを例にSpark上でどう動くのか
Driver
Worker
Worker
Worker
Worker
Worker
Data d1 d2 ・・
1−1 1−2 1−3 1−4 1−5
分割
パラ
メータ
配布
分割
モーメンタム
rmsprop
adagrad
なども
Parameter
Average
再度Diverに戻し、
次のデータを同様に処理する
データを設定に基づいて分割
- 16.
© 2016 IBMCorporation16
DeepLearning4Jの表現
Helperの作成と、学習率などの設定
- 17.
- 18.
© 2016 IBMCorporation18
DeepLearning4Jの表現
Masterの設定
学習(fit)
- 19.
- 20.
© 2016 IBMCorporation20
DeepLearning4Jは銀の弾か?
• GPUは使えるが、YARNにGPUのリソース管理機能がない
• 複数のDLのtrainを流す際に留意する必要がある(リソースの取り合い)
• 高価なGPUをCluster配下の全てのサーバーに配備するのが基本
• CPU/GPUの混在が難しい/できない
• 表現から見るように結構Javaで表現すると記述量が多い
• KerasをDL4Jにかぶせた方が楽なのは間違いない
• あれ?でもそれならPythonで書いた方が・・・・
• 強化学習系はサポートしてない
• RL4J使ってね
- 21.
© 2016 IBMCorporation21
まとめ
• DL4Jを使うことで既存のHadoop/Spark資産を利用したDL環境が構築可能
• 新規で始める場合も他の学習器の組み合わせ・前処理など考えるとSparkは良い選択肢
• BigDataの一括前処理(コード変換や欠損値補完)
• DeepLearning以外の学習器の併用
• PythonやRでのデータサイエンティストのコードをJava or Scalaなどの
Production環境へのデプロイでDL4Jは良いかも
Editor's Notes
- #2 1
- #3 会社ではSparkとHadoopのスペシャリストやってます。
- #5 おさらい1ページ
- #12 DeepLearningとは