Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hiroshi Shimizu
PDF, PPTX
5,553 views
SapporoR#6 初心者セッションスライド
SapporoR#6の初心者セッションで使ったスライドです。
Data & Analytics
◦
Read more
10
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 109
2
/ 109
3
/ 109
4
/ 109
5
/ 109
6
/ 109
7
/ 109
8
/ 109
9
/ 109
10
/ 109
11
/ 109
12
/ 109
13
/ 109
14
/ 109
15
/ 109
16
/ 109
17
/ 109
18
/ 109
19
/ 109
20
/ 109
21
/ 109
22
/ 109
23
/ 109
24
/ 109
25
/ 109
26
/ 109
27
/ 109
28
/ 109
29
/ 109
30
/ 109
31
/ 109
32
/ 109
33
/ 109
34
/ 109
35
/ 109
36
/ 109
37
/ 109
38
/ 109
39
/ 109
40
/ 109
41
/ 109
42
/ 109
43
/ 109
44
/ 109
45
/ 109
46
/ 109
47
/ 109
48
/ 109
49
/ 109
50
/ 109
51
/ 109
52
/ 109
53
/ 109
54
/ 109
55
/ 109
56
/ 109
57
/ 109
58
/ 109
59
/ 109
60
/ 109
61
/ 109
62
/ 109
63
/ 109
64
/ 109
65
/ 109
66
/ 109
67
/ 109
68
/ 109
69
/ 109
70
/ 109
71
/ 109
72
/ 109
73
/ 109
74
/ 109
75
/ 109
76
/ 109
77
/ 109
78
/ 109
79
/ 109
80
/ 109
81
/ 109
82
/ 109
83
/ 109
84
/ 109
85
/ 109
86
/ 109
87
/ 109
88
/ 109
89
/ 109
90
/ 109
91
/ 109
92
/ 109
93
/ 109
94
/ 109
95
/ 109
96
/ 109
97
/ 109
98
/ 109
99
/ 109
100
/ 109
101
/ 109
102
/ 109
103
/ 109
104
/ 109
105
/ 109
106
/ 109
107
/ 109
108
/ 109
109
/ 109
More Related Content
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PPTX
Anaconda navigatorのアップデートが終わらないときの対処方法メモ
by
ayohe
PPTX
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
PPTX
StanとRでベイズ統計モデリング読書会Ch.9
by
考司 小杉
PPTX
畳み込みLstm
by
tak9029
PDF
ベイズモデリングと仲良くするために
by
Shushi Namba
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
階層ベイズとWAIC
by
Hiroshi Shimizu
Anaconda navigatorのアップデートが終わらないときの対処方法メモ
by
ayohe
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
StanとRでベイズ統計モデリング読書会Ch.9
by
考司 小杉
畳み込みLstm
by
tak9029
ベイズモデリングと仲良くするために
by
Shushi Namba
階層モデルの分散パラメータの事前分布について
by
hoxo_m
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
What's hot
PDF
潜在クラス分析
by
Yoshitake Takebayashi
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PPTX
統計的因果推論からCausalMLまで走り抜けるスライド
by
fusha
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PPTX
NLPにおけるAttention~Seq2Seq から BERTまで~
by
Takuya Ono
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
協調フィルタリング入門
by
hoxo_m
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PDF
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
PPTX
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
by
西岡 賢一郎
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
2 3.GLMの基礎
by
logics-of-blue
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
潜在クラス分析
by
Yoshitake Takebayashi
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
統計的因果推論からCausalMLまで走り抜けるスライド
by
fusha
一般化線形混合モデル入門の入門
by
Yu Tamura
NLPにおけるAttention~Seq2Seq から BERTまで~
by
Takuya Ono
階層ベイズによるワンToワンマーケティング入門
by
shima o
協調フィルタリング入門
by
hoxo_m
Stan超初心者入門
by
Hiroshi Shimizu
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
社会心理学とGlmm
by
Hiroshi Shimizu
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
by
西岡 賢一郎
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
ベイズ統計入門
by
Miyoshi Yuya
2 3.GLMの基礎
by
logics-of-blue
ベイズ統計学の概論的紹介
by
Naoki Hayashi
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
2 4.devianceと尤度比検定
by
logics-of-blue
Similar to SapporoR#6 初心者セッションスライド
PDF
第1回Rを使って統計分析を勉強する会
by
Nobuto Inoguchi
PDF
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
PPTX
Rプログラミング01 はじめの一歩
by
wada, kazumi
PDF
初心者講習会資料(Osaka.R#7)
by
Masahiro Hayashi
PDF
10min r study_tokyor25
by
Nobuaki Oshiro
PDF
20181114 r
by
Yutaka Terasawa
PDF
Yamadai.R チュートリアルセッション
by
考司 小杉
PDF
Hiroshimar4_Rintro
by
SAKAUE, Tatsuya
PDF
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
PDF
TokyoR#31 初心者セッション
by
TokorosawaYoshio
PDF
統計ソフトRの使い方_2015.04.17
by
hicky1225
PDF
外国語教育メディア学会第54回全国研究大会ワークショップ「Rによる外国語教育データの分析と可視化の基本」
by
SAKAUE, Tatsuya
PDF
初心者講習会資料(Osaka.r#6)
by
Masahiro Hayashi
PPTX
Tokyo r38
by
Takashi Minoda
PPTX
関東第1回r勉強会
by
Iida Keisuke
PPTX
Tokyo r30 beginner
by
Takashi Minoda
PDF
初心者講習会資料(Osaka.R#5)
by
Masahiro Hayashi
PDF
10min r study_tokyor25
by
Nobuaki Oshiro
PPT
K010 appstat201201
by
t2tarumi
PDF
10分で分かるr言語入門ver2.9 14 0920
by
Nobuaki Oshiro
第1回Rを使って統計分析を勉強する会
by
Nobuto Inoguchi
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
Rプログラミング01 はじめの一歩
by
wada, kazumi
初心者講習会資料(Osaka.R#7)
by
Masahiro Hayashi
10min r study_tokyor25
by
Nobuaki Oshiro
20181114 r
by
Yutaka Terasawa
Yamadai.R チュートリアルセッション
by
考司 小杉
Hiroshimar4_Rintro
by
SAKAUE, Tatsuya
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
TokyoR#31 初心者セッション
by
TokorosawaYoshio
統計ソフトRの使い方_2015.04.17
by
hicky1225
外国語教育メディア学会第54回全国研究大会ワークショップ「Rによる外国語教育データの分析と可視化の基本」
by
SAKAUE, Tatsuya
初心者講習会資料(Osaka.r#6)
by
Masahiro Hayashi
Tokyo r38
by
Takashi Minoda
関東第1回r勉強会
by
Iida Keisuke
Tokyo r30 beginner
by
Takashi Minoda
初心者講習会資料(Osaka.R#5)
by
Masahiro Hayashi
10min r study_tokyor25
by
Nobuaki Oshiro
K010 appstat201201
by
t2tarumi
10分で分かるr言語入門ver2.9 14 0920
by
Nobuaki Oshiro
More from Hiroshi Shimizu
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PDF
負の二項分布について
by
Hiroshi Shimizu
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PDF
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PDF
媒介分析について
by
Hiroshi Shimizu
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
Tokyo r53
by
Hiroshi Shimizu
PDF
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
PPTX
Latent rank theory
by
Hiroshi Shimizu
PDF
Rで潜在ランク分析
by
Hiroshi Shimizu
PDF
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
PPTX
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
PDF
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
Stanコードの書き方 中級編
by
Hiroshi Shimizu
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
負の二項分布について
by
Hiroshi Shimizu
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
媒介分析について
by
Hiroshi Shimizu
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
Stanでガウス過程
by
Hiroshi Shimizu
Tokyo r53
by
Hiroshi Shimizu
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
Latent rank theory
by
Hiroshi Shimizu
Rで潜在ランク分析
by
Hiroshi Shimizu
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
SapporoR#6 初心者セッションスライド
1.
SapporoR#6 初心者セッション 清水裕士 関西学院大学
2.
自己紹介 • 清水裕士 – 所属:関西学院大学 •
※「かんせいがくいん」 と読む – お仕事:社会心理学 – 趣味:Stan・統計ソフトウェア開発 • Web – Twitter:@simizu706 – ブログ:http://norimune.net HiroshimaR#3
3.
本セッションの目的
4.
主催者(@uranoken)さんに Rを使わせること
5.
「本当の」初心者セッション • Rを初めて使う人のため – Rにはたくさんの可能性があるが・・・ •
最初から可能性はあえて狭めて解説 • パッケージは使わずに説明 – Rstudioを使う前提で説明 • Rを「統計ソフト」として使いたい人のため – 即戦力としてのR • 統計ソフトとしての機能以外はあえて説明しない – それ以外の活用方法についてはLTをお楽しみに
6.
Rとは • いろんなことができるソフト – 統計解析(一番得意) •
データの可視化(得意) • データの分析(得意) • データのハンドリング(だいぶ便利になった) – プログラム開発環境(それほど得意ではない) – 文書作成(機能が増えつつある) • 今日は統計解析の機能のみに注目 – だって,統計解析したいんでしょ?
7.
なぜRなのか • Rでできない統計分析はないから – 今や,多くの分野でRユーザーが増えている –
パッケージ(機能拡張)も8000を超える – 査読で求められる分析がRでしかできないということも稀にある • Rがマジョリティになってきたから – S○SSやS○Sは下火 – 共同研究者がRを使ってるなんてこともよくあること • 無償だから – 研究環境が変わっても,分析環境は同じ状態を維持できる – といっても,上の理由から仮に有償でも使うべき
8.
Rの特徴 • S○SSなどのソフトとの違い – ポチポチとマウスでボタンを押すタイプではなく, –
命令を文章で書くタイプ • STA○AやS○Sなどのソフトとの違い – プロシージャで分析法が分かれてるのではなく, – すべて関数で計算する
9.
Rの特徴 • 短所 – スペルミスすると動かない •
小文字と大文字の区別もある – 日本語に対応してくれない場合がある • 長所 – 一度書いたコードは使いまわせる • ポチポチと押し続けなくていい – 分析の手順が記録される • 昔にやった分析を簡単に再現できる
10.
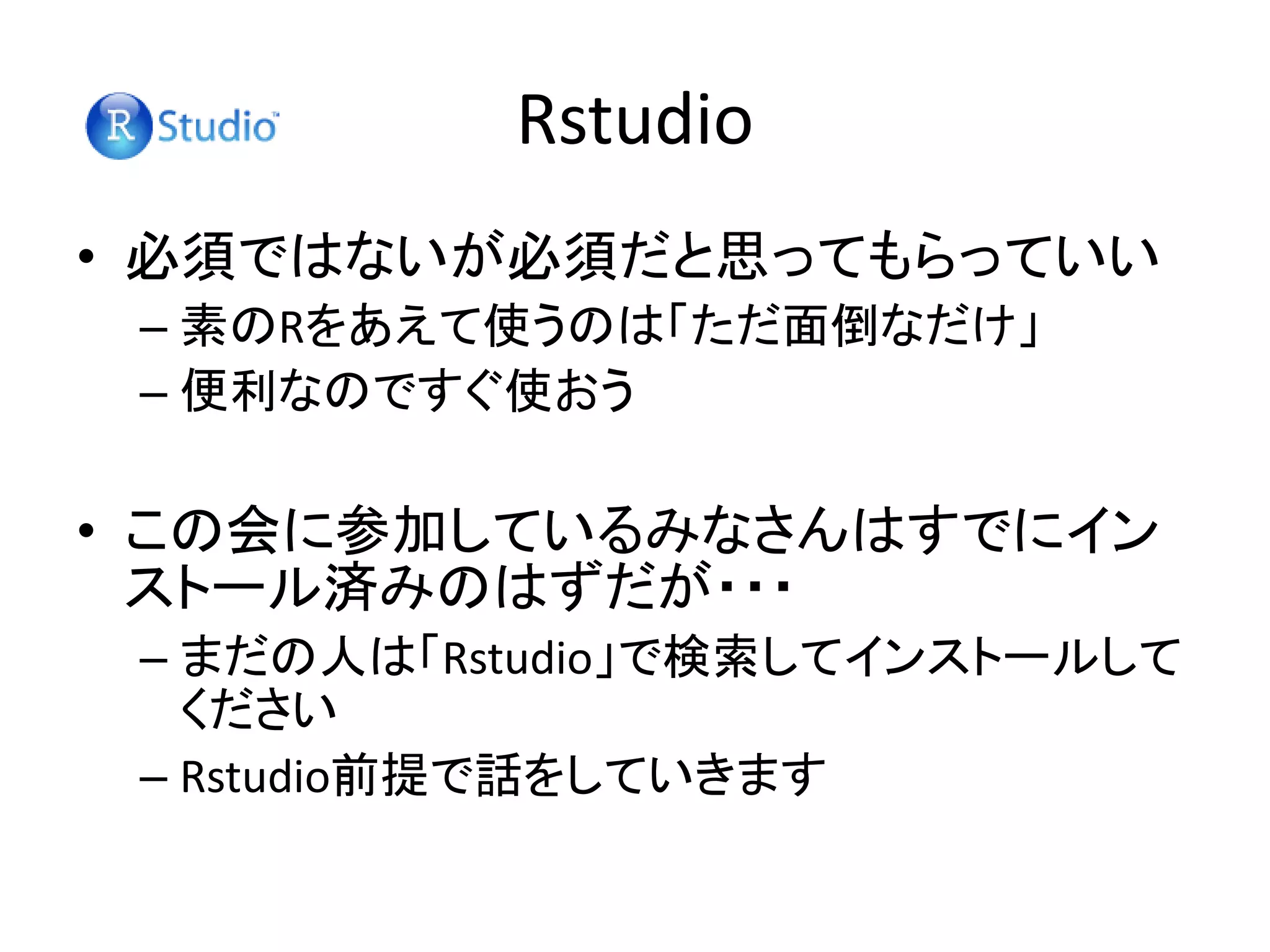
Rstudio • Rを便利に使えるようにするインターフェース – Rはそのままだと若干使いづらい –
それを便利に使えるようにしてくれるソフト • 無償,自由 – Rと同様,無償で使える
11.
Rstudio • 必須ではないが必須だと思ってもらっていい – 素のRをあえて使うのは「ただ面倒なだけ」 –
便利なのですぐ使おう • この会に参加しているみなさんはすでにイン ストール済みのはずだが・・・ – まだの人は「Rstudio」で検索してインストールして ください – Rstudio前提で話をしていきます
12.
Rstudioの便利機能 • 一部GUI搭載 – データの読み込みなどはGUIで可能 –
パッケージのインストールも簡単 • コード補完機能 – コードを予測したり,引数リストを出してくれたり • 超便利 • 関数や変数の管理も簡単 – 新しく作った変数やデータセットをリストにしてくれる
13.
Rstudioの画面 コードを書くところ 結果・出力が出るところ 変数や関数の管理 履歴の確認ができる ファイルの管理 パッケージの管理 図表の出力
14.
Rstudioを起動しよう!
15.
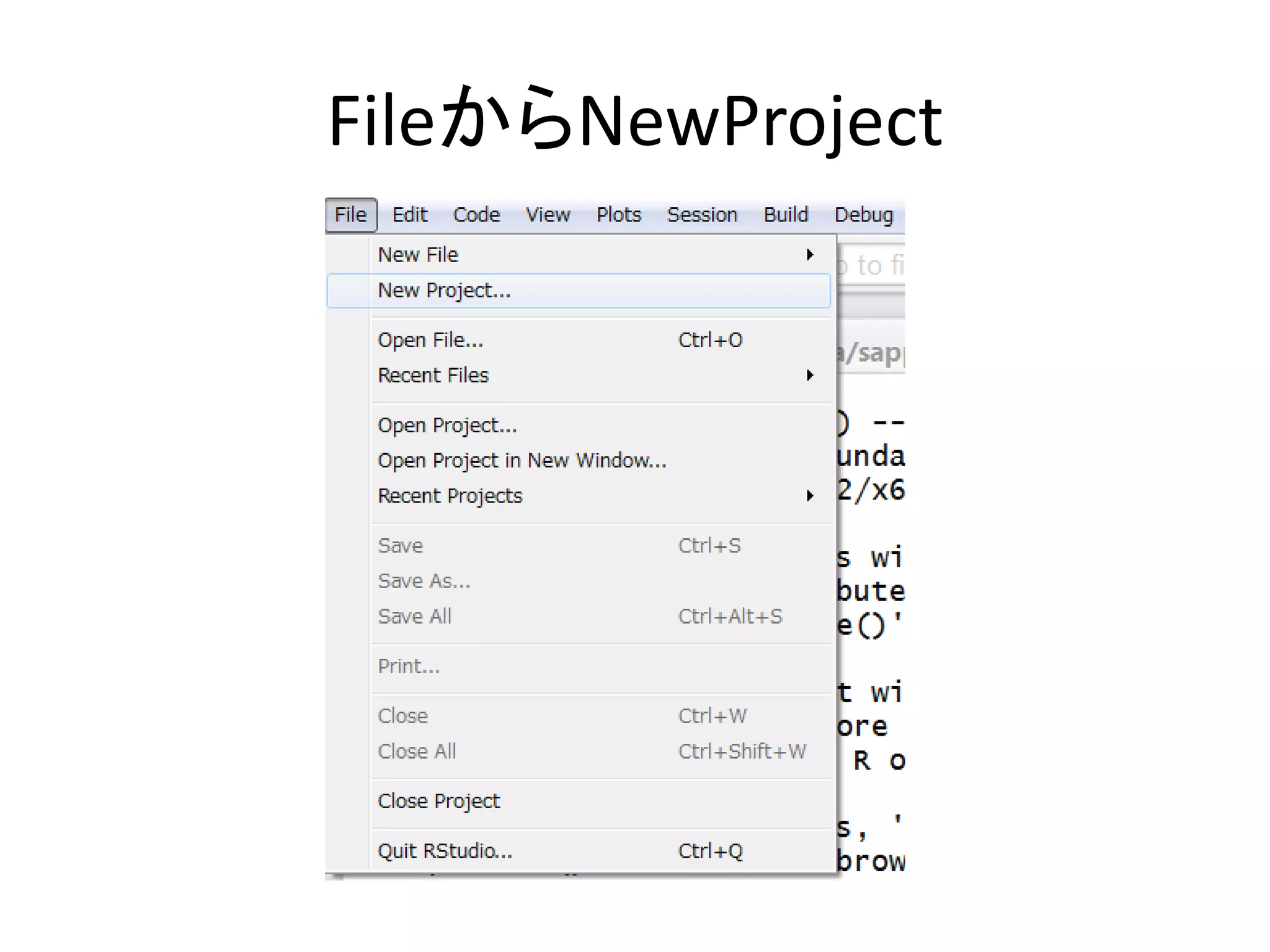
まずはプロジェクトを作る • プロジェクトとは – Rで分析するときの環境の単位 –
SPSSでいうと,savファイルみたいなもの • 研究(データ)ごとにプロジェクトを分ける – 一つのプロジェクトにいろんなデータや分析コード をいれておくと,管理がしづらい – 最初は,「R練習用」プロジェクトとかを作っておい てもいいかも
16.
FileからNewProject
17.
New Directory
18.
Empty Project
19.
Directoryの名前を決める
20.
ディレクトリ • フォルダのこと – フォルダにプロジェクト用のファイルを保存 •
パス – フォルダの住所のこと – WindowsならC:¥Users¥・・・ みたいなやつ • パスに日本語が入らないフォルダを作る – Rさんは外国製なので日本語よくわからない – Windowsユーザーで,ユーザー名が日本語の場合 は,Cドライブ直下においておけば大丈夫
21.
プロジェクトを作ったら・・・ • Rスクリプトを開こう
22.
ででーん
23.
スクリプトファイルを保存 • File→Save As… –
名前をつけて保存 • 拡張子は.R
24.
これで準備OK! • 家でRを分析するときは・・・ – このプロセスをもう一度やってください –
プロジェクト作るの忘れると,あとで絶対に混乱す るので,必ず自分でもう一度やること! • 別のPCでも環境を作るときもプロジェクト作成 – あまりやらないから忘れがち – まずは環境づくりから
25.
Rを触ってみる
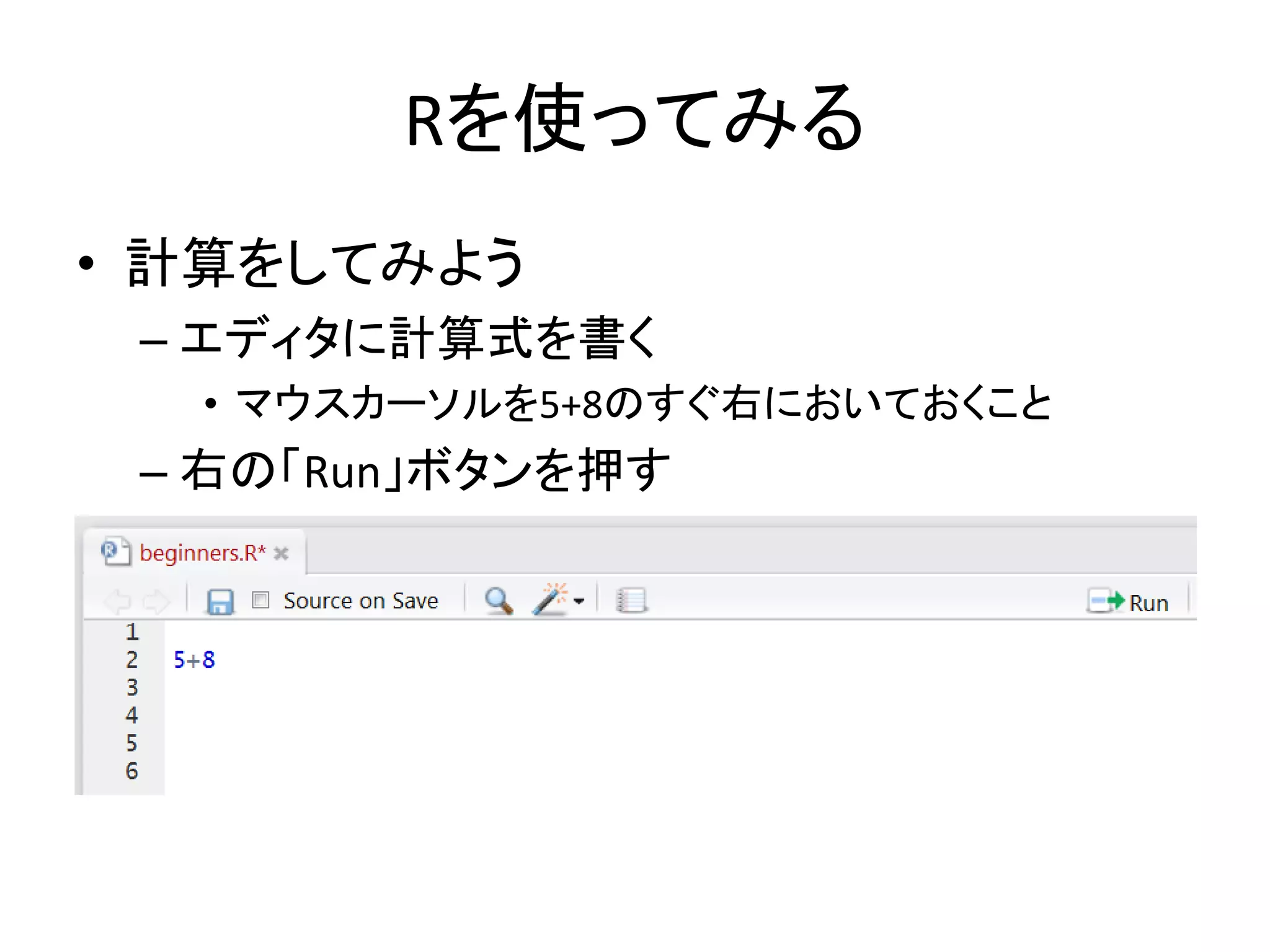
26.
Rを使ってみる • 計算をしてみよう – エディタに計算式を書く •
マウスカーソルを5+8のすぐ右においておくこと – 右の「Run」ボタンを押す
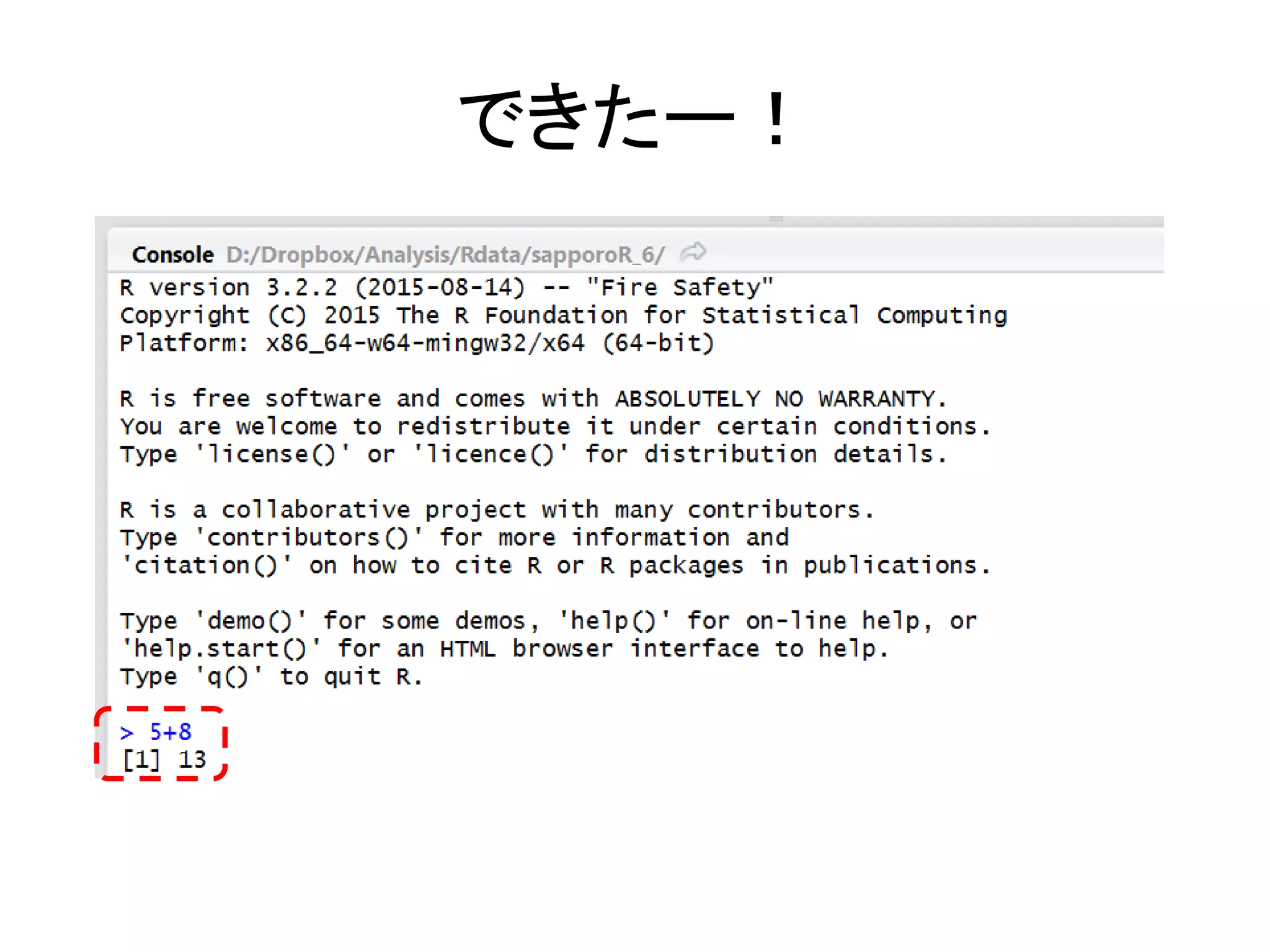
27.
できたー!
28.
四則演算 • 複数行を走らせる
29.
Rstudioの基本的な使いかた • エディタにコードを書く – 書き方はいまから勉強します –
Tabキーを打つと,コードの補完機能を使える • コードを「Run」で実行する – Ctrl+EnterでもOK • 複数行を一度に走らせたい場合は走らせたい行をドラッグ してCtrl+Enter – するとRにコードが送られて,Rが処理 – 結果をコンソールに出力
30.
変数を使う • 変数 – いろんな数字や文字列が入る箱 •
変数に数字を代入してみる – 代入は”<-” を使う(不等号の”<“とマイナスの”-”) • 代入した変数の中身を呼び出す
31.
変数を使う • 変数も四則演算 • 変数の計算結果を別の変数に格納 •
変数同士の計算ももちろん可能
32.
関数を使う • 平方根の関数sqrt()を使う • 変数にももちろん使える •
足し算の関数sum()も使ってみる
33.
Rで統計解析(の予備知識)
34.
Rって電卓なの? • いやいや,統計ソフトです – わかります,まだ統計ソフト感ないですよね •
というわけで,データセットを使いたい – サンプルデータがRの中にあるので,それを使っ て統計分析をしていきましょう
35.
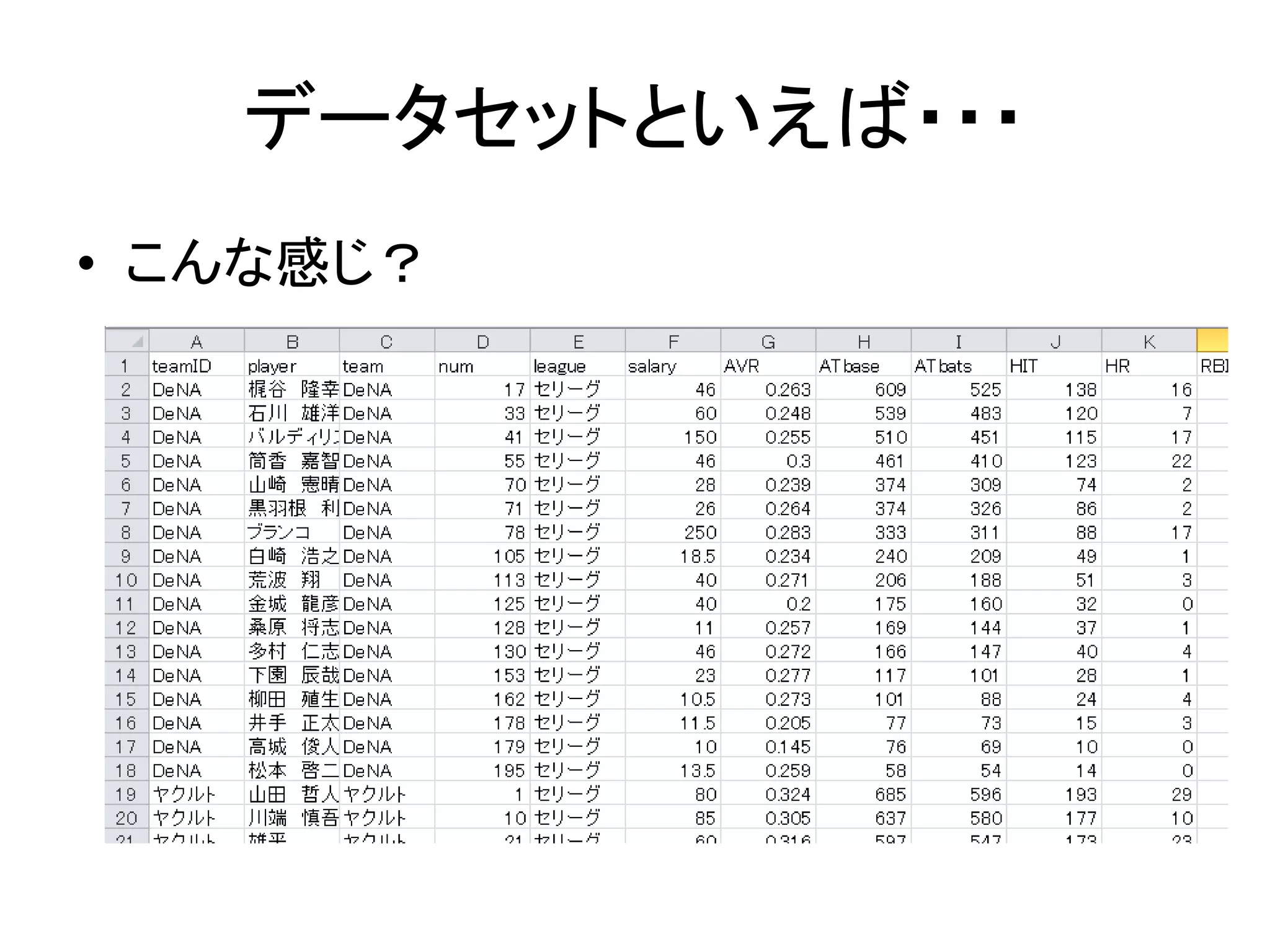
データセットといえば・・・ • こんな感じ?
36.
S○SSでは・・・ • 一つのファイルにデータセットは1つ – そのデータセットに変数を追加していくイメージ •
Rでは・・・ – データセットも「大きな変数」と考える – このあたりのイメージが結構違うので注意
37.
irisデータ • あやめのデータ – 3種類のあやめの花弁や萼片の長さ,幅につい てのデータ •
irisで呼び出せる – Rに最初から入ってる – head(iris)と書いてみよう
38.
head(iris) • 最初の6個のデータだけを表示する関数 – このように,5つの変数で構成されている –
データの数は150
39.
データセットを使うこなすには・・・ • Rの「変数」についての知識が必要 – 変数の型と構造 –
今回は型は説明を省く • 変数の構造にもいくつか種類がある – 変数は1つの数字だけが入るわけではない • SPSSでは標本の大きさ分だけの数があつまって一つ の変数を形成する – Rにおける変数の構造の種類を説明
40.
変数の構造の種類 • ベクトル: vector –
数値が複数並んだもの • 数値が一つだけでもベクトル扱い • 行列: matrix – ベクトルが多次元になったもの • 行と列で要素を指定する • リスト: list – 複数の変数が集まったもの これも変数だけど • データフレーム: data.frame – 複数のベクトルが集まったもの – Rにおけるデータセットとは,このデータフレームのこと
41.
変数の構造をチェック • is.vector()でベクトルかどうかがわかる – ベクトルらしい •
is.matrix()で行列かどうかがわかる – 行列じゃないらしい
42.
ベクトル • 一番よく使う – 普通の統計ソフトにおける「変数」がこれ •
複数の参加者が回答した値の集合 • 複数の数値をまとめてベクトルにしたい場合 – c()を使う
43.
行列 • 行列演算をしたい場合に使うが・・・ – 単なる統計ソフトとして使うなら出番は少ない •
複数の数値を行列にしたい場合 – matrix()を使う 最初にベクトルを入れて, そのあと行,列の数を指 定する
44.
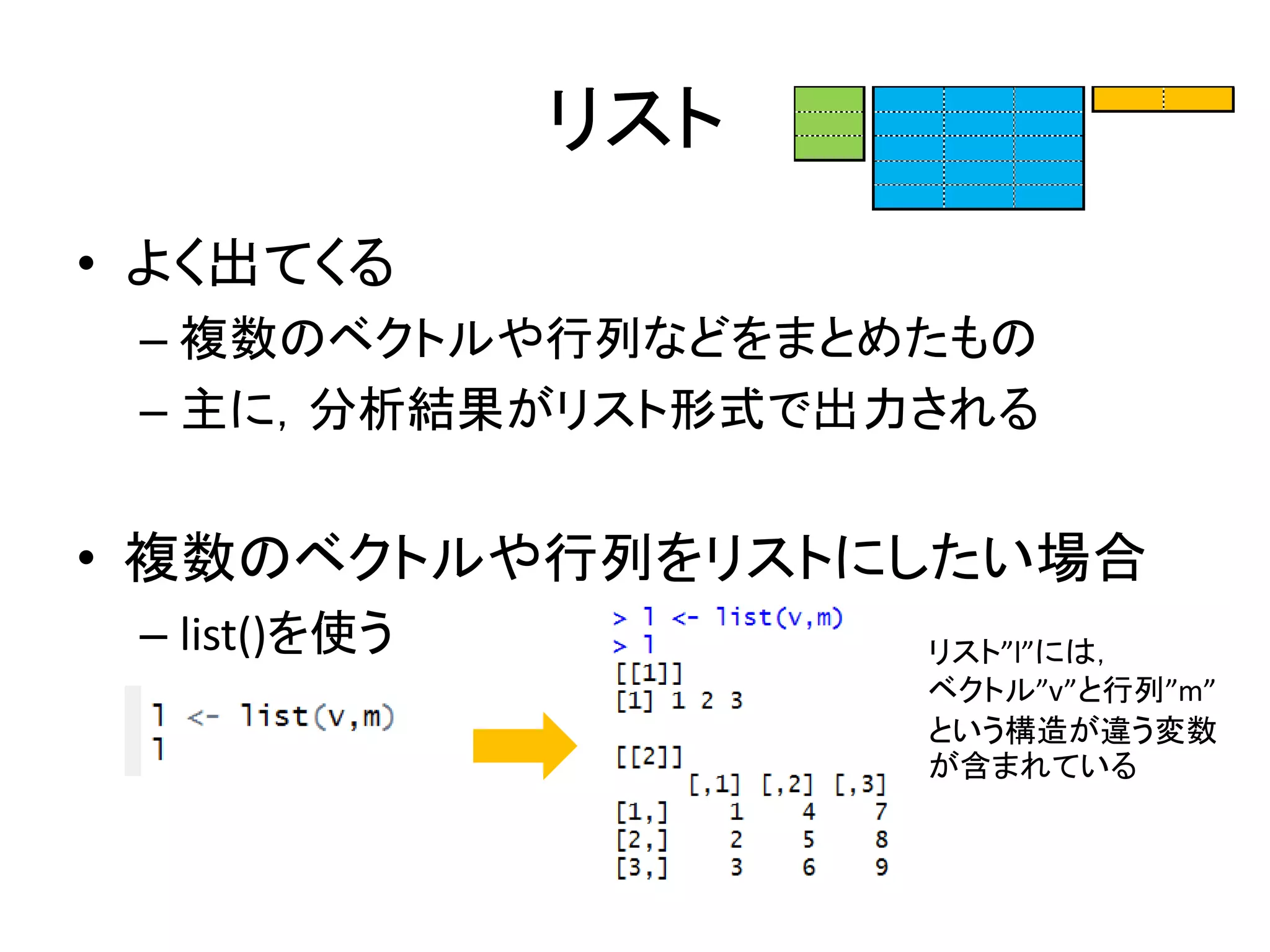
リスト • よく出てくる – 複数のベクトルや行列などをまとめたもの –
主に,分析結果がリスト形式で出力される • 複数のベクトルや行列をリストにしたい場合 – list()を使う リスト”l”には, ベクトル”v”と行列”m” という構造が違う変数 が含まれている
45.
データフレーム • データセットとして使う – 要素数が等しい複数のベクトルをまとめたもの –
分析するデータはこの構造で扱う • 複数の変数をデータフレームにしたい場合 – data.frame()を使う ベクトルが縦に並ぶ
46.
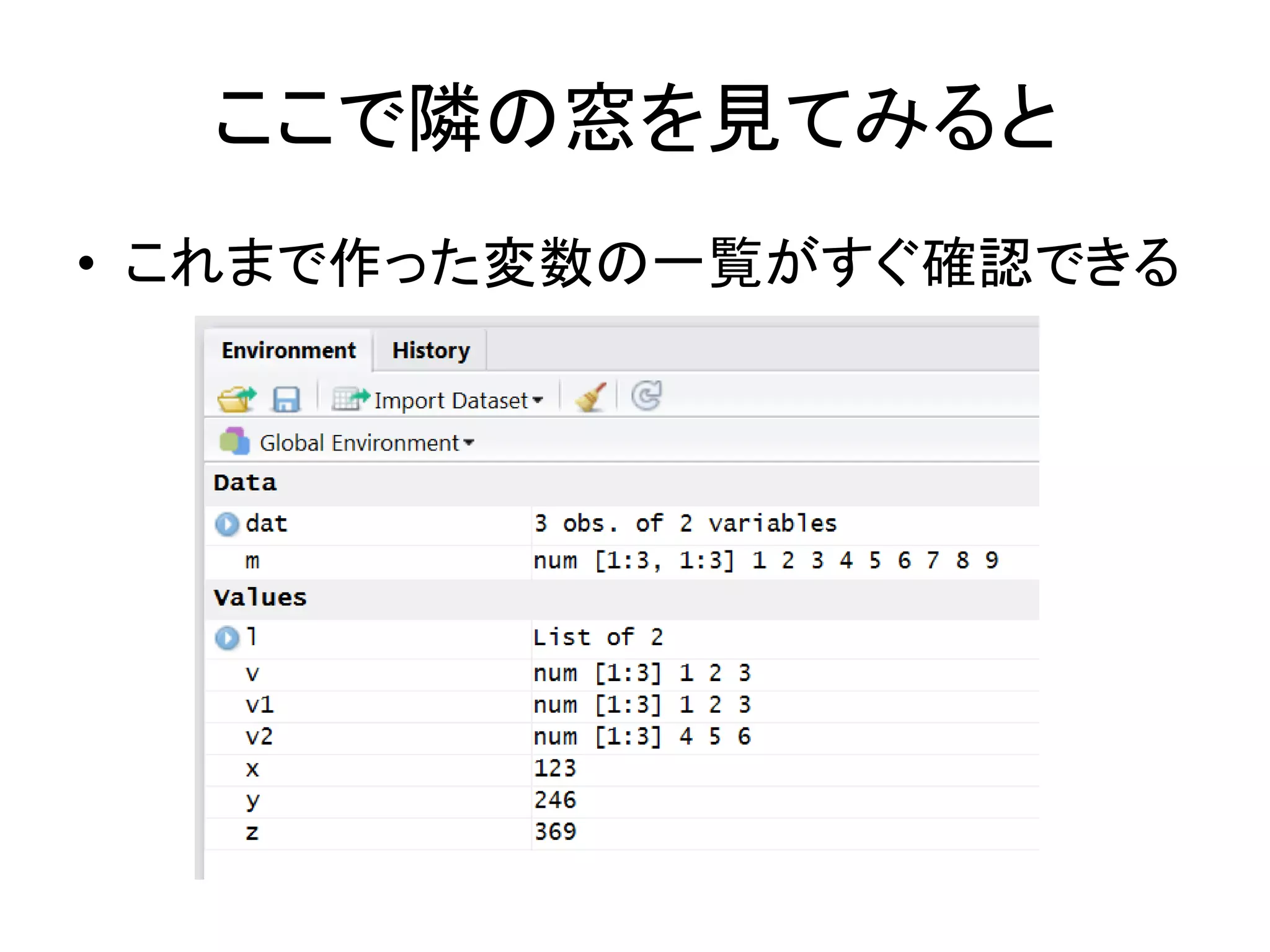
ここで隣の窓を見てみると • これまで作った変数の一覧がすぐ確認できる
47.
irisはデータフレーム • 確認してみよう • データフレーム=複数の変数(ベクトル) –
変数を指定して取り出したい場合 – $マークを使う Rstudioなら$と打ったら自動的 に中の変数がリスト表示される
48.
$以外にも様々な指定方法がある • 1列目を選択 • 2列目から4列目を選択 •
5列目だけ省く
49.
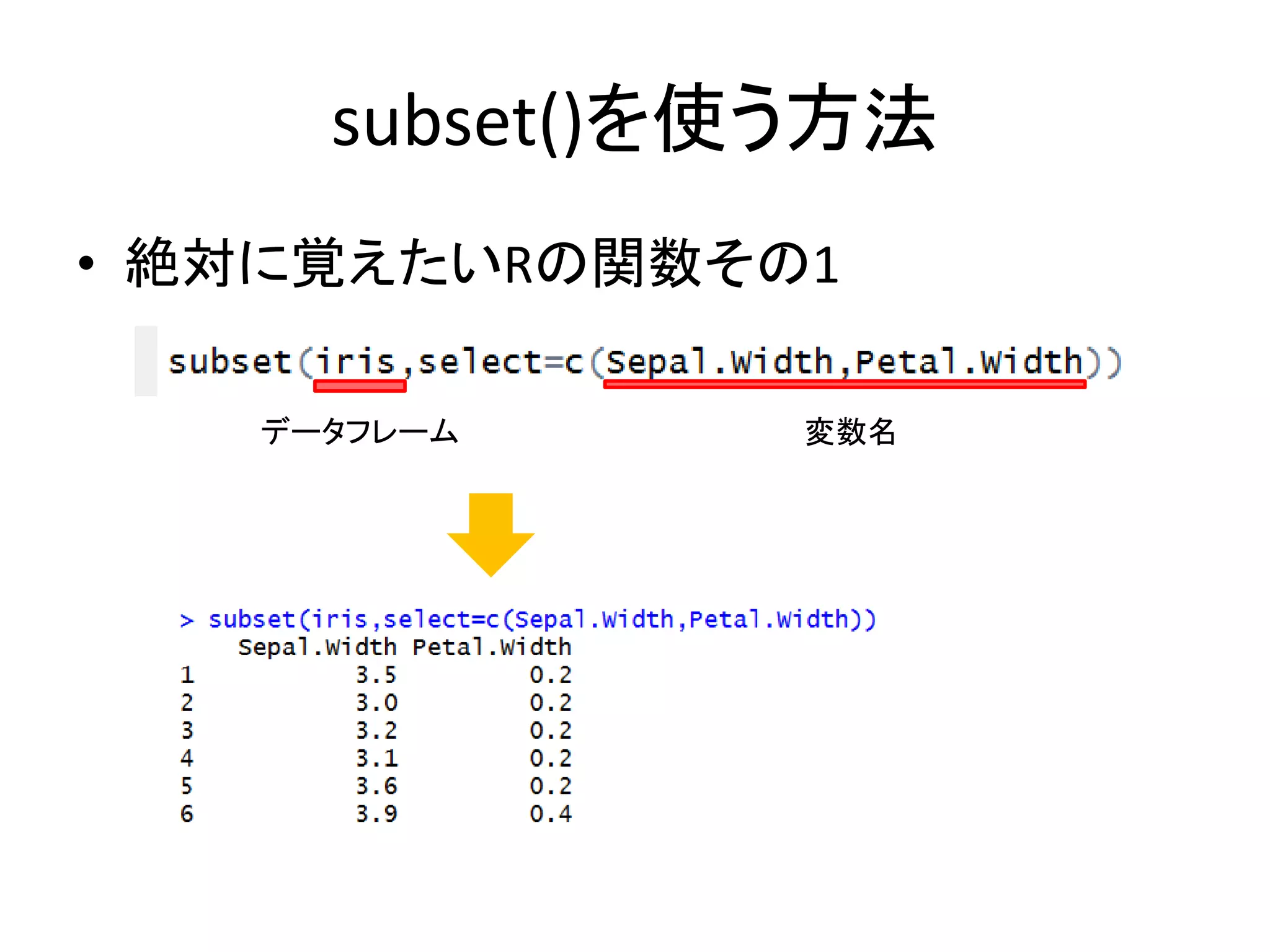
subset()を使う方法 • 絶対に覚えたいRの関数その1 データフレーム 変数名
50.
Rで統計分析
51.
新しいデータフレームに移動 • 分析データセットは別に作る(オススメ) – ローデータと分析用データは分けておく –
処理でミスっても,最初からやり直せる • datにirisを代入
52.
要約統計量の計算 • 変数の全体的な要約をしたい – summary()を使う
53.
要約統計量の計算 • 変数の平均値が知りたい – mean()を使う •
変数の標準偏差が知りたい – sd()を使う
54.
注意! • データに欠損値がある場合 – NAが返ってくる –
「NA」はRの欠損値を意味する文字列 • 常に”na.rm=TRUE”を入れることをオススメ
55.
複数の変数の平均値を計算したい • apply()を使う – 絶対に覚えたいRの関数その2 –
ベクトルを引数にして,一つの数値を返す関数を 複数のベクトルに適用する関数 • mean(),sd(),sum()など,ベクトルを入れて,一つの値が 返ってくる関数で使える データフレーム 関数名 2番めの引数は,行に適用したい場合 は1,列に適用したい場合は2を入力 する
56.
群ごとの平均値を計算したい • tapply()を使う 平均値を計算 したい変数 変数は1つだけ 群分けしたい 変数 関数名
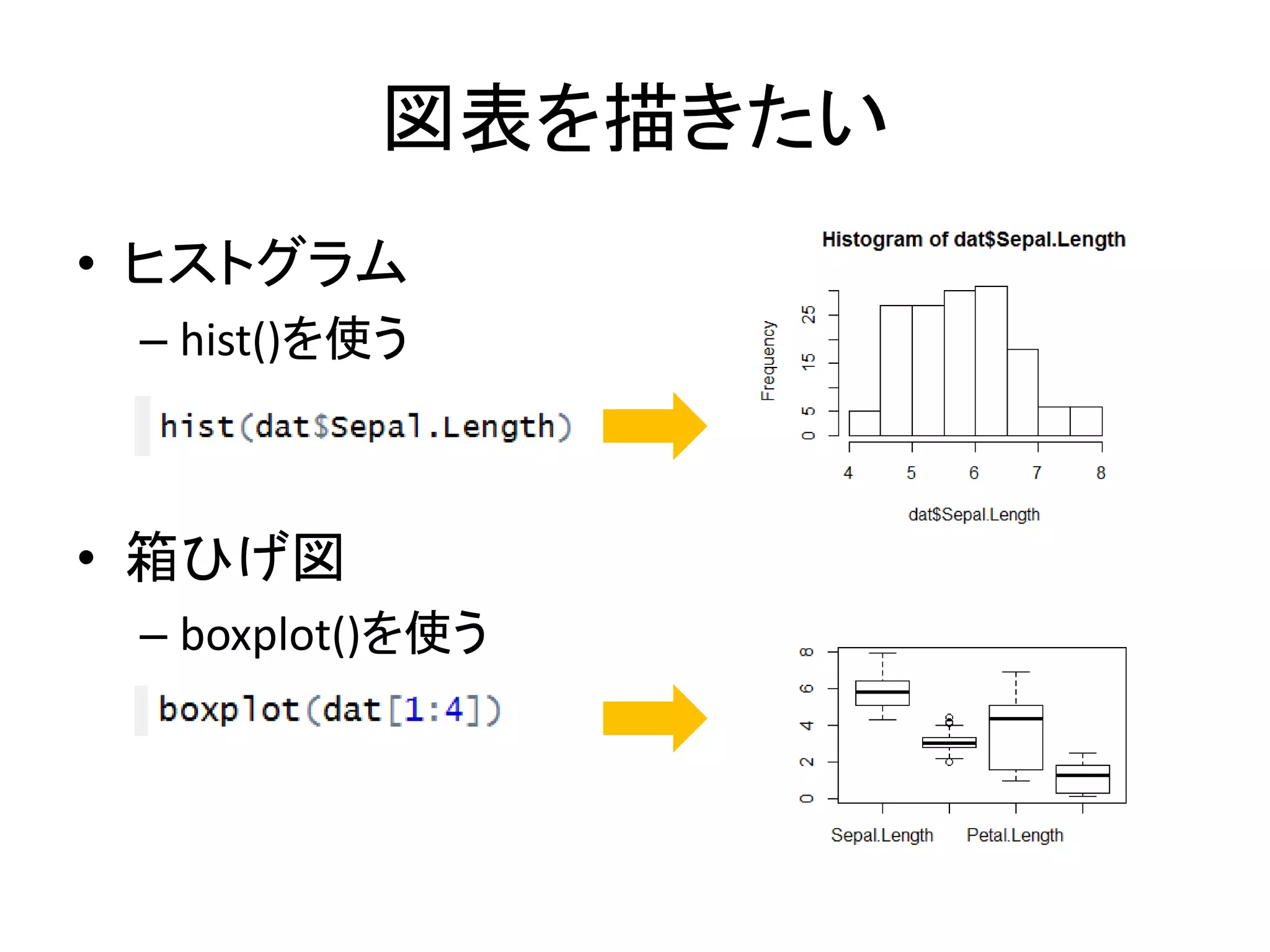
57.
図表を描きたい • ヒストグラム – hist()を使う •
箱ひげ図 – boxplot()を使う
58.
図表を描きたい • 群分けして棒グラフ – tapply()とbarplot()を使う •
各変数を棒グラフ – apply()とbarplot()を使う
59.
図表を描きたい • 散布図 – plot()を使う •
散布図を群ごとに描く – plot() を使う
60.
もっと気の利いた図表を! http://www.slideshare.net/nocchi_airport/ggplot2-kazutan-rver2
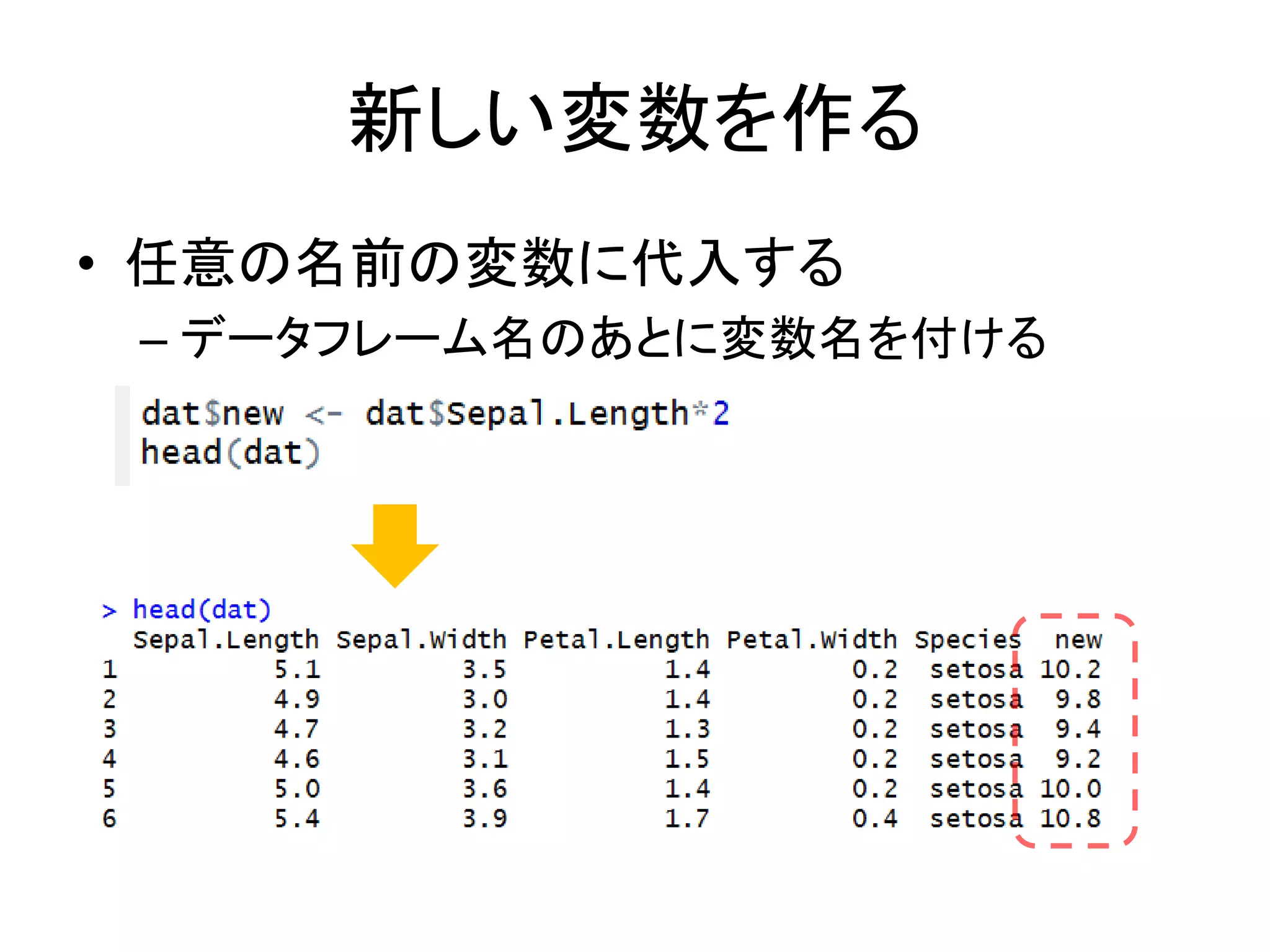
61.
新しい変数を作る • 任意の名前の変数に代入する – データフレーム名のあとに変数名を付ける
62.
関数を使って変数を作る • 複数の変数の平均を,新しい変数にする
63.
一部のサブジェクトだけ取り出す • 条件文を使う方法 – []に条件文を書いて,フィルターにする ==は等号を意味する
64.
一部のサブジェクトだけ取り出す • 再びsubset()が登場 – 種がバージニカのデータを全部取り出したい Speciesが“virginica”のデータの みを取り出している
65.
データセットの扱い
66.
データセットの出力 • write.csv()を使う – row.names=FALSEは必須ではないが,今回はこう しておく •
あとで読み込み直すときに問題が生じない データセットを保存するファイル名 拡張子は”.csv”じゃないと上手くいかない
67.
ちゃんと出力されてる • ででーん
68.
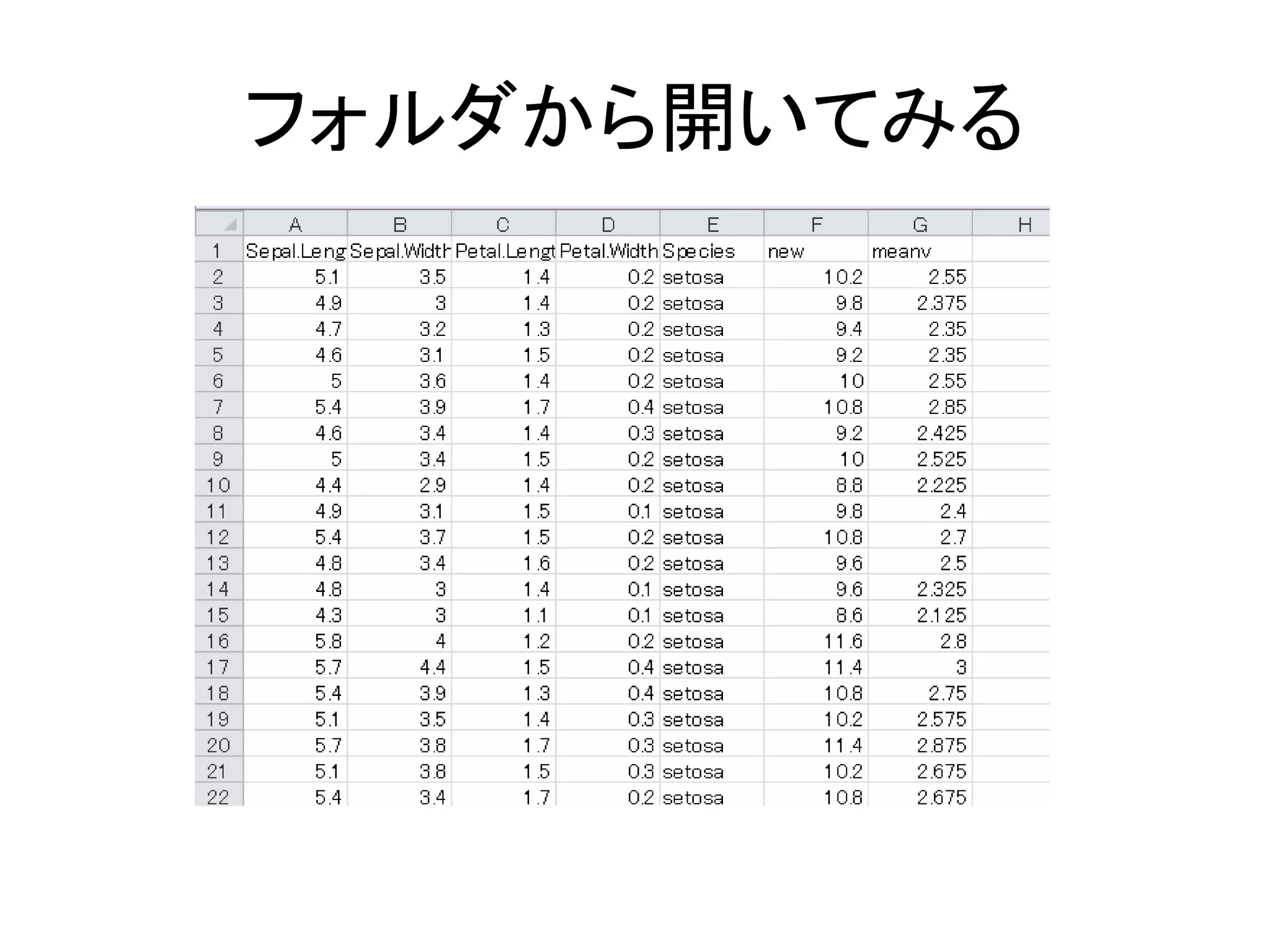
フォルダから開いてみる
69.
csvファイルとは • comma-separated values –
カンマ区切りのテキストデータ – 書式などの余分な情報がないので軽く,汎用的 に使えるファイル形式 • Rを使うときはcsvファイルを使いこなそう! – データはcsvファイルで保存 – Rにcsvファイルを読みこませる
70.
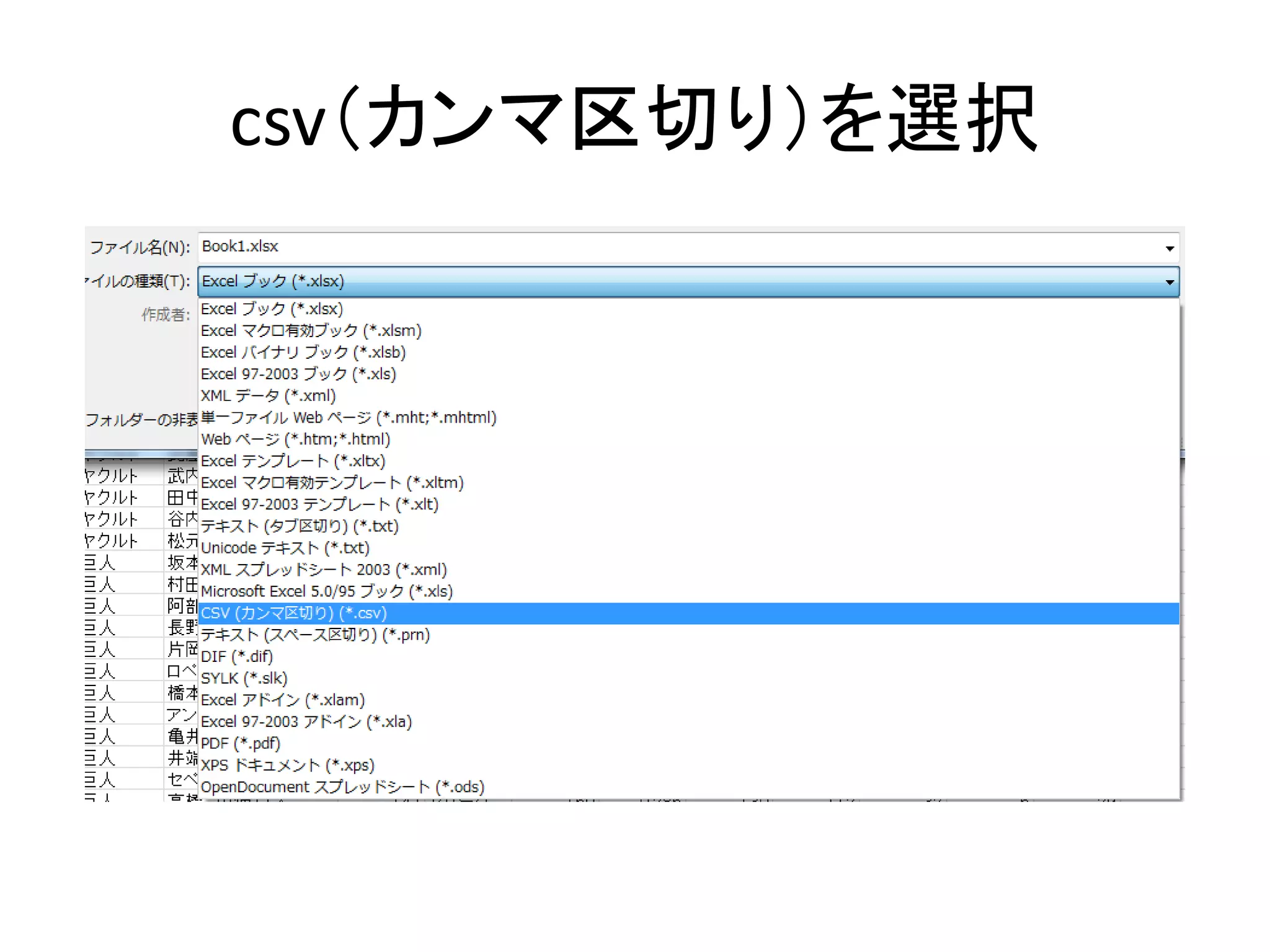
csvファイルの作成方法 • Windowsの場合(しか知らない) – Excelにデータを入れる •
シートは1つだけ使う – 名前をつけて保存 • ファイルの種類を選択 – 「csv(カンマ区切り)(*.csv)」 を選択 – 下のウィンドウが出てきたらOK
71.
csv(カンマ区切り)を選択
72.
データセットの読み込み • read.csv()を使う – 絶対に覚えたいRの関数その3
73.
データセットの読み込み • 欠損値をNAに変換するには・・・ – たとえば欠損値がピリオド”.”の場合 –
こうすると,ピリオド”.”がNAに変換されてデータ セットを読み込むができる
74.
RstudioのGUIからも可能 • Tools→Import Dataset→From
Text File
75.
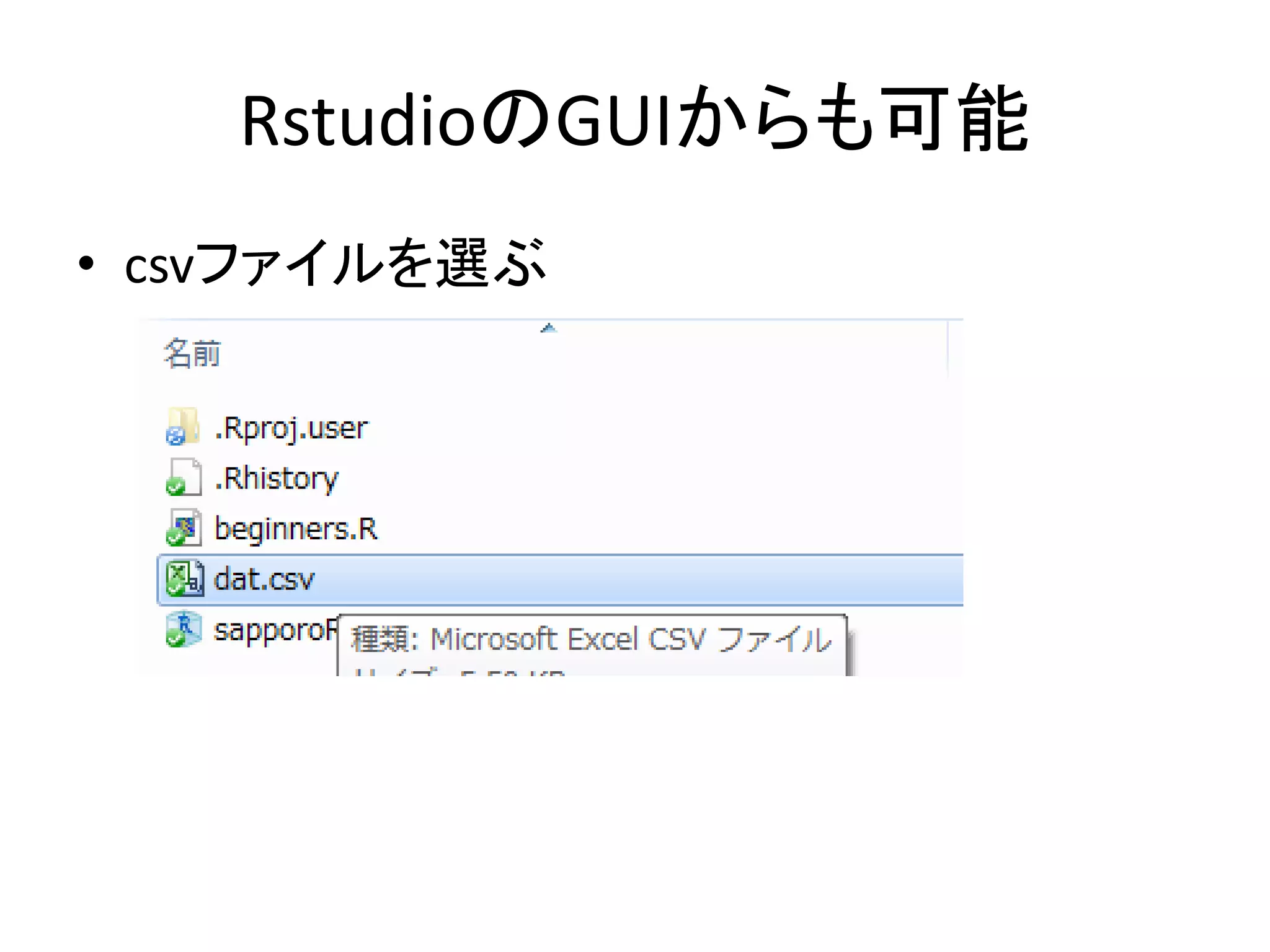
RstudioのGUIからも可能 • csvファイルを選ぶ
76.
RstudioのGUIからも可能
77.
RstudioのGUIからも可能 • ででーん
78.
もっとRで統計分析
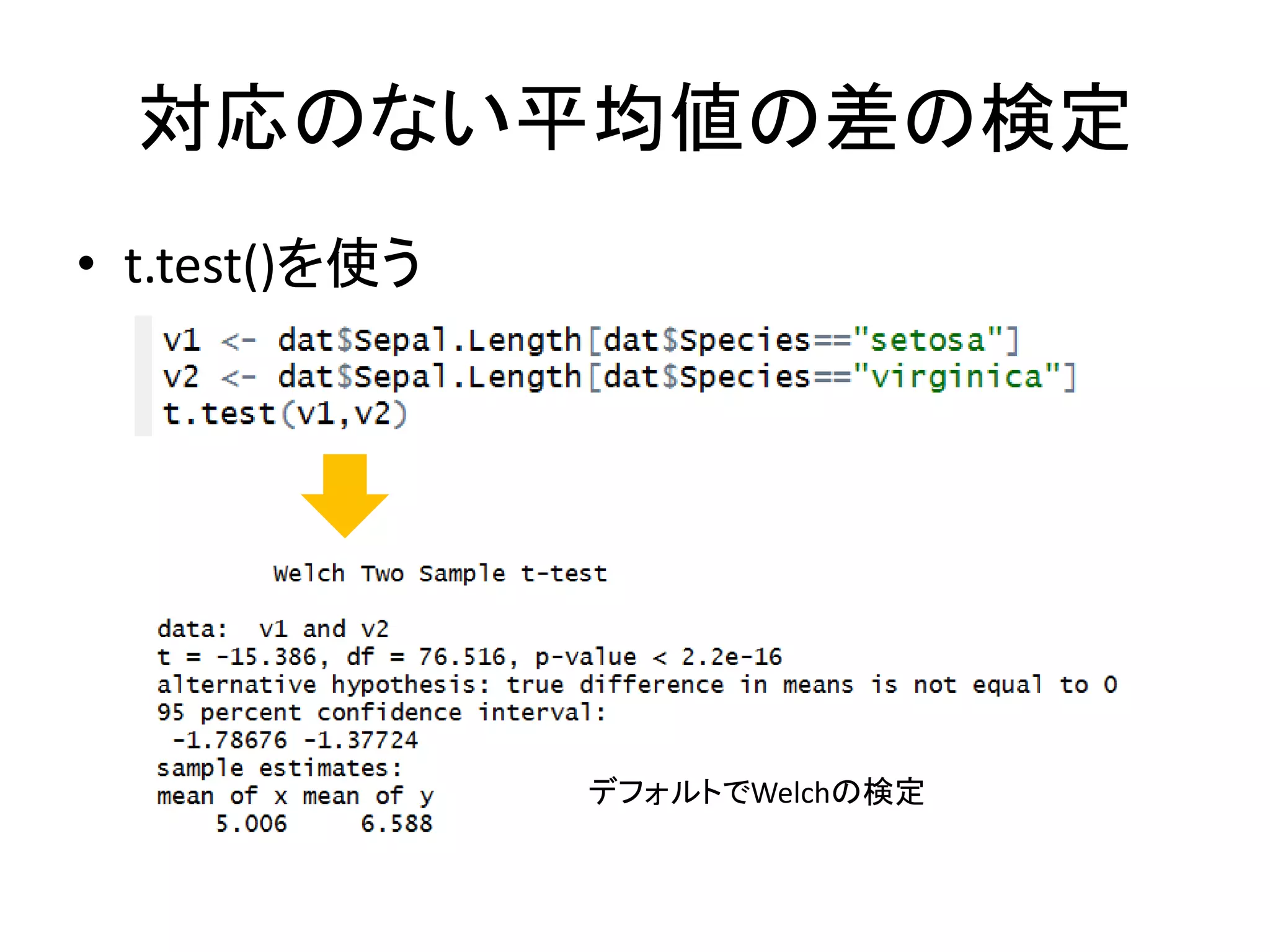
79.
対応のない平均値の差の検定 • t.test()を使う デフォルトでWelchの検定
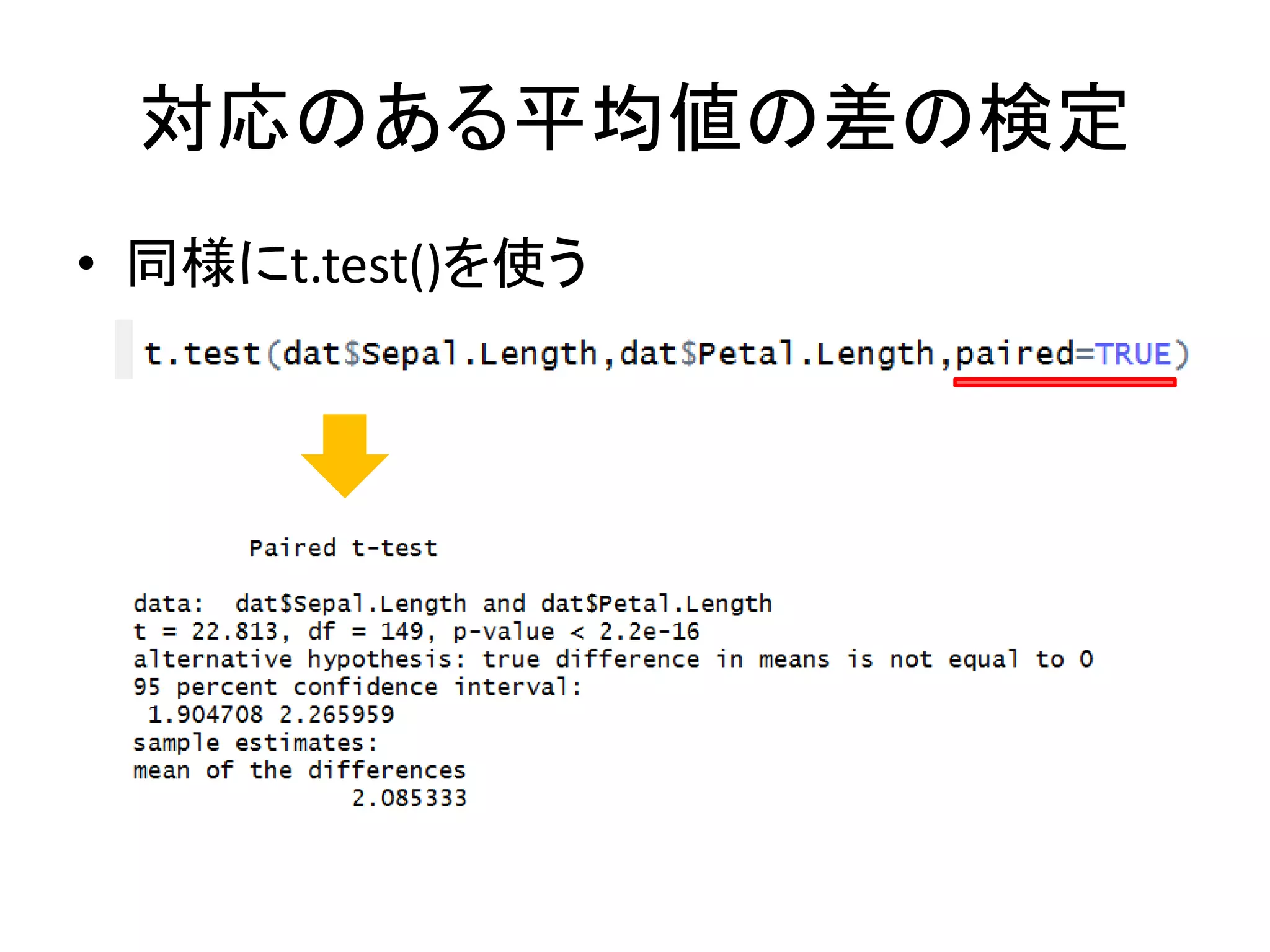
80.
対応のある平均値の差の検定 • 同様にt.test()を使う
81.
相関係数 • cor()を使う • 検定はcor.test()を使う
82.
回帰分析 • lm()を使う – モデルは •
目的変数~説明変数1+説明変数2+・・・ – チルダ”~”で結ぶ • 多くの線形モデルの関数で共通の書き方 • 分析結果をresultに格納 – resultはリスト型になっている モデルを指定 データフレーム
83.
分析結果の見方 • summary()を使う
84.
summary() • 要約するための関数 – データフレームを引数にすると要約統計量 •
分析関数の出力リストを引数にすると・・・ – 分析結果の要約が出力される – 多くの分析用関数の出力は,summary()で結果を 知ることができる
85.
出力の中身を確認する • str()を使う – リストの構造を知ることができる
86.
回帰係数だけ取り出す • coefficientsを取り出す
87.
回帰直線を散布図に引く • plot()とablin()を使う 散布図は引数の順番が説明変数 が最初,目的変数が後なので注意
88.
クラスタ分析 • 階層クラスタ – hclust()を使う
89.
クラスタ分析 • 非階層クラスタ – kmeans()を使う
90.
クロス表の分析 • クロス表を作る – table()を使う
91.
独立性の検定 • χ2乗検定 – chisq.test()を使う
92.
もっともっとRで統計分析
93.
パッケージ • Rの機能拡張 – ユーザーが作った関数のセットのこと •
世界中のいろんな人がパッケージを作ってる • 8000以上のパッケージが君を待っている! • インターネットからダウンロードできる – install.packages()を使う
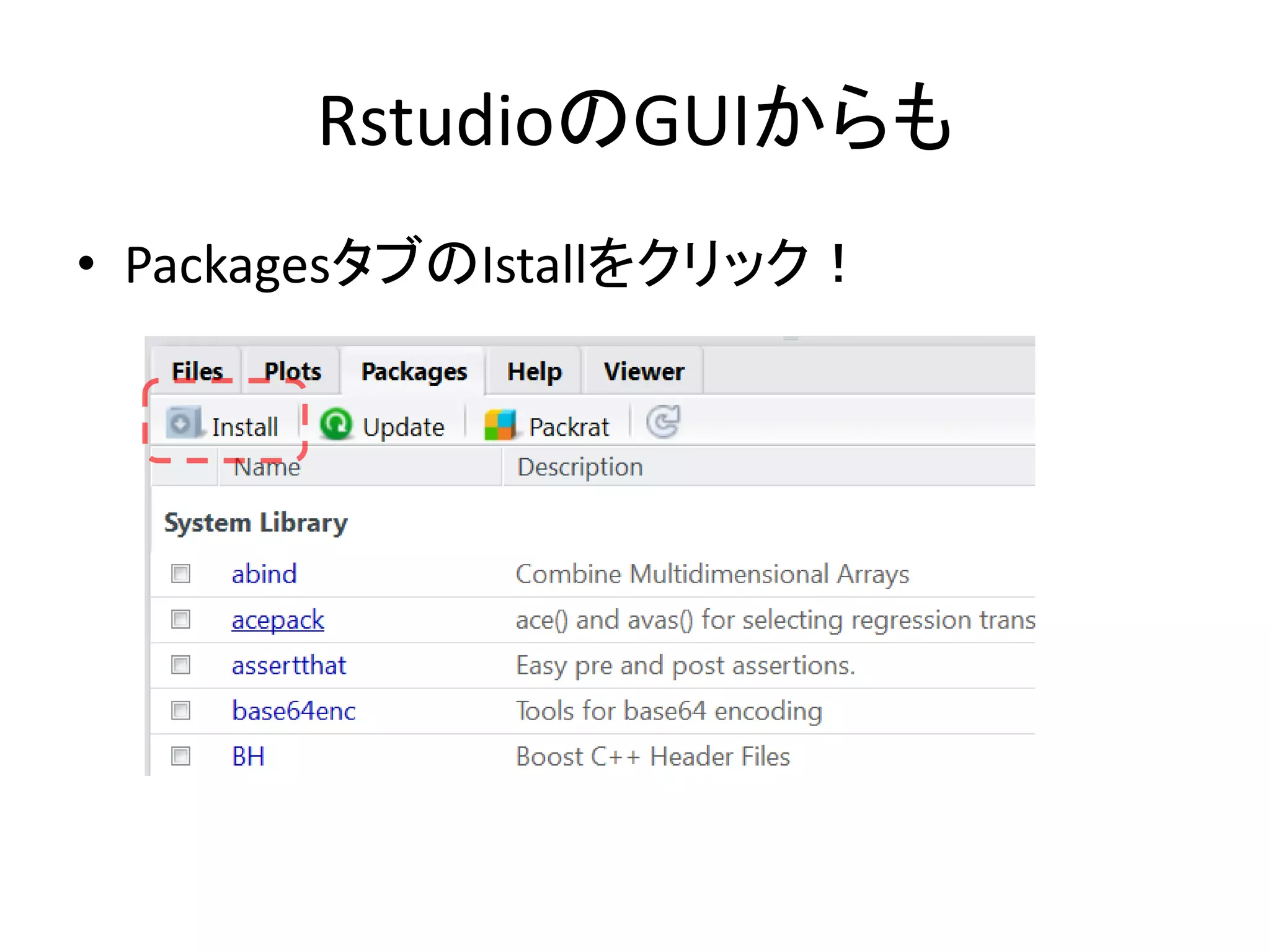
94.
RstudioのGUIからも • PackagesタブのIstallをクリック!
95.
RstudioのGUIからも
96.
パッケージを使うには • library()を使う
97.
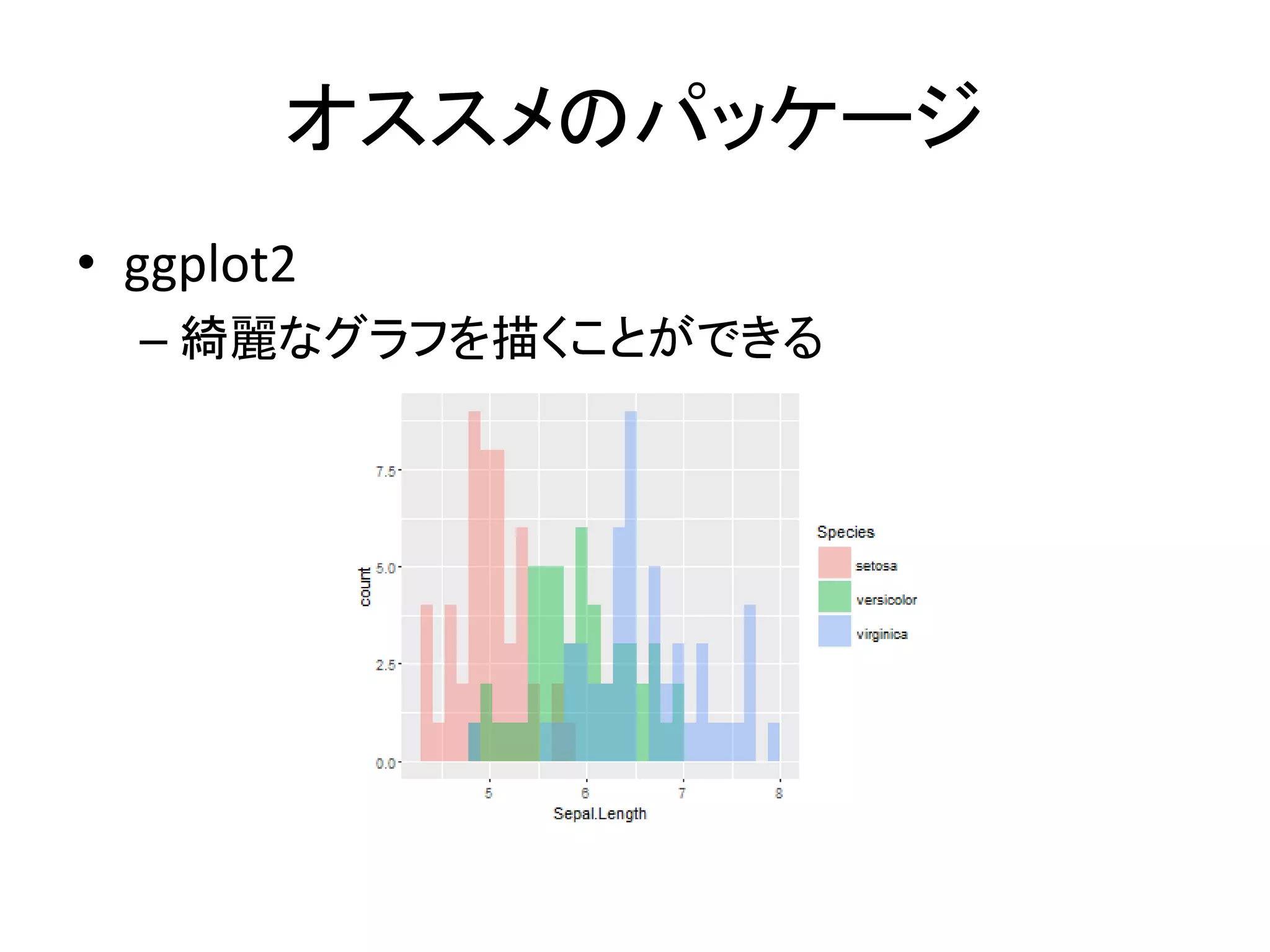
オススメのパッケージ • ggplot2 – 綺麗なグラフを描くことができる
98.
オススメのパッケージ • dplyr – データハンドリングを飛躍的に便利にする –
フィルタ,並び替え,グループ別処理などなど • pforeach – とても簡単に繰り返し処理を並列化してくれる • rstan – MCMC(*´Д`)ハァハァ
99.
分析別パッケージ • 心理統計 – psychパッケージ •
一般化線形混合モデル – lme4パッケージ • ベイズ推定 – rstan
100.
Rでわからないことがあったら
101.
Webで調べよう • 最近はググラビリティも高くなってきた – 「R
グラフ 描き方」とかで検索する • R-Tipsも便利 – http://cse.naro.affrc.go.jp/takezawa/r-tips/r.html • Rに関するブログ記事も豊富 – ぞうさん通信(http://blog.kz-md.net) • R関連の記事をまとめてくれている
102.
ぞうさん通信
103.
人に聞いてみよう • Twitterで次の呪文を唱えると答えが返ってくる
104.
よくある質問
105.
Rではどんな分析ができるの? • 全部 • 膨大な量のパッケージ •
なによりrstanがある • なかったら自分で書けばいい
106.
Rでコピペばっかだと意味ない? • そんなことはない – 最初は誰でもコピペだった –
英語の勉強も最初は音読・復唱するのと同じ • 自分の分析に合わせてちょっとずついじる – するとだんだんわかってくる
107.
コードがあってるか不安 • 複数のソフトで確認しよう – SP○Sを捨てる必要はない •
触りたくないなら無理にとは言わない – むしろ,同じ分析をいろんなソフトで実行してみて,同 じか,違ったら何が違ったのかを考える – 分析で思考停止してはいけない • 全部Rでやる,というのもよくない – Rが使えるようになればいいだけであって,なんでも かんでもRでやる必要はない
108.
最後に • Rを勧めるのは無償だからではない – Rを使えないとこれから仕事できないから –
WordやExcelと同じようにRを覚える必要がある • 分析がさき,ツールはあと – S○SSじゃその分析できないから・・はただの怠慢 – 最適な分析があるなら,やればいい – Rはあらゆる分析手法に開かれている
109.
Enjoy! 清水裕士 関西学院大学 Web: http://norimune.net Twitter:@simizu706
Download





















































![一部のサブジェクトだけ取り出す
• 条件文を使う方法
– []に条件文を書いて,フィルターにする
==は等号を意味する](https://image.slidesharecdn.com/sapporor6beginnerssession-160709063350/75/SapporoR-6-63-2048.jpg)































































![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)








































