とは何か
• 統計処理を目的とするプログラミング言語
• 無償+オープンソースのソフトウェア
•作者:Ross Ihaka & Robert Gentleman (R & R)
• Ross Ihaka and Robert Gentleman. R: A language for data analysis and graphics.
Journal of Computational and Graphical Statistics, 5(3):299-314, 1996.
• http://biostat.mc.vanderbilt.edu/twiki/pub/Main/JeffreyHorner/JCGSR.pdf
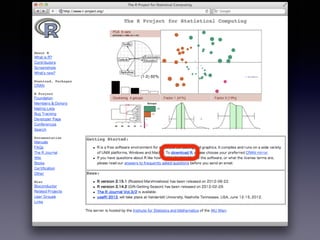
のインストール
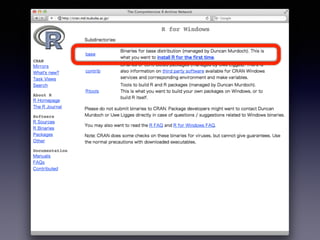
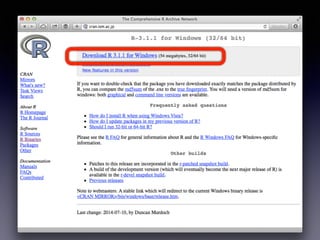
• Windows:: http://cran.ism.ac.jp/bin/windows/base/
•「Download R 3.1.1 for Windows」をクリック
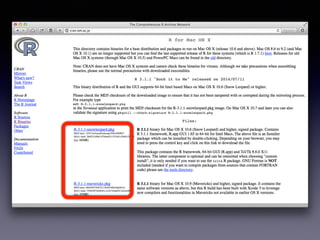
• Mac OS X:http://cran.ism.ac.jp/bin/macosx/
•「R-3.1.1-mavericks.pkg」をクリック
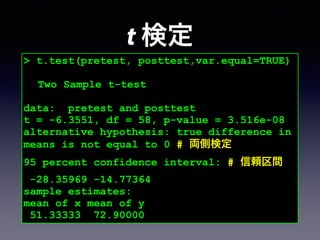
> t.test(pretest, posttest,var.equal=TRUE)
!
TwoSample t-test
!
data: pretest and posttest
t = -6.3551, df = 58, p-value = 3.516e-08
alternative hypothesis: true difference in
means is not equal to 0 # 両側検定
95 percent confidence interval: # 信頼区間
-28.35969 -14.77364
sample estimates:
mean of x mean of y
51.33333 72.90000
t 検定




































![コンソールで「+」が出たら...
• 入力中に誤って[Enter] を押すと,
待機状態を示す「+」が出る
• [STOP] ボタンでキャンセル
• [Esc] キーでキャンセル](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-48-320.jpg)
![履歴機能と補完機能
•履歴: [↑][↓] の矢印キー
•補完: [Tab]キー](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-49-320.jpg)















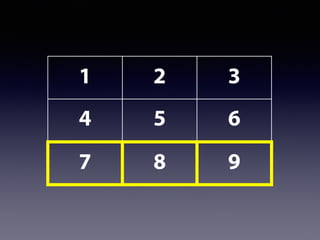









![行列の要素を取り出す
2行目を表示 → demo[2,]
2列目を表示 → demo[,2]
http://gyazo.com/6726084afd9e1cc4b03df85fe6bc0f29.png](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-80-320.jpg)
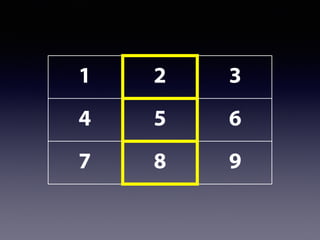
![行列の要素を取り出す
2行目と4行目を表示
→ demo[c(2,4),]
2列目と4列目を表示
→ demo[, c(2,4)]](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-81-320.jpg)




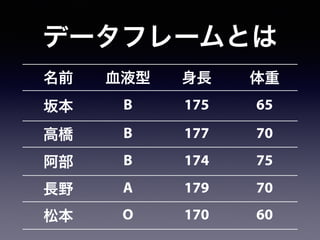










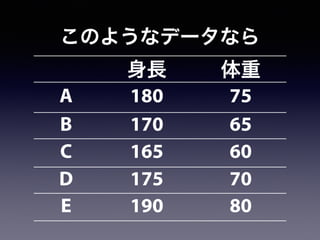
![1. let2014.csv を作業ディレクトリへ移動
• XLS/XLSX 形式のものは保存時に変換
• CSV ファイルの文字コードは UTF-8 に
2. > test <- read.csv(choose.files(), header = TRUE) #Win
# test <- read.csv(file.choose(), header = TRUE) #Mac
3.> test [Enter] で中身を確認
データの読込 その1](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-97-320.jpg)


![1.let2014.xls を開いてマウスで範囲指定
2.> test2 <- read.delim("clipboard") で代入
!
3.> test2 [Enter] で中身を確認
データの読込 その2
Mac の場合: read.delim(pipe("pbpaste"))](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-100-320.jpg)
![読み込んだら関数で処理
> table(test[,3])
•度数分布を確認する
> mean(test[,3])
•平均値を求める
3列目対象
3列目対象](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-101-320.jpg)















![今度は折れ線グラフ
> quiz <- test[,c(3,4,5,6,7,8,9,10,11,12)]
# 小テストの得点だけを取り出す
> ID1<- as.numeric(quiz[2,])
# データの型変換(リストから数値へ)
> plot(ID1, type="l")
# 引数 type を l にして折れ線グラフに](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-117-320.jpg)




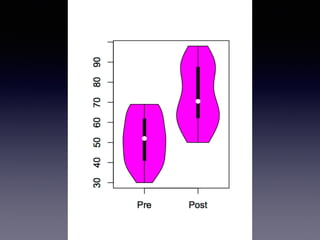
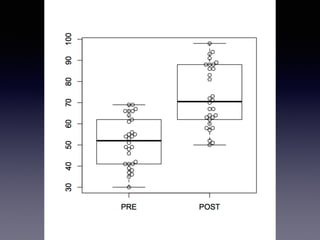
![boxplot + beeswarm
> install.packages("beeswarm")
> library("beeswarm")
> PrePost <- test[,c("Pre",“Post")]
> boxplot(pretest, posttest, names=c("PRE", "POST"))
> beeswarm(PrePost, add=TRUE)](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-123-320.jpg)












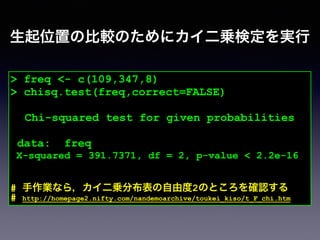
![事例: 接続詞“however”の生起位置の比較
文頭 文中 文末 合計
頻度 109 347 8 493
[文頭] However, ....
[文中] ..., however, ....
[文末] ..., however.](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-138-320.jpg)








![4) 数値を求める
> length(nns_unlist)
[1] 70220 # Token
!
> nns_all <- table(nns_unlist)
# 単語一覧表の作成
!
> nns_type <- length(uniq_nns)
> nns_type
[1] 7579 # Type](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-150-320.jpg)





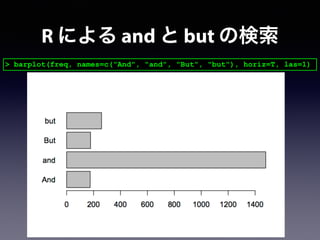
![> length(grep("^And,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 175
> length(grep("^But,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 178
> length(grep("^and,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 1479
> length(grep("^but,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 260
R による and と but の検索](https://image.slidesharecdn.com/slidesharelet2014fukuoka140804sakaue-140803053623-phpapp02/85/54-R-156-320.jpg)