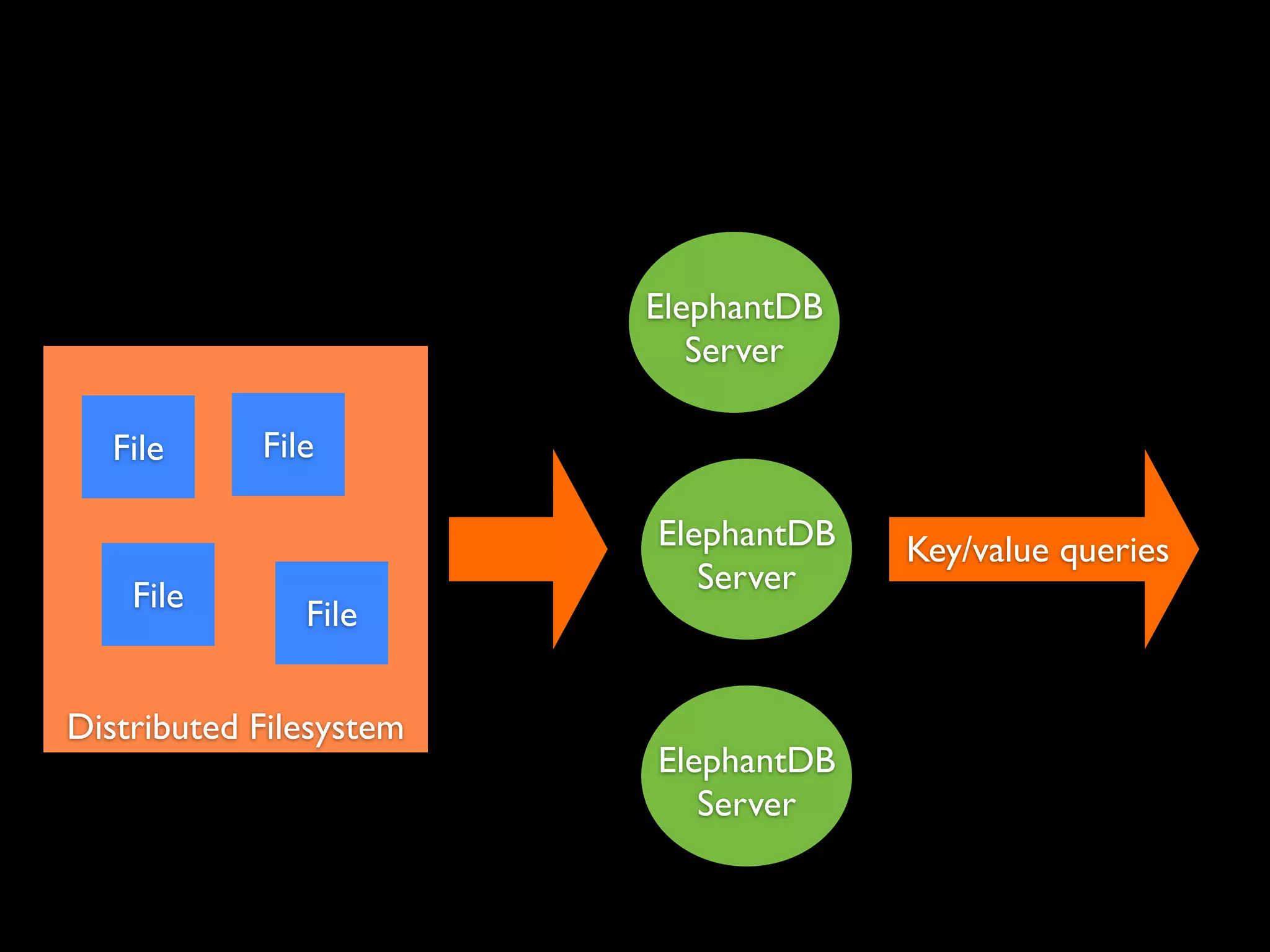
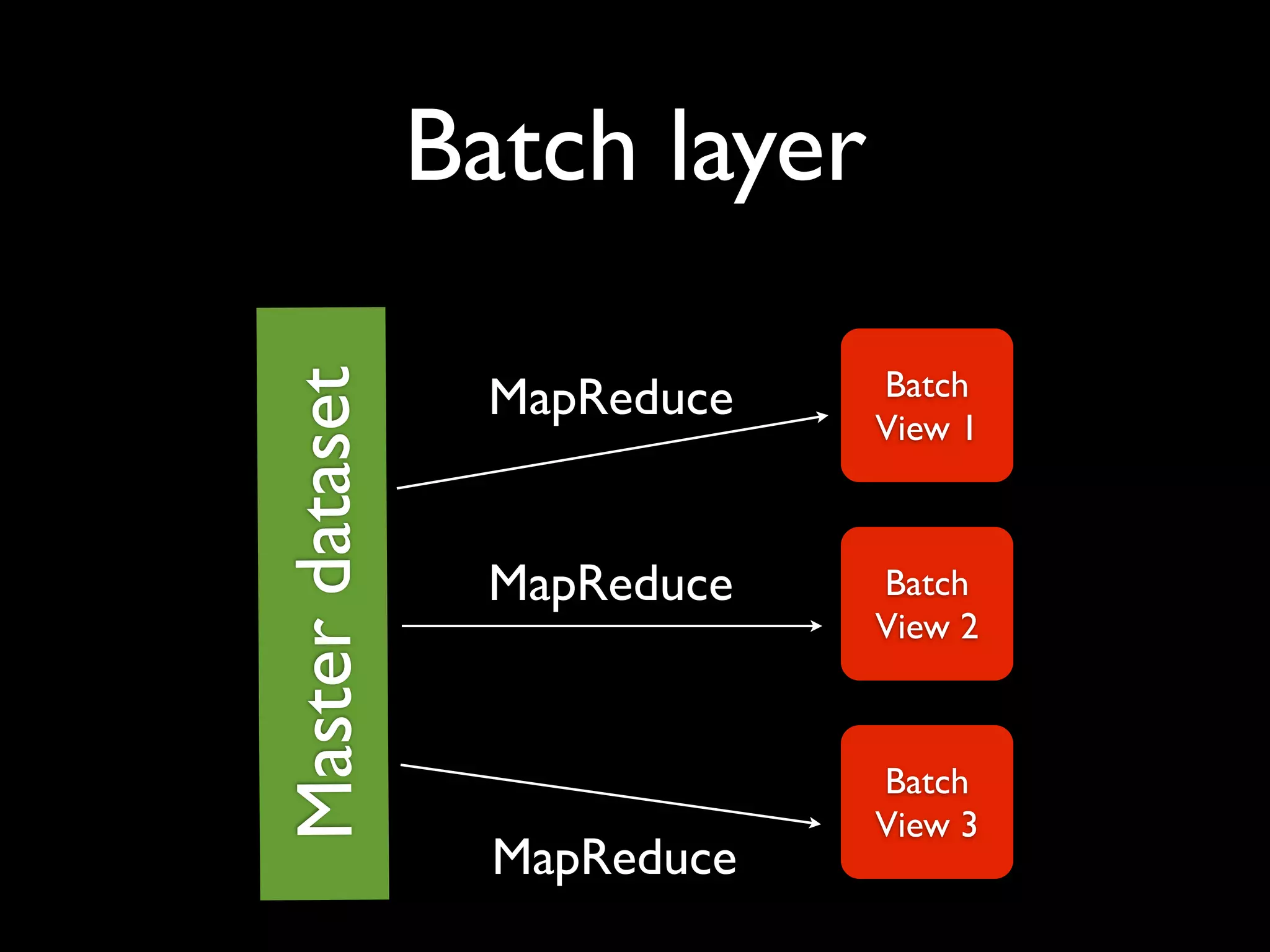
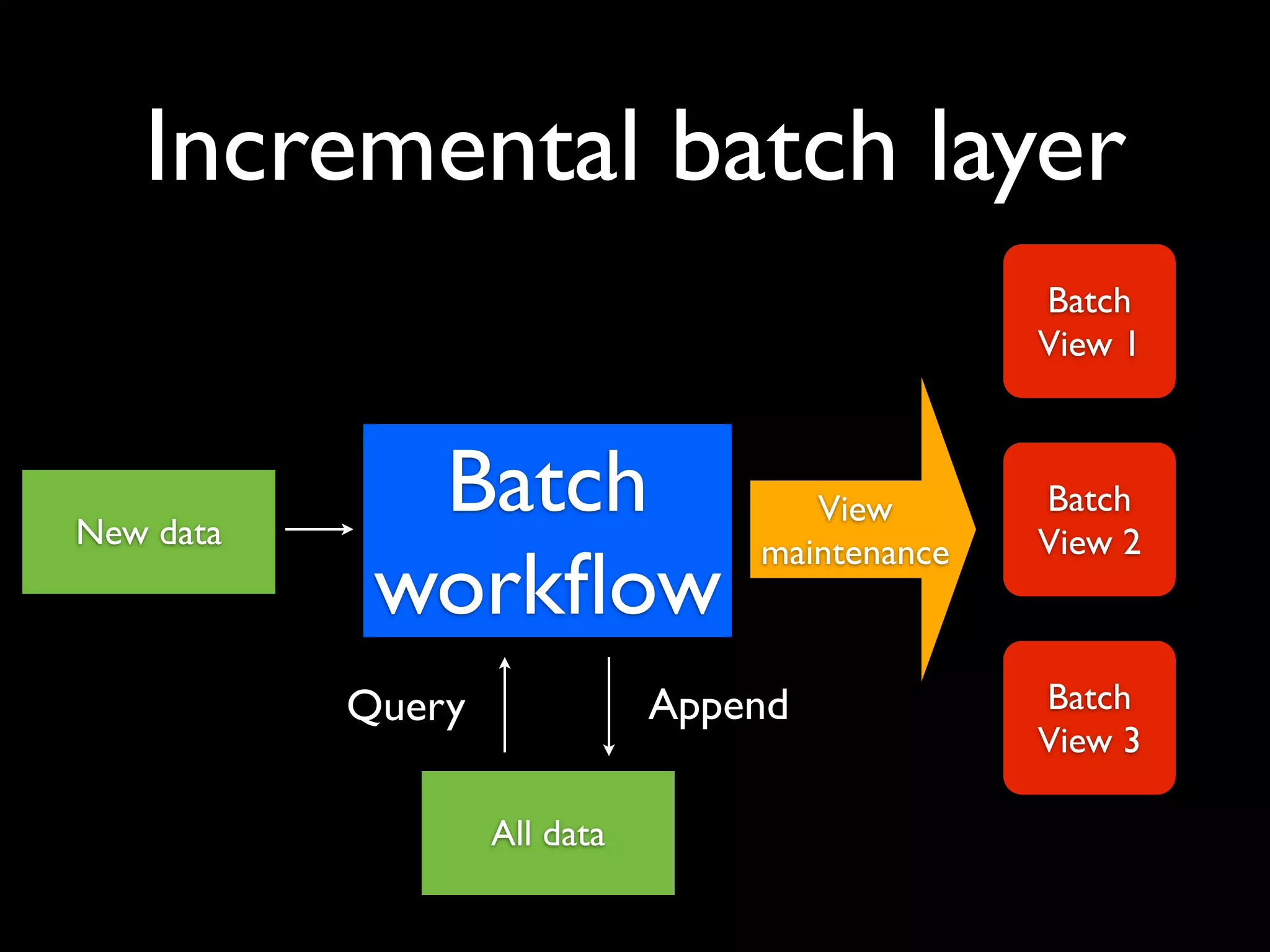
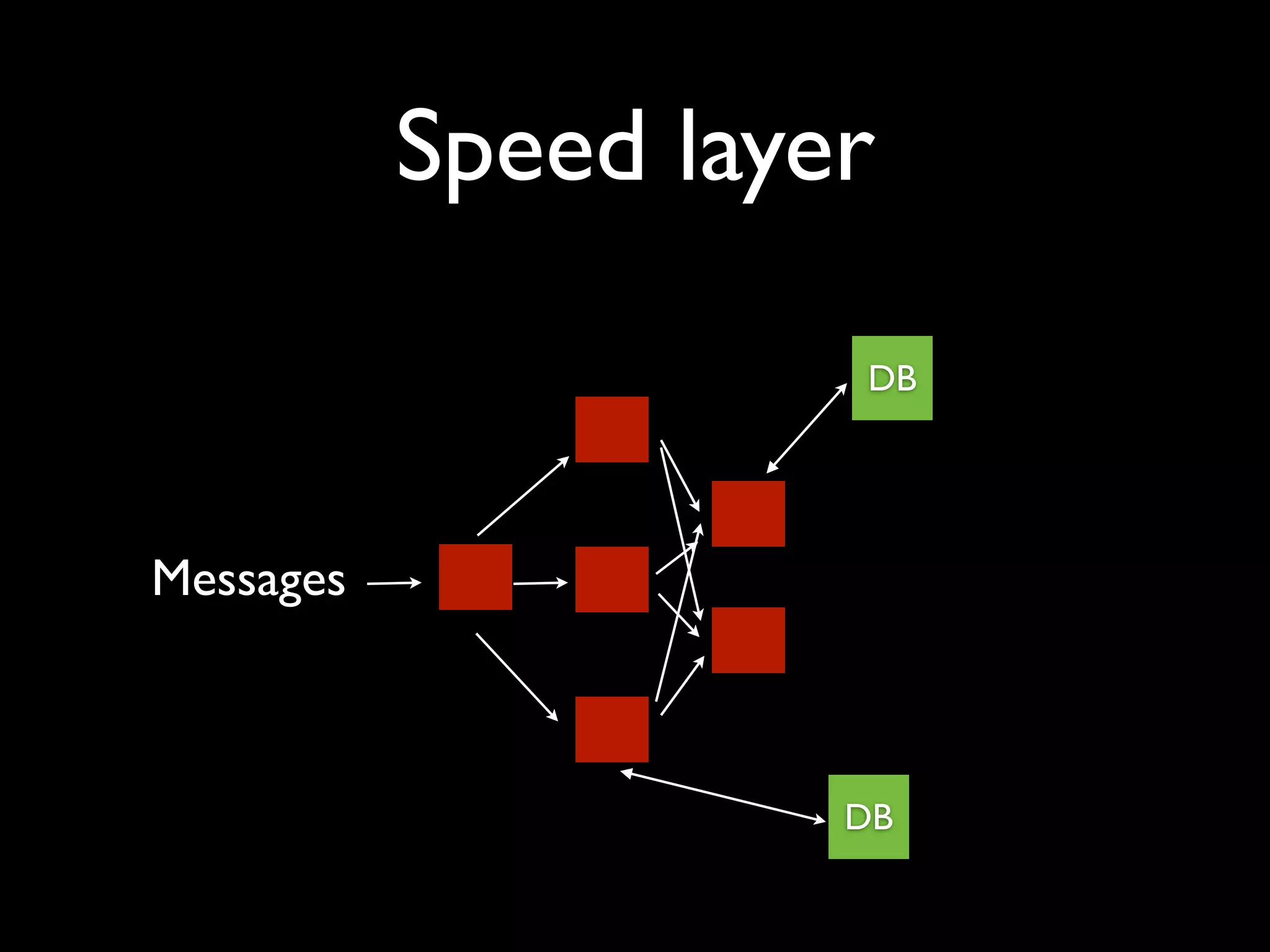
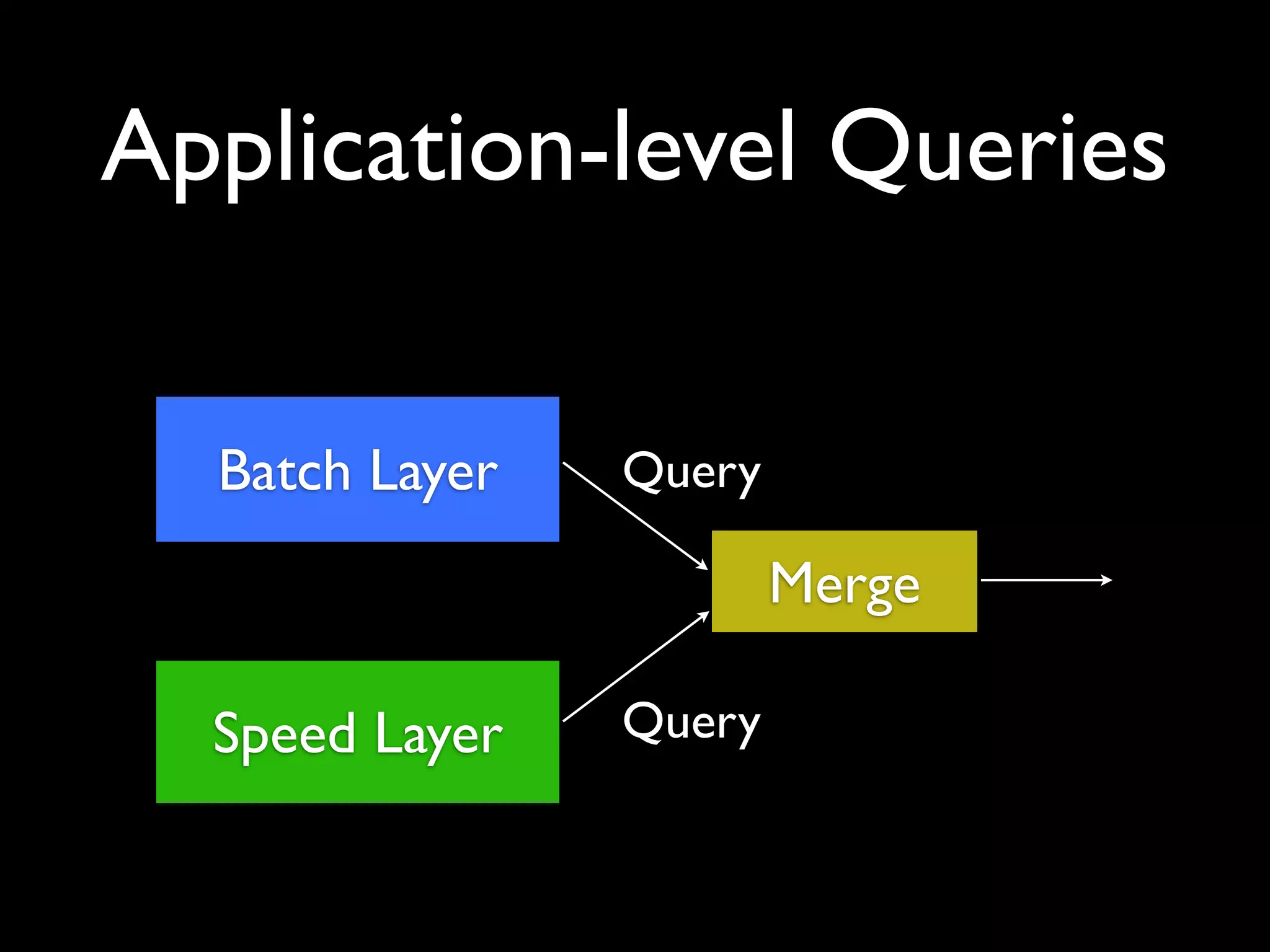
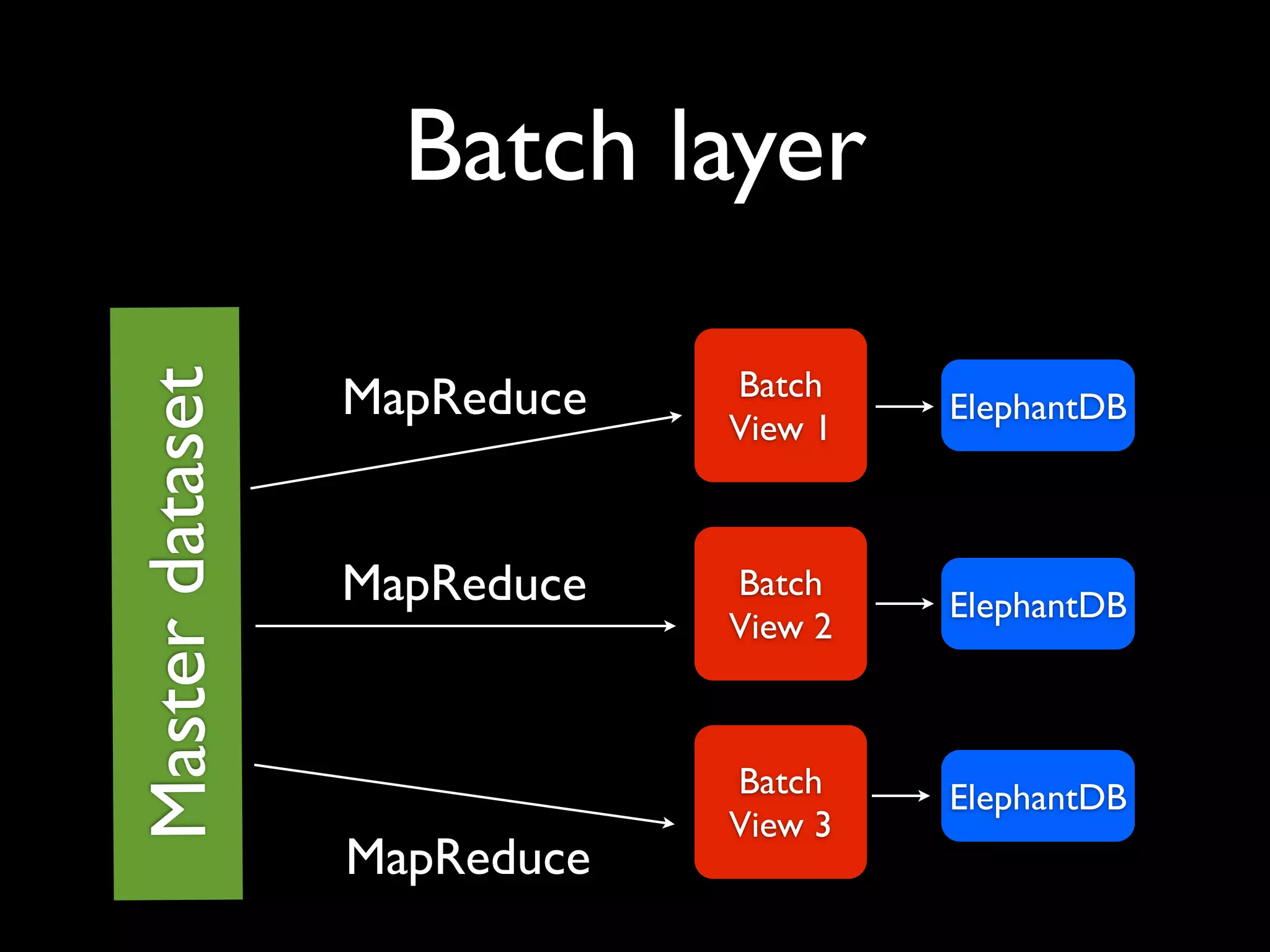
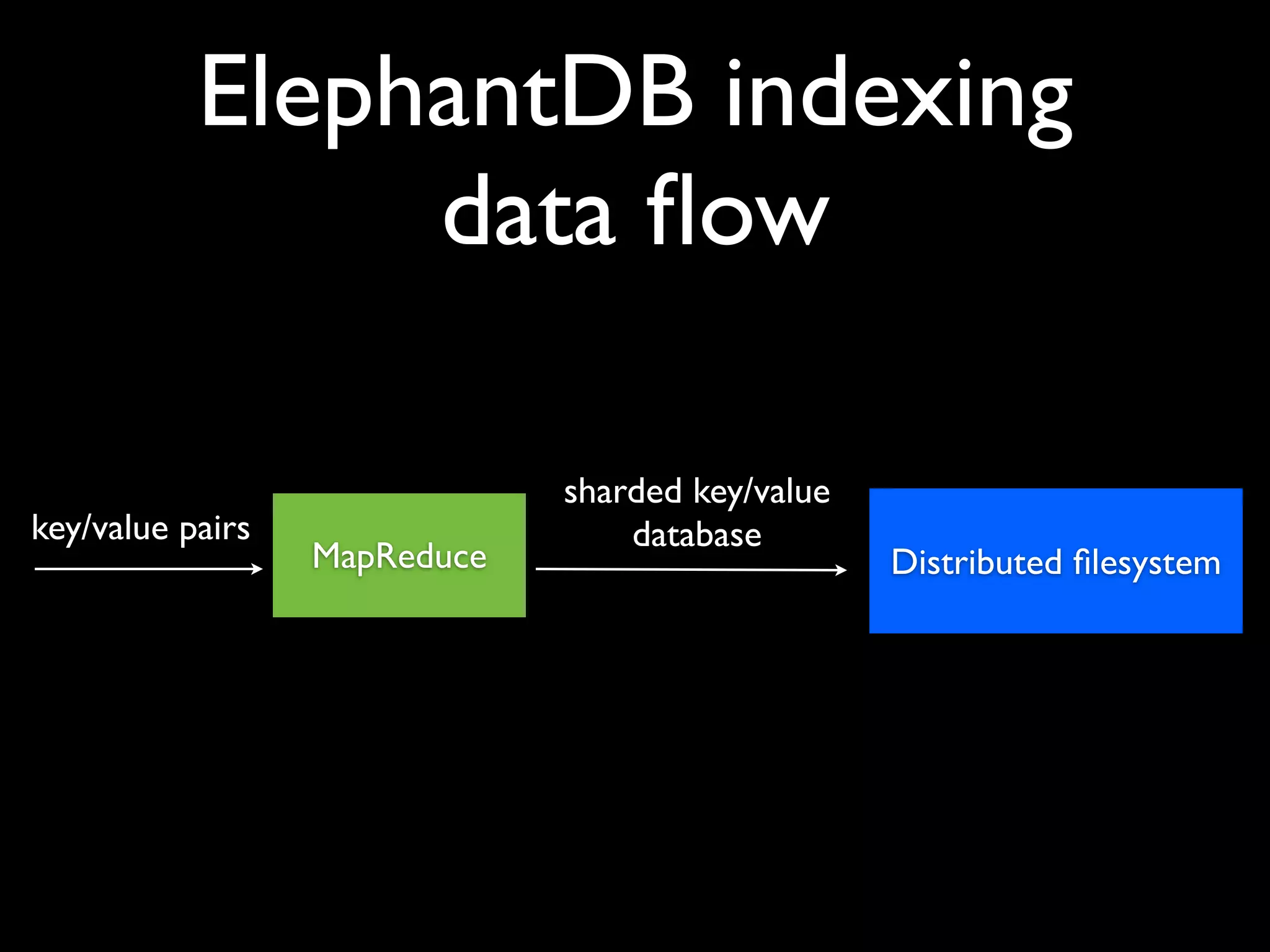
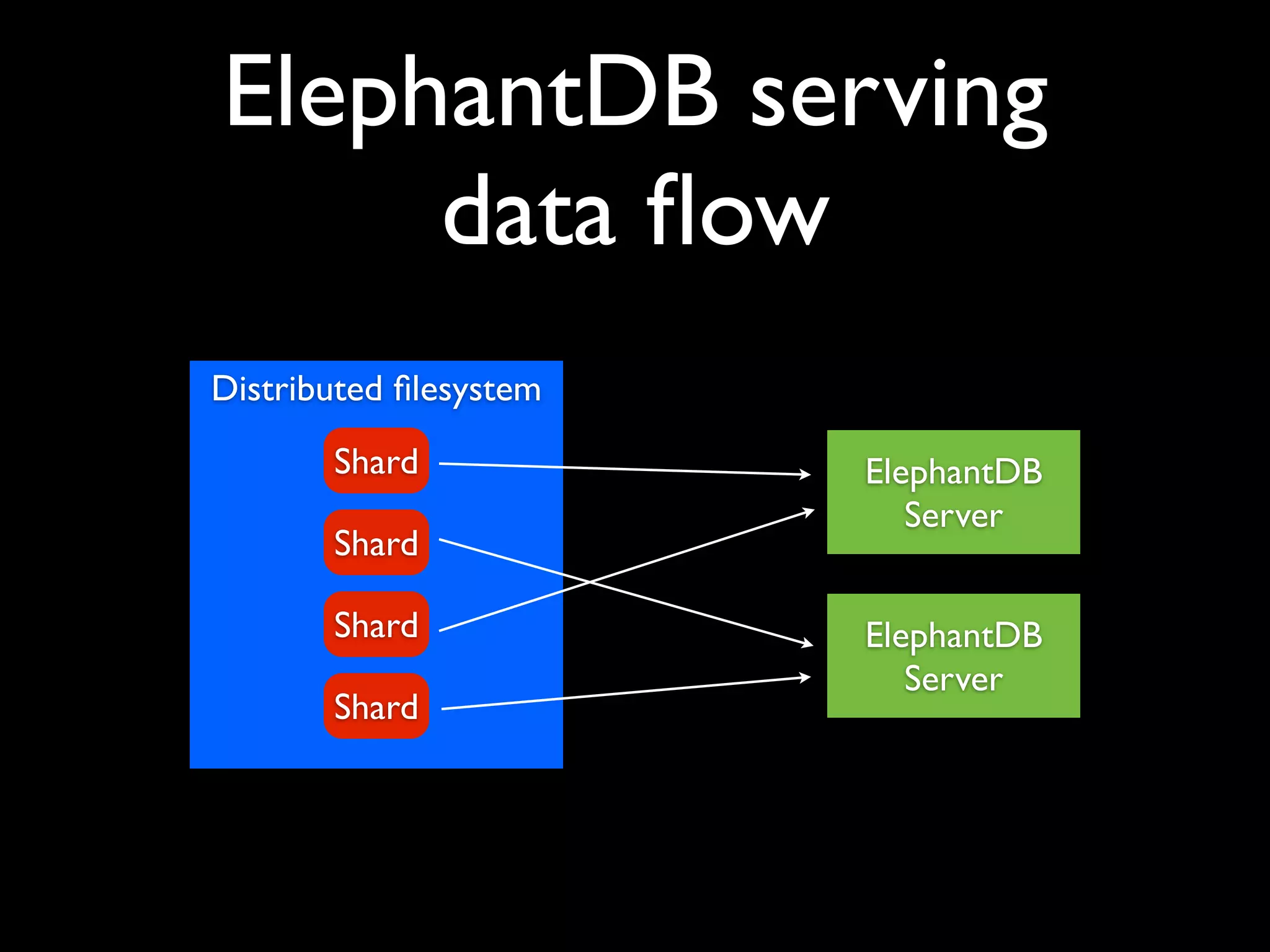
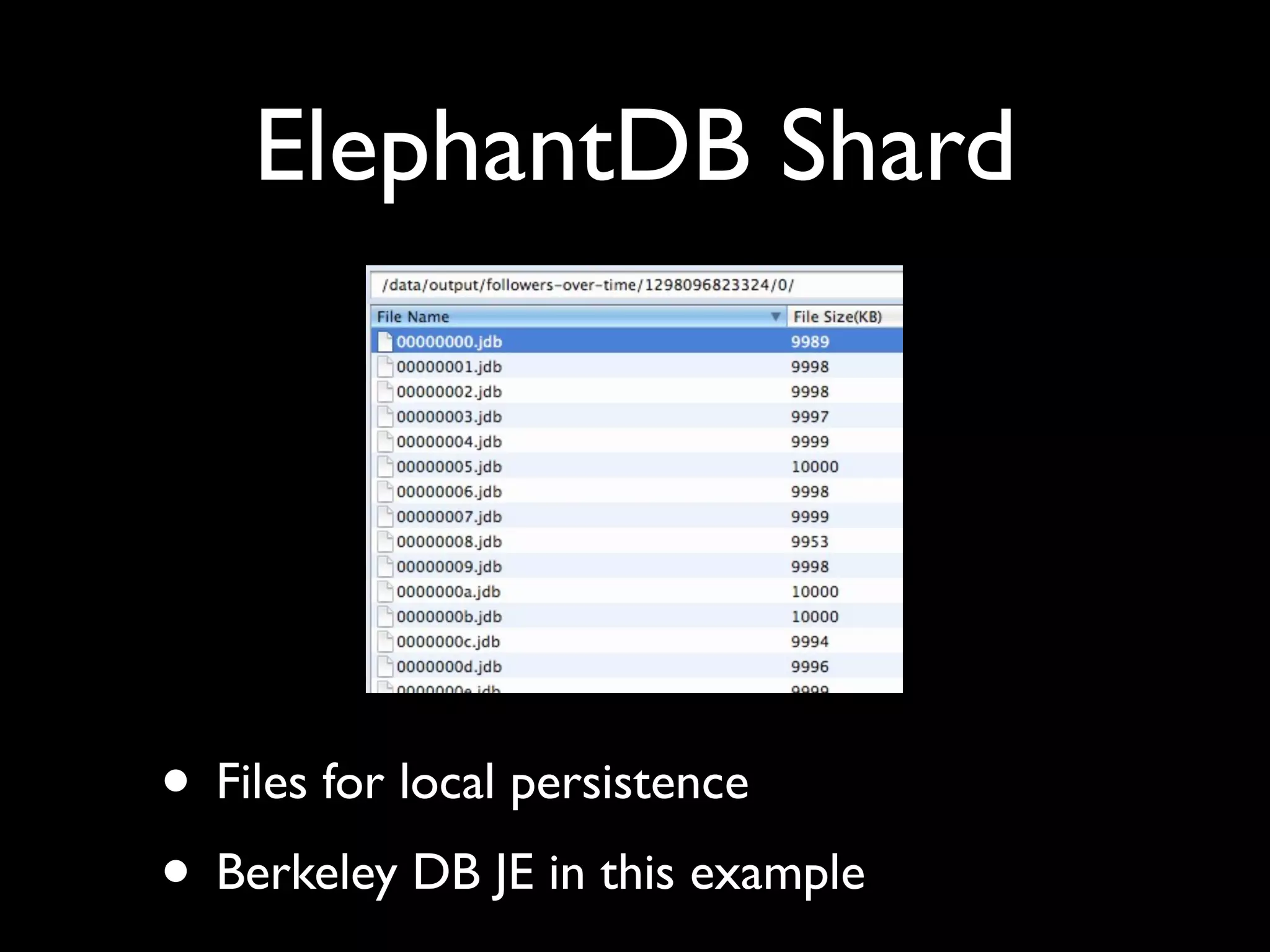
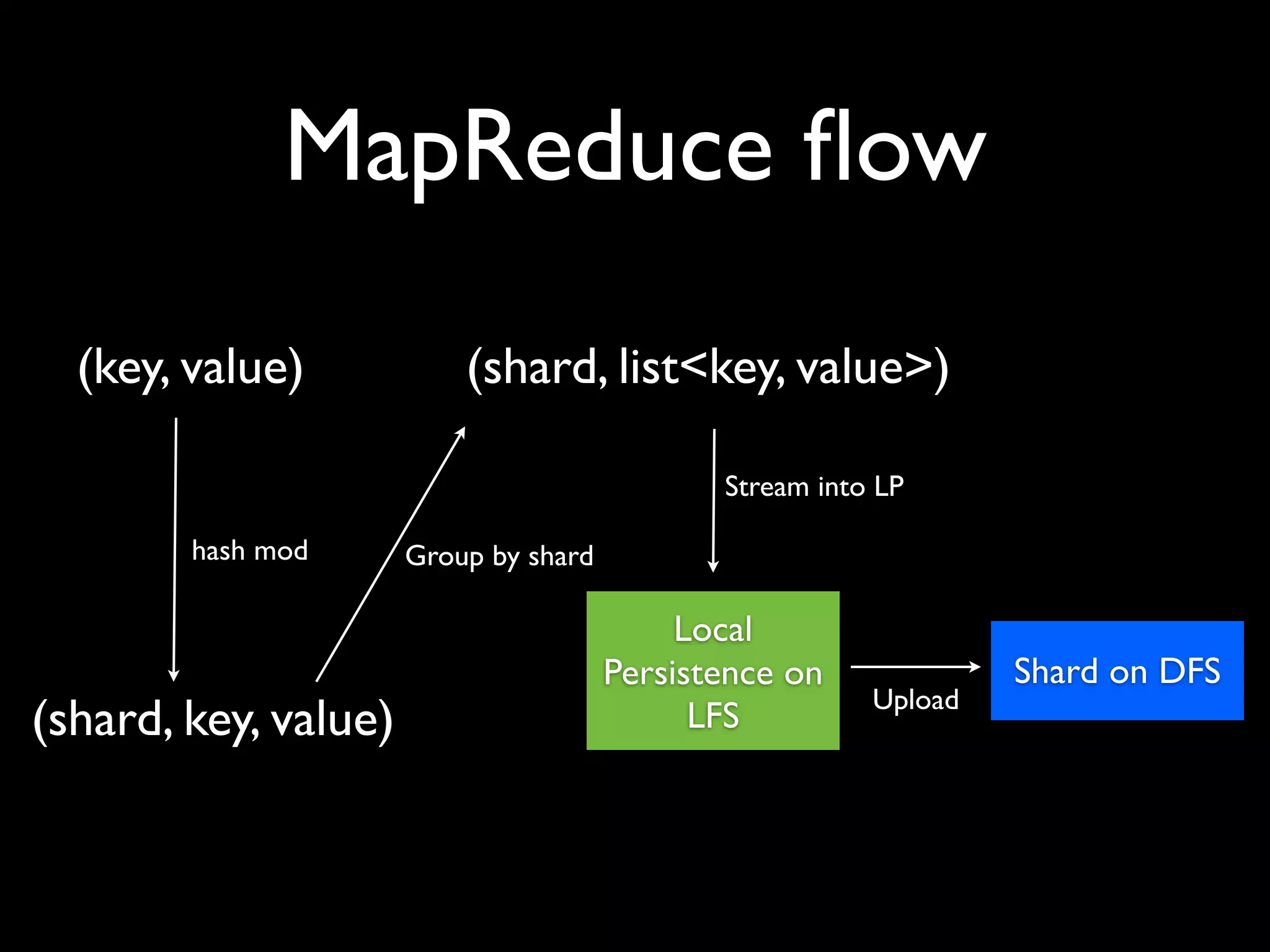
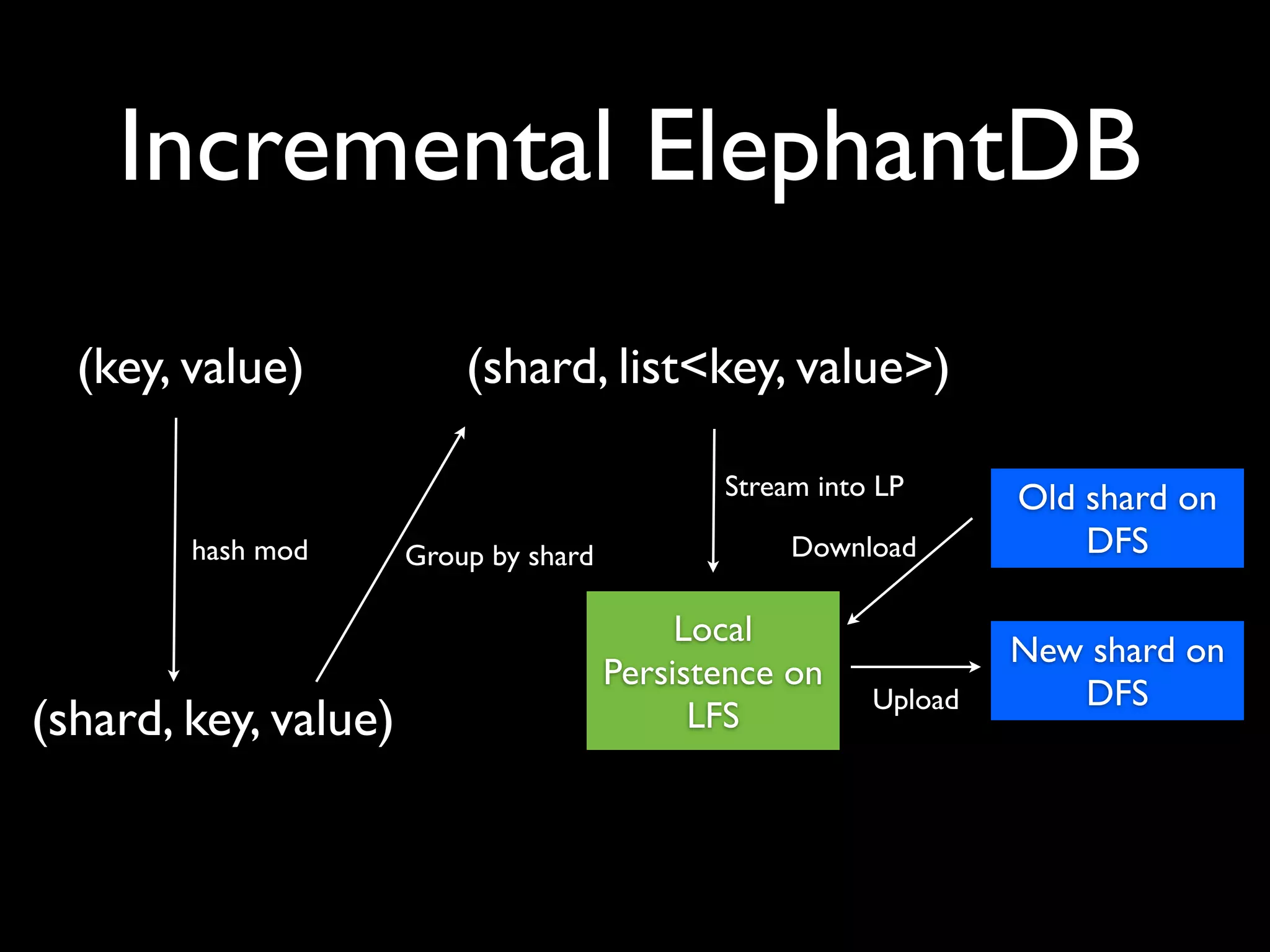
ElephantDB is a specialized key-value database designed for exporting data from Hadoop. It allows for random reads, batch writes, and random writes of data in a scalable way. ElephantDB indexes data using MapReduce to group keys by shard and write to local databases. It supports incremental indexing to avoid reindexing from scratch. Queries can be performed directly on ElephantDB or by reading indexed files from Hadoop. It provides a simpler and more reliable alternative to HBase for certain use cases.



























































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













