





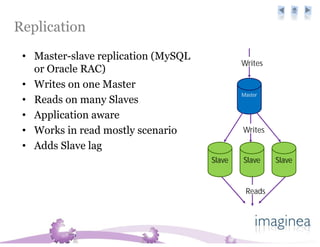
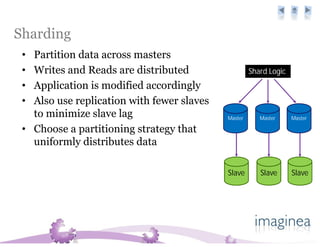
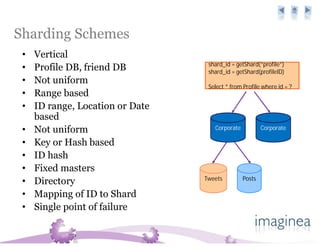

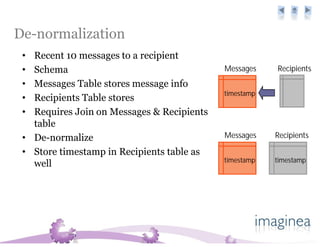





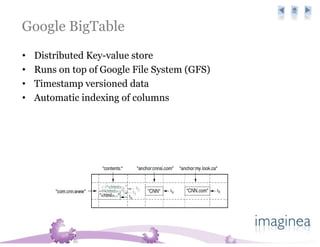








The document discusses the challenges and strategies for scaling databases in cloud computing, highlighting the need for high reliability, low latency, and dynamic scalability. It presents techniques such as master-slave replication, sharding, and de-normalization to address performance constraints and optimize data management. Additionally, it reviews various cloud database options like Amazon SimpleDB, Google Bigtable, and CouchDB, noting their specific features and limitations.








































































































