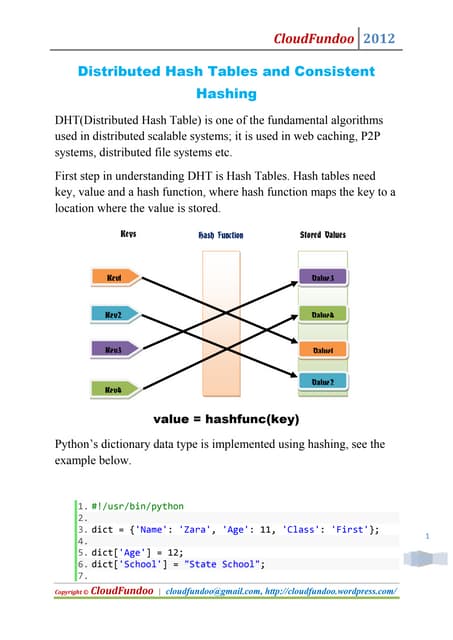
Downloaded 98 times










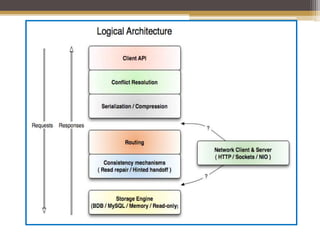







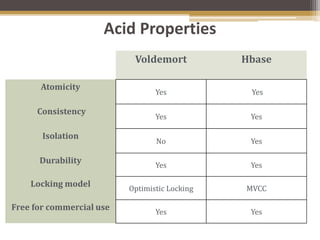







Project Voldemort is a distributed key-value store developed by LinkedIn for high scalability, featuring automatic data replication, partitioning, and tunable consistency to handle server failures efficiently. It offers a simple key-value access model and supports various storage engines and data serialization formats, making it suitable for high-performance applications. The system is resilient to server failures due to its design, allowing for multiple data copies and data versioning to maintain data integrity.