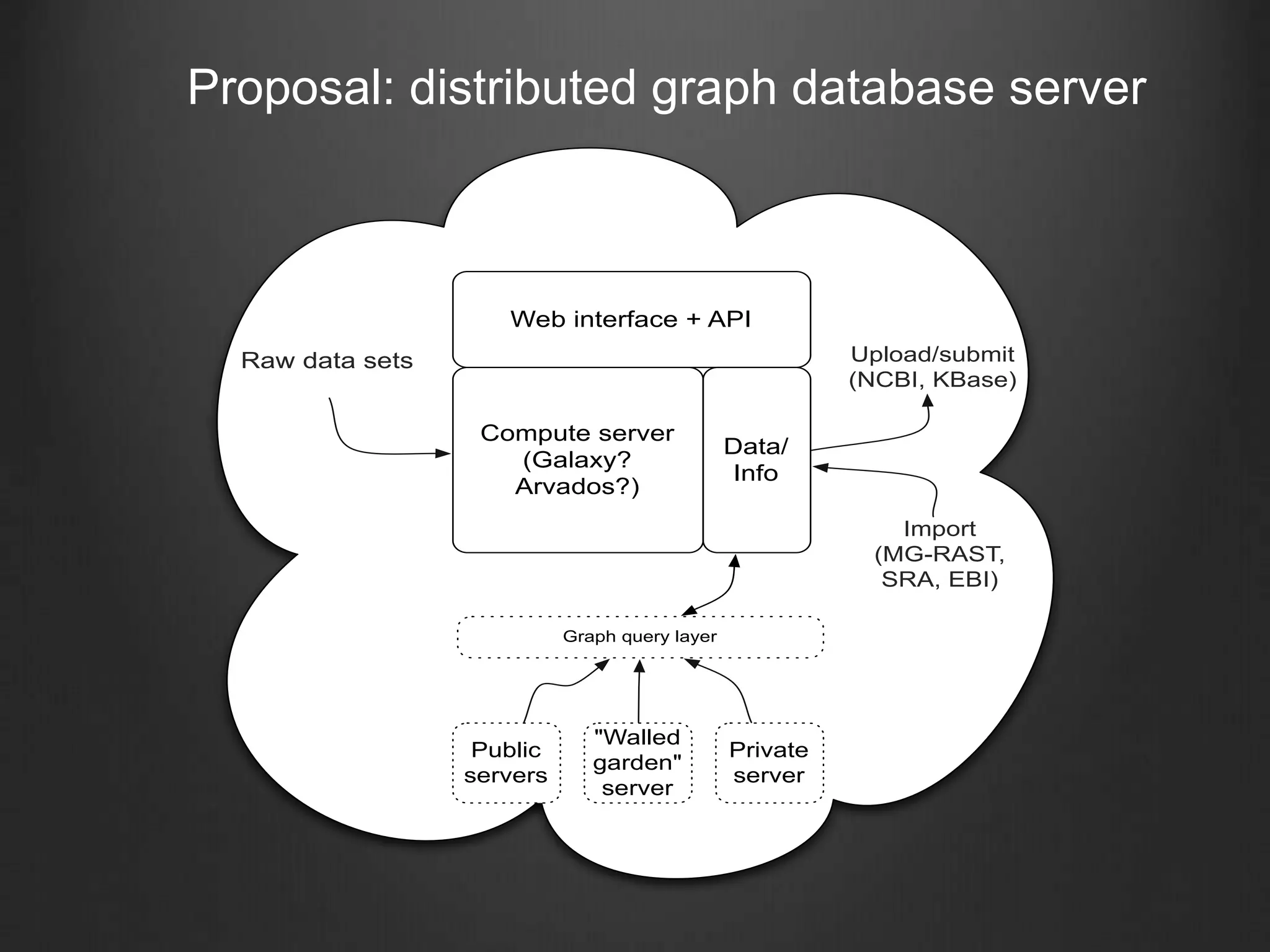
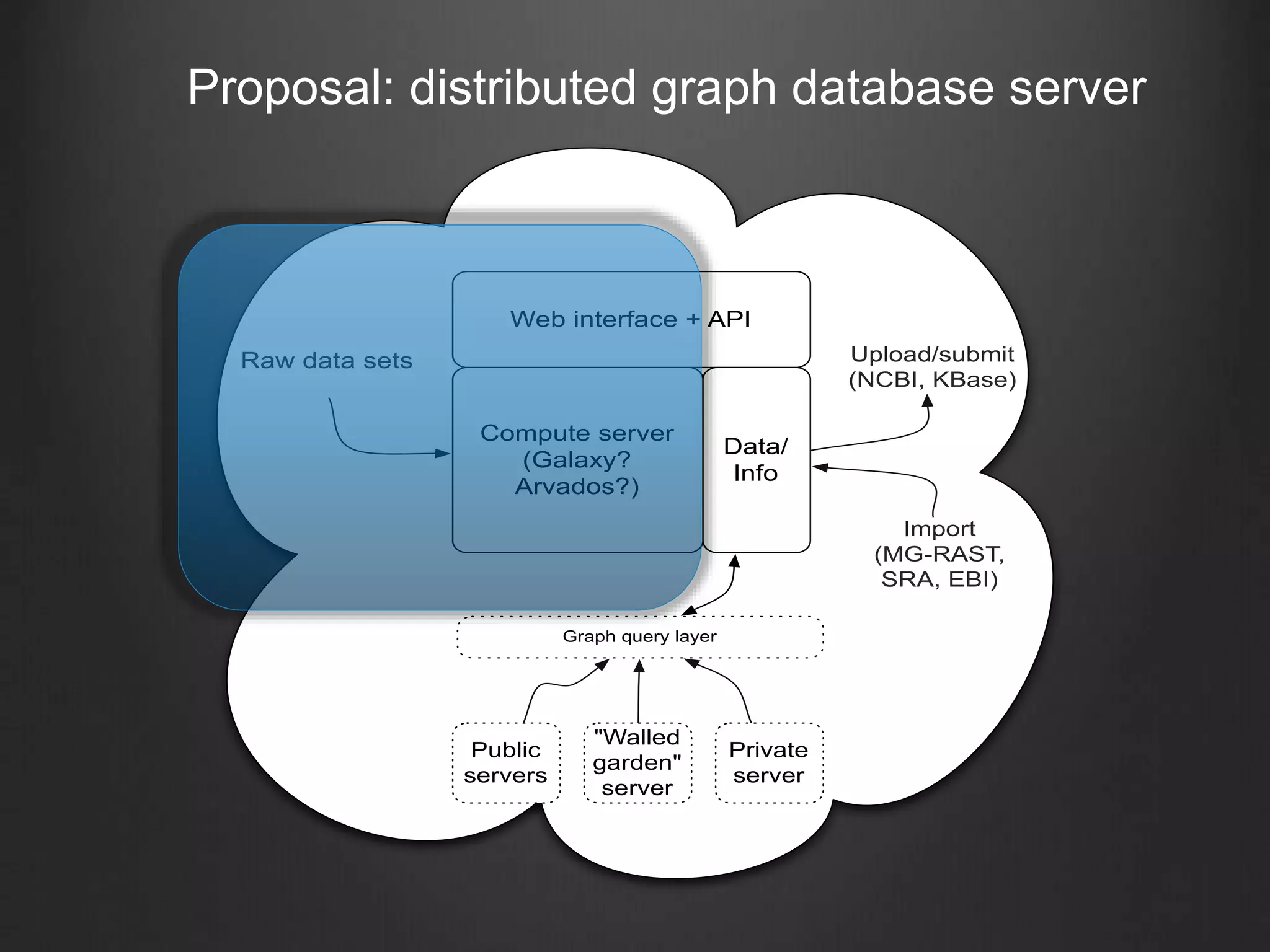
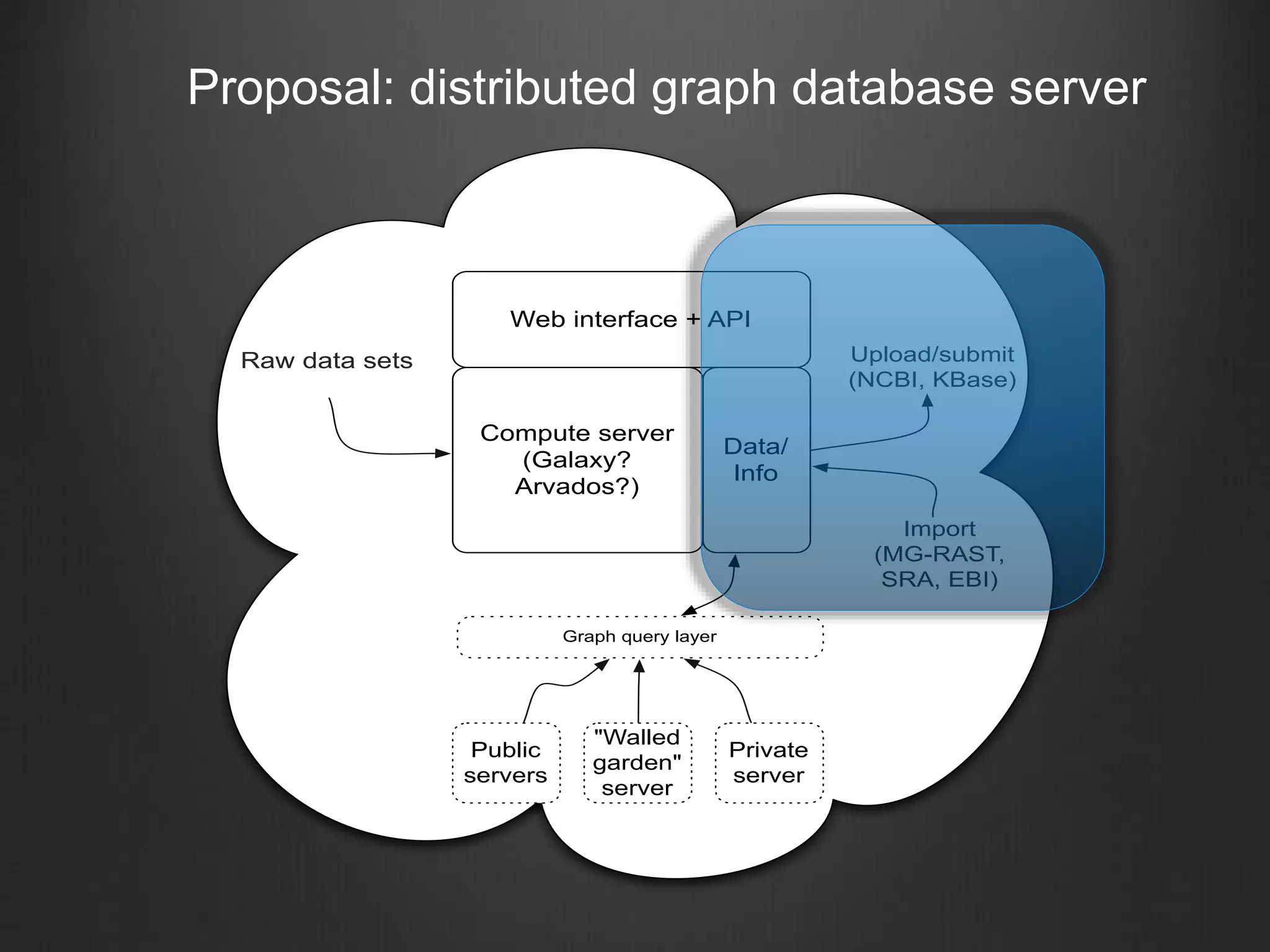
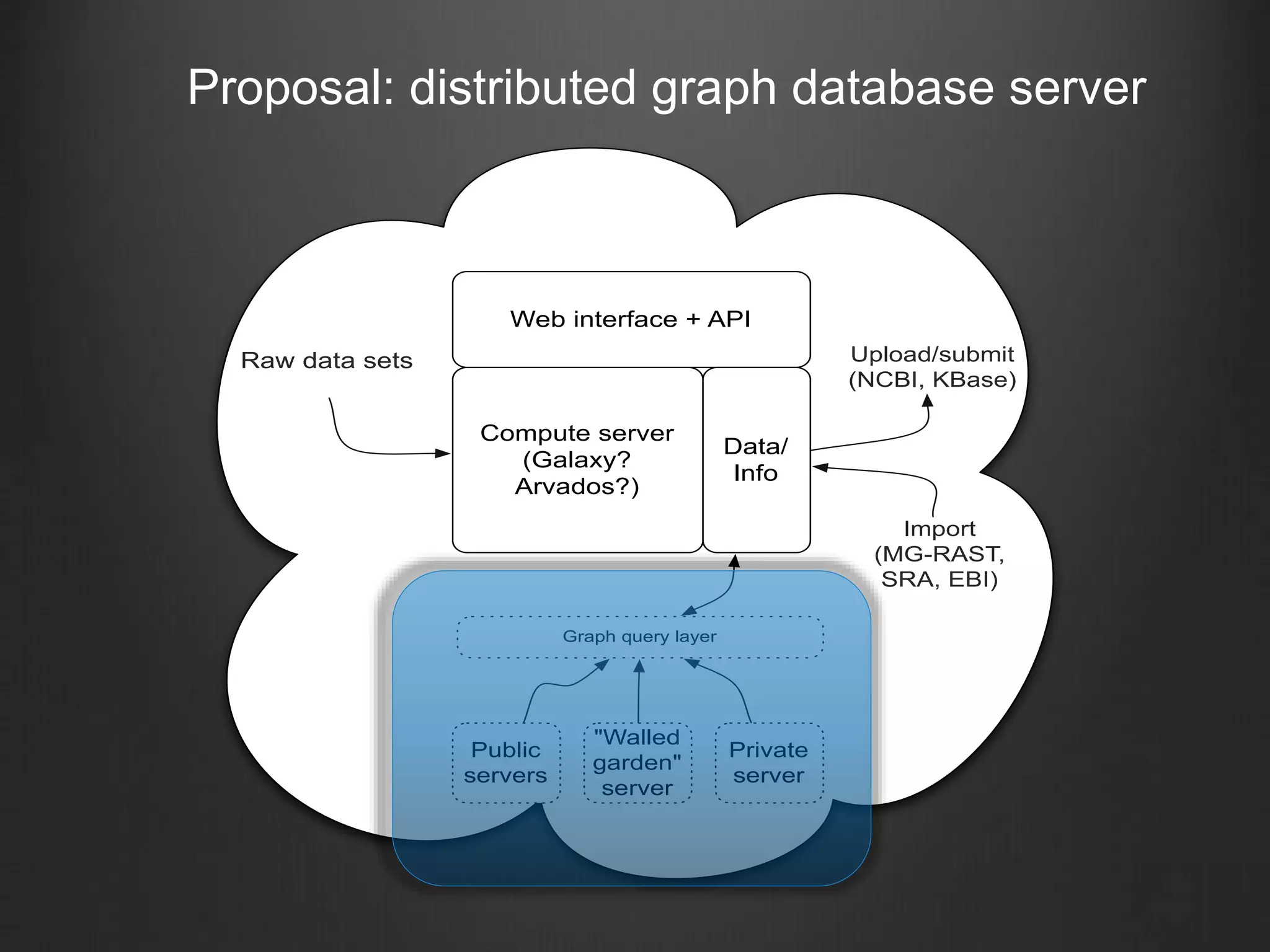
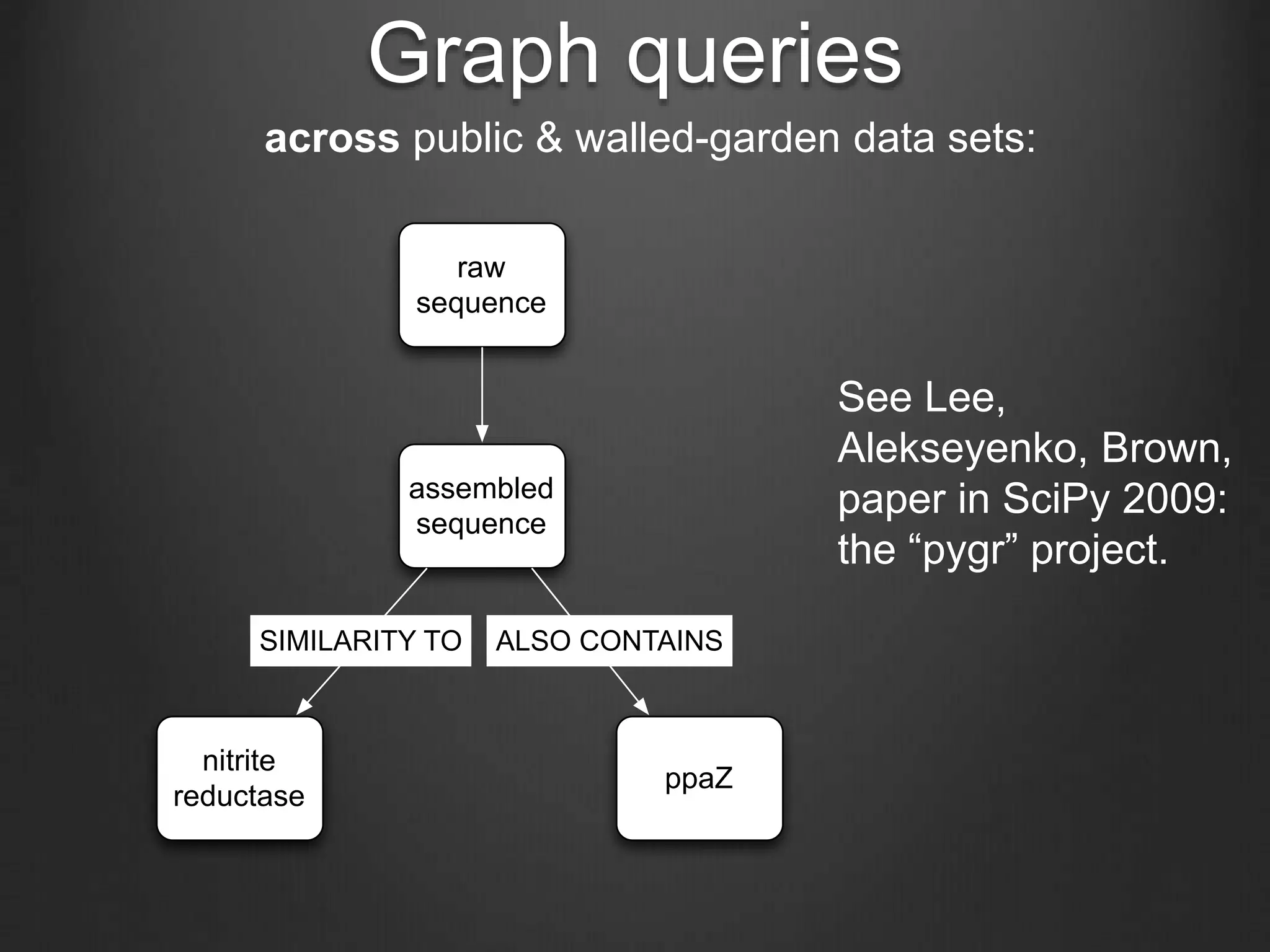
This document discusses enabling data-intensive biology through superior software and algorithms. It proposes a distributed graph database server that would allow querying across multiple public and private data sets. This would help address the growing data challenge in biology by providing a way to explore, query and mine large datasets in an open and collaborative manner. The goal is to incentivize data sharing and enable new types of data-driven investigations.