Download to read offline
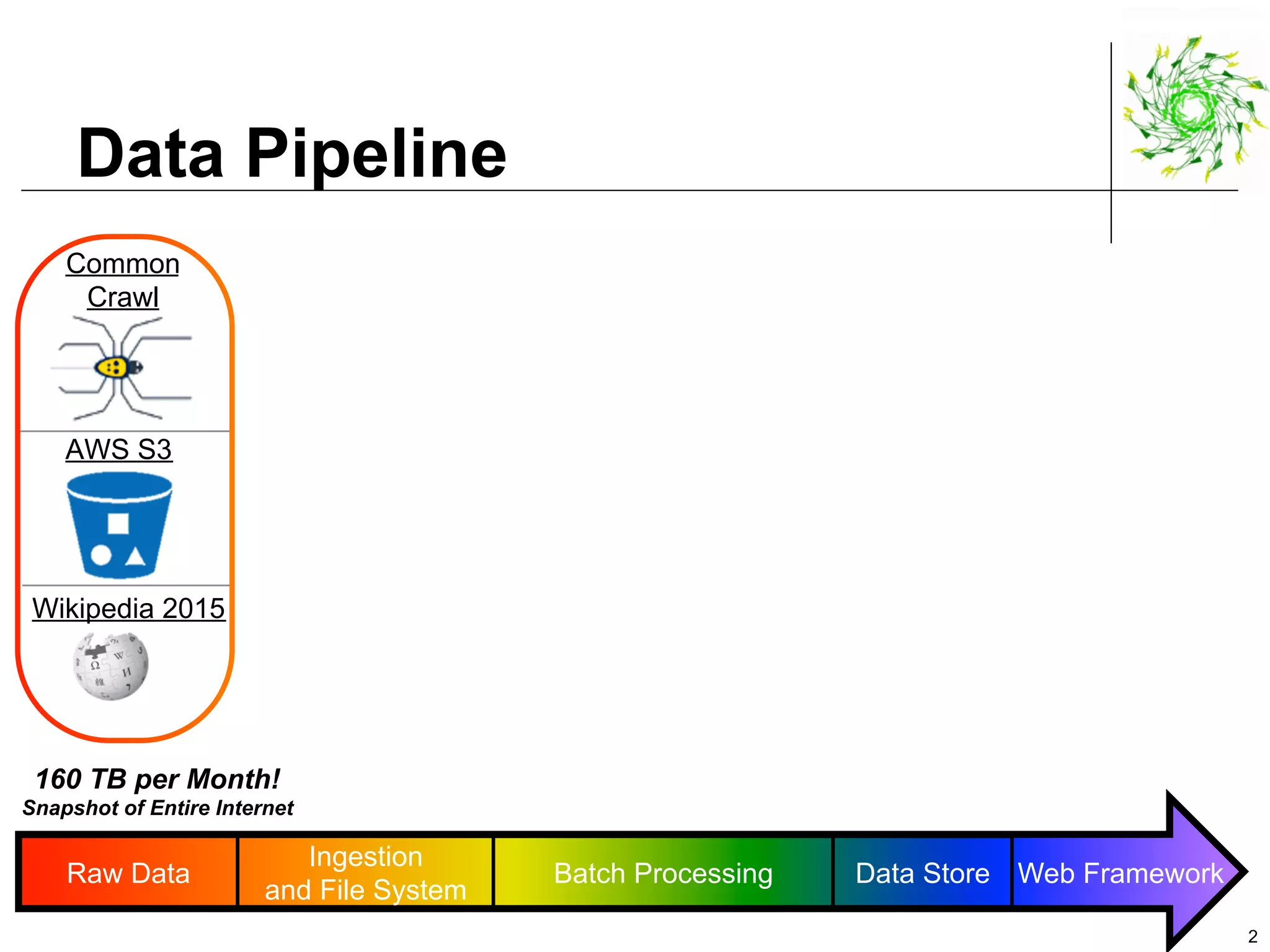
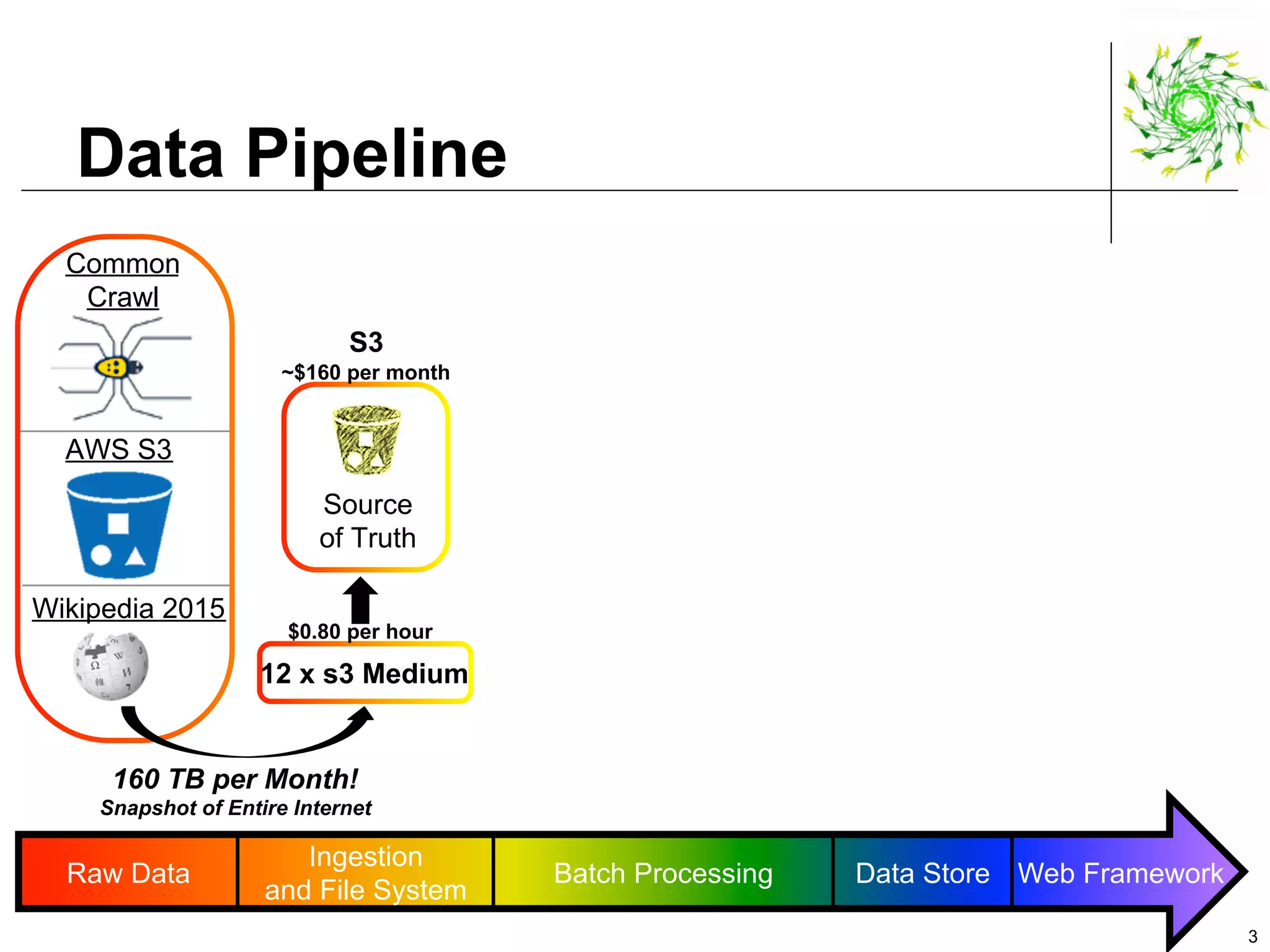
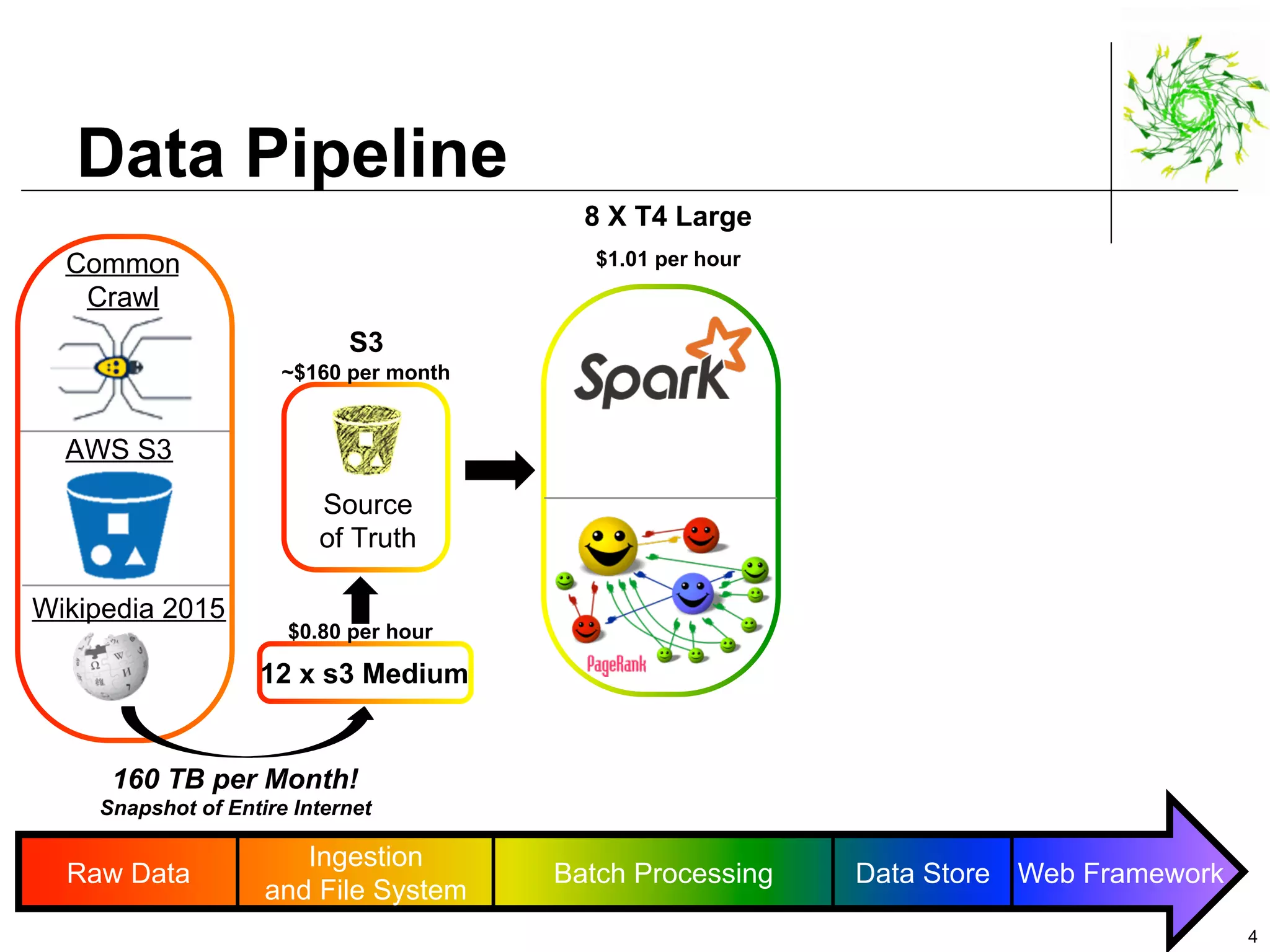
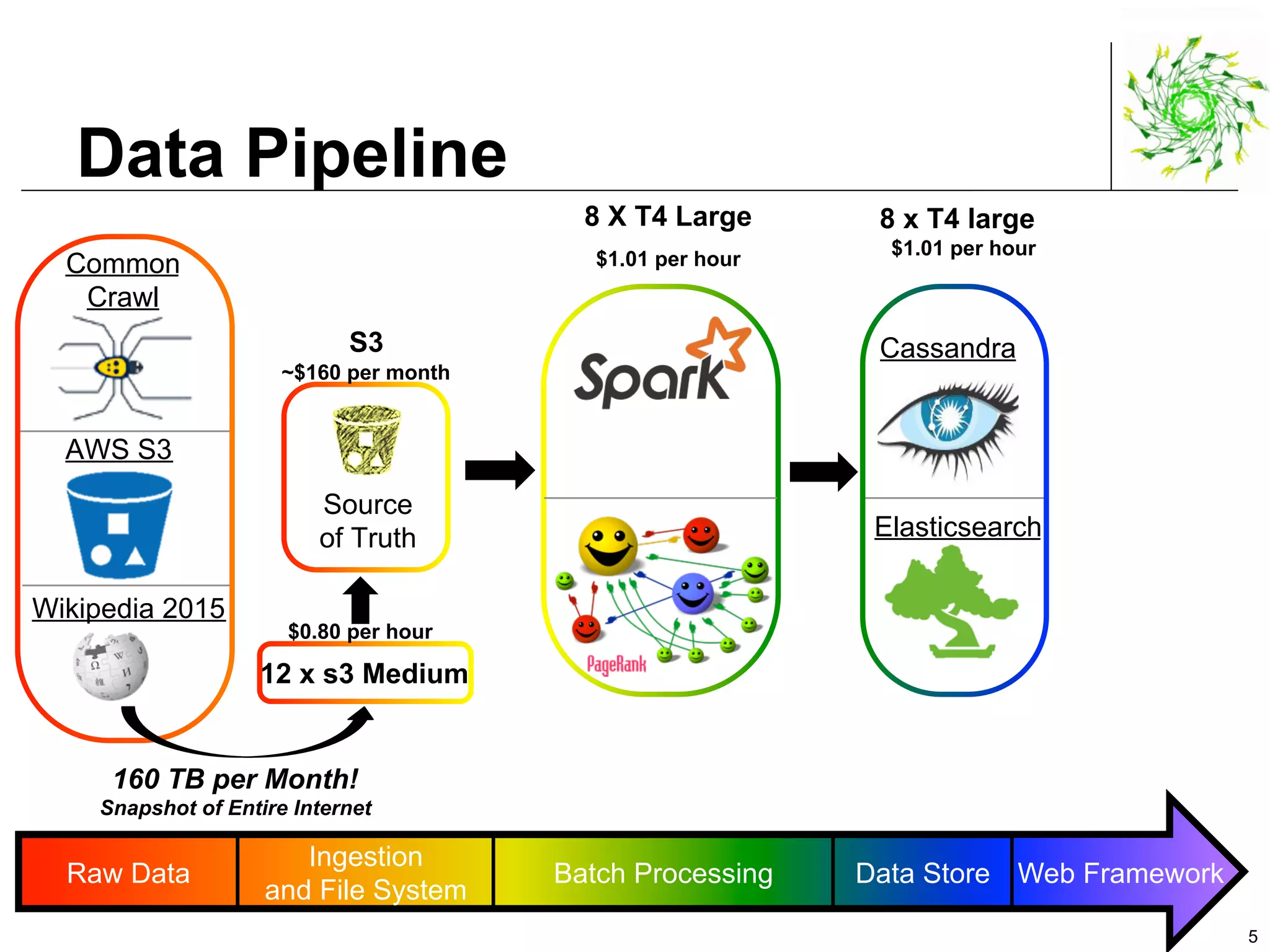
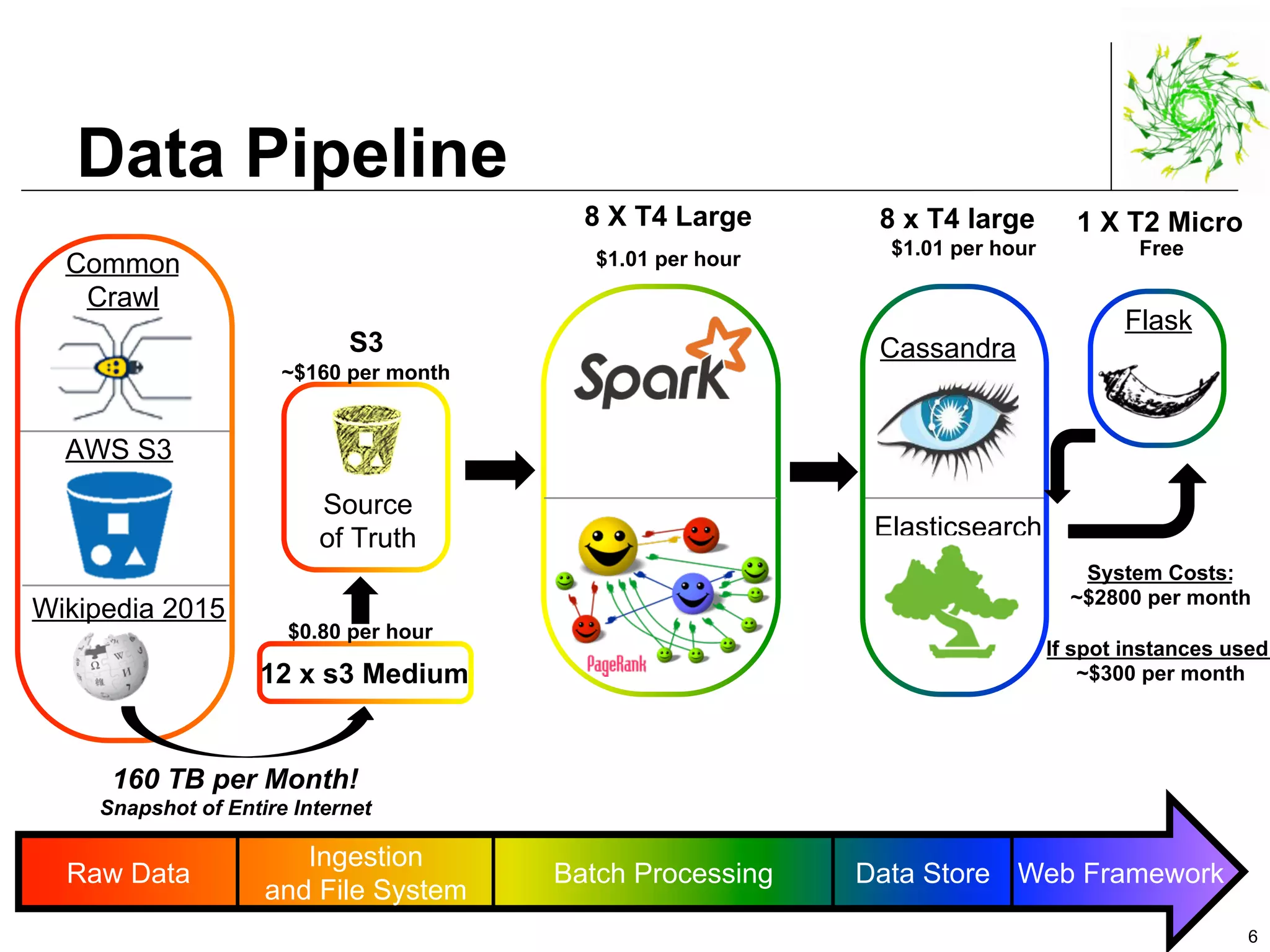

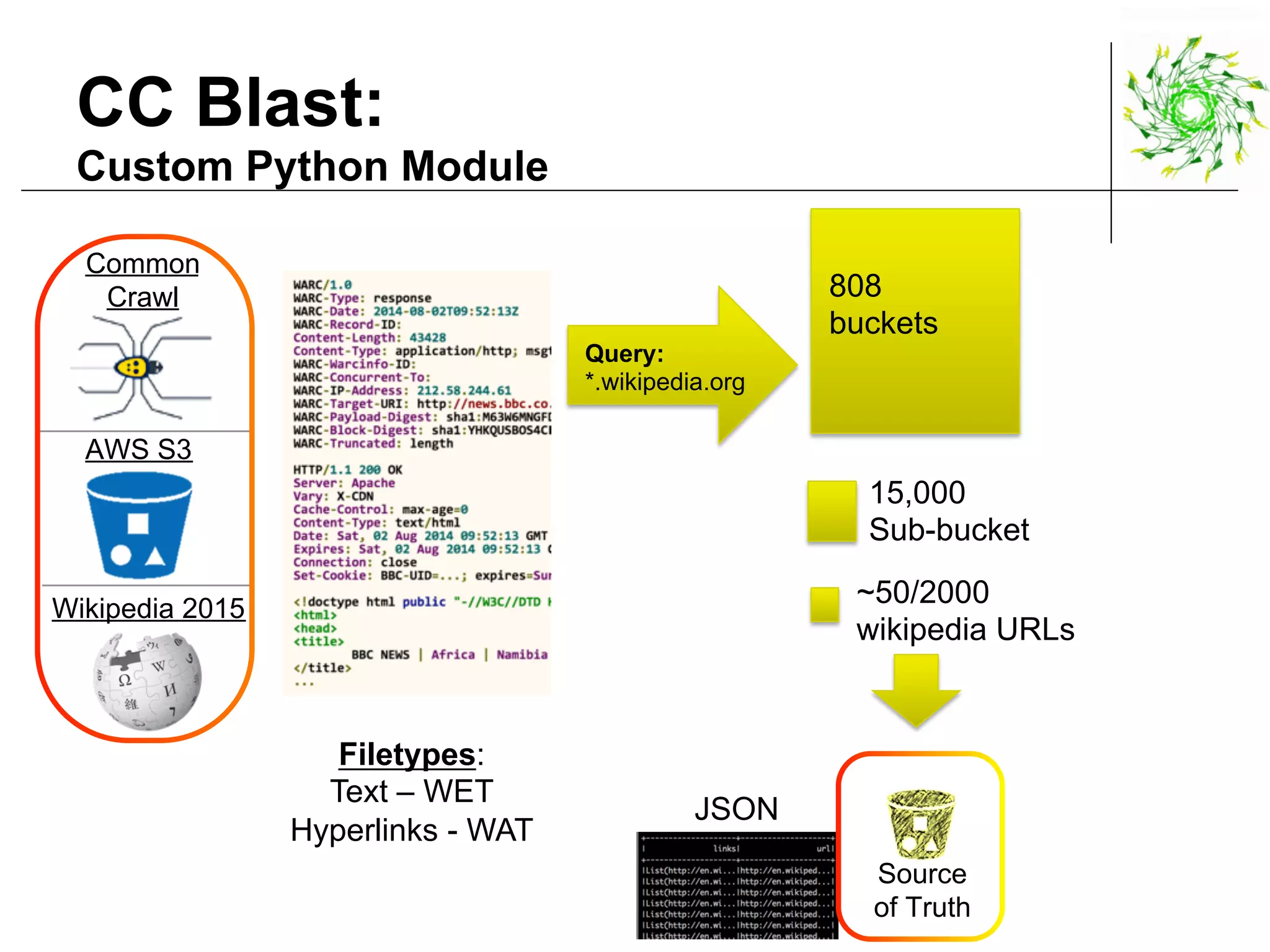
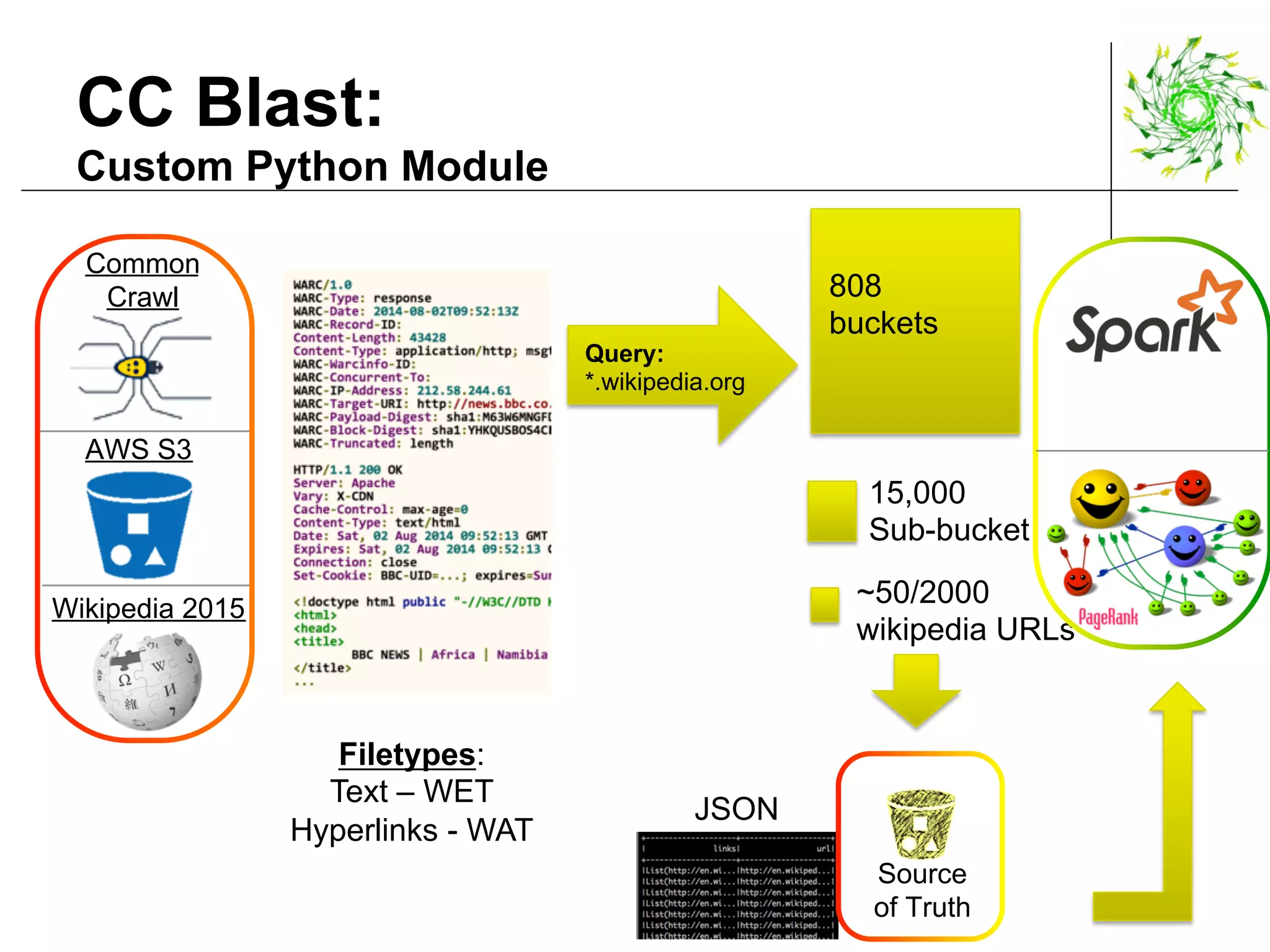


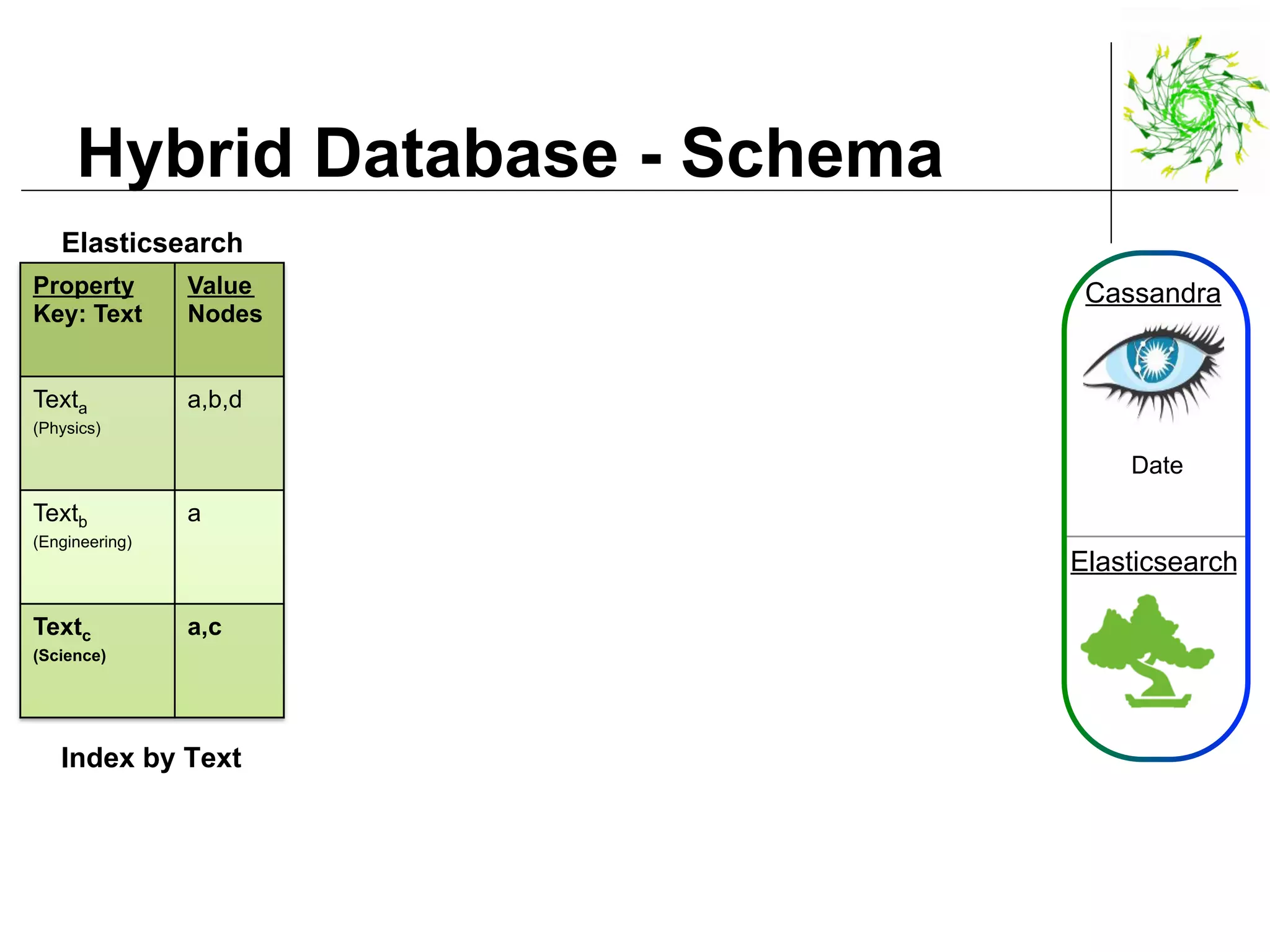
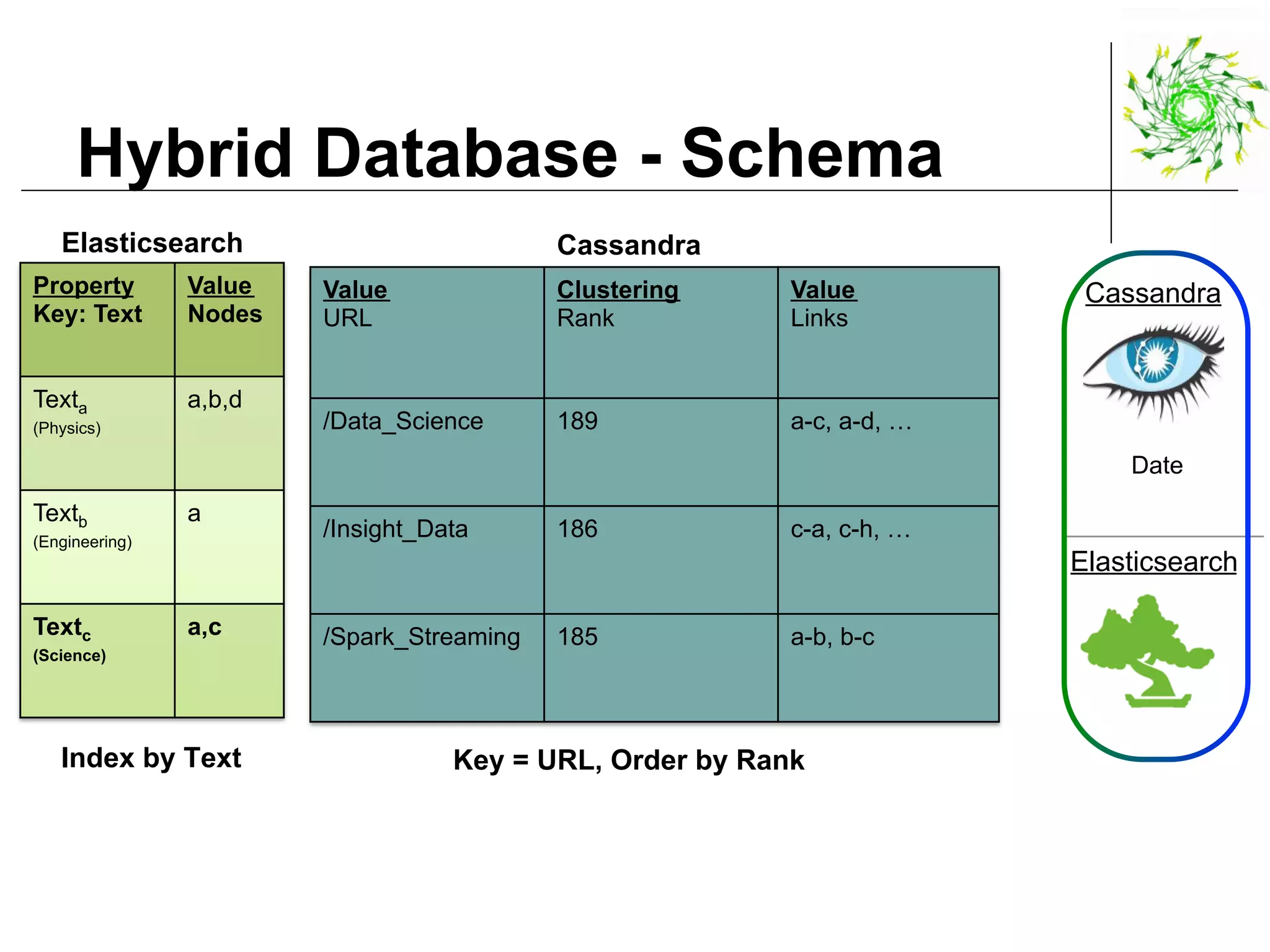
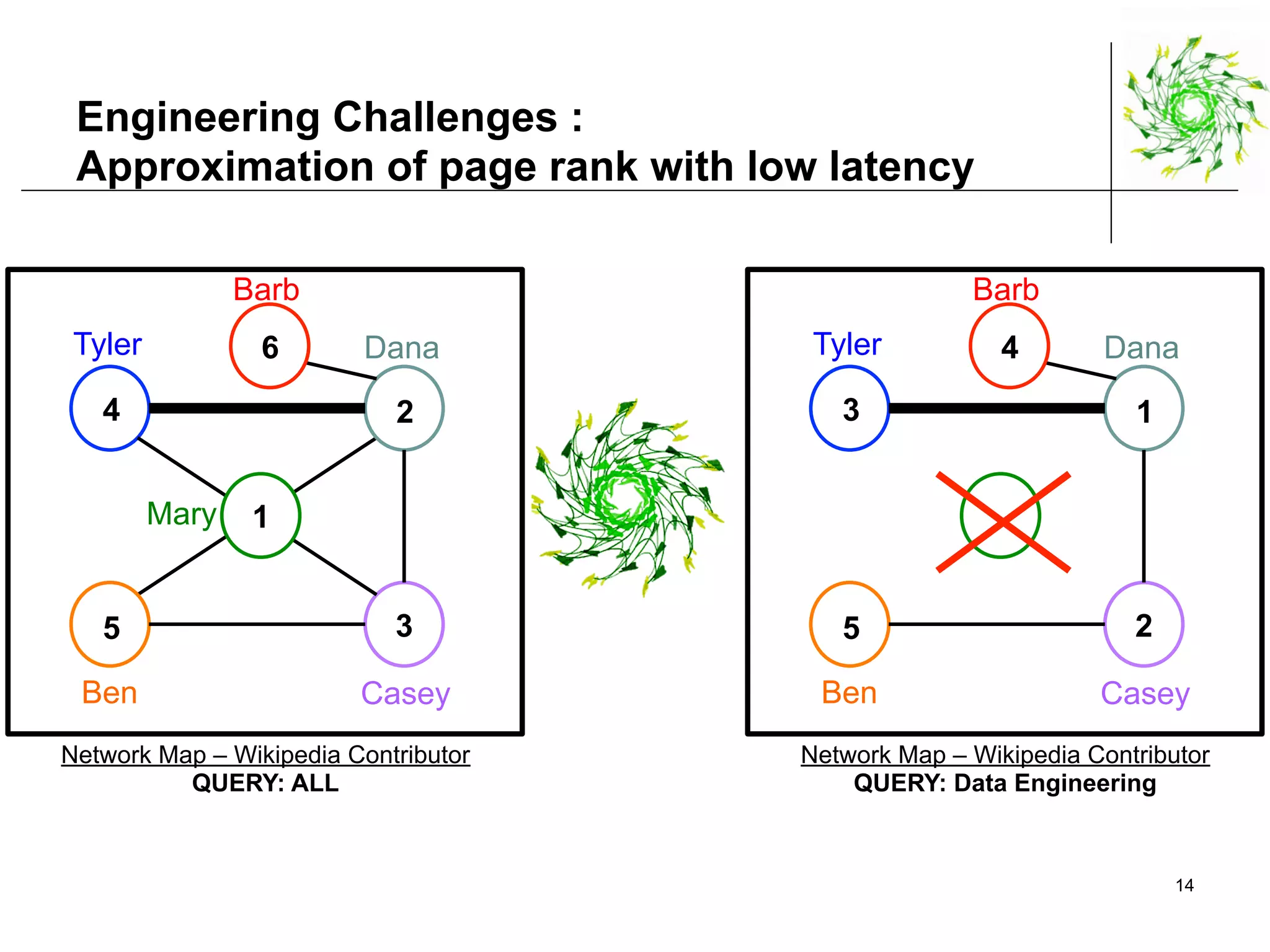
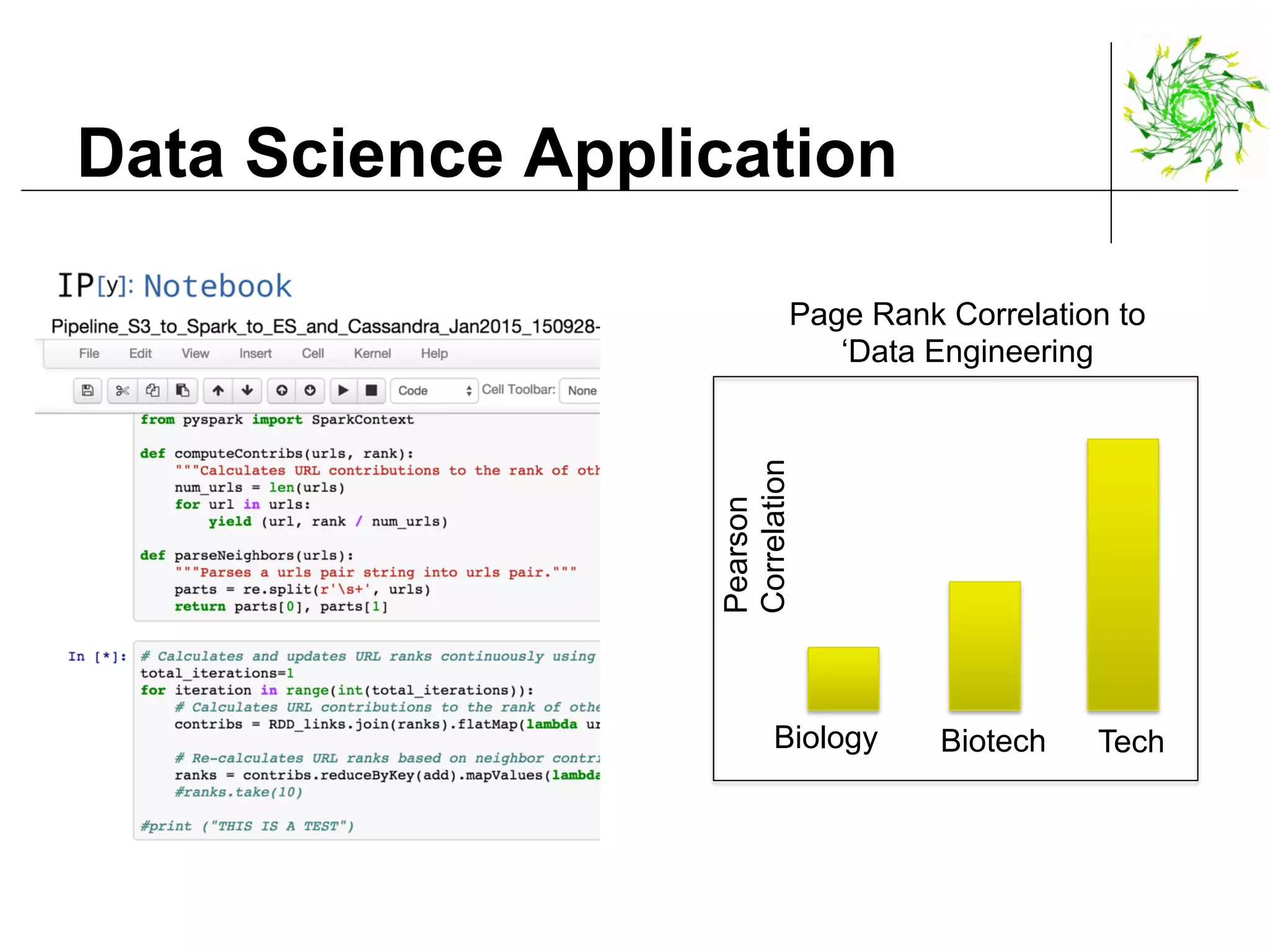

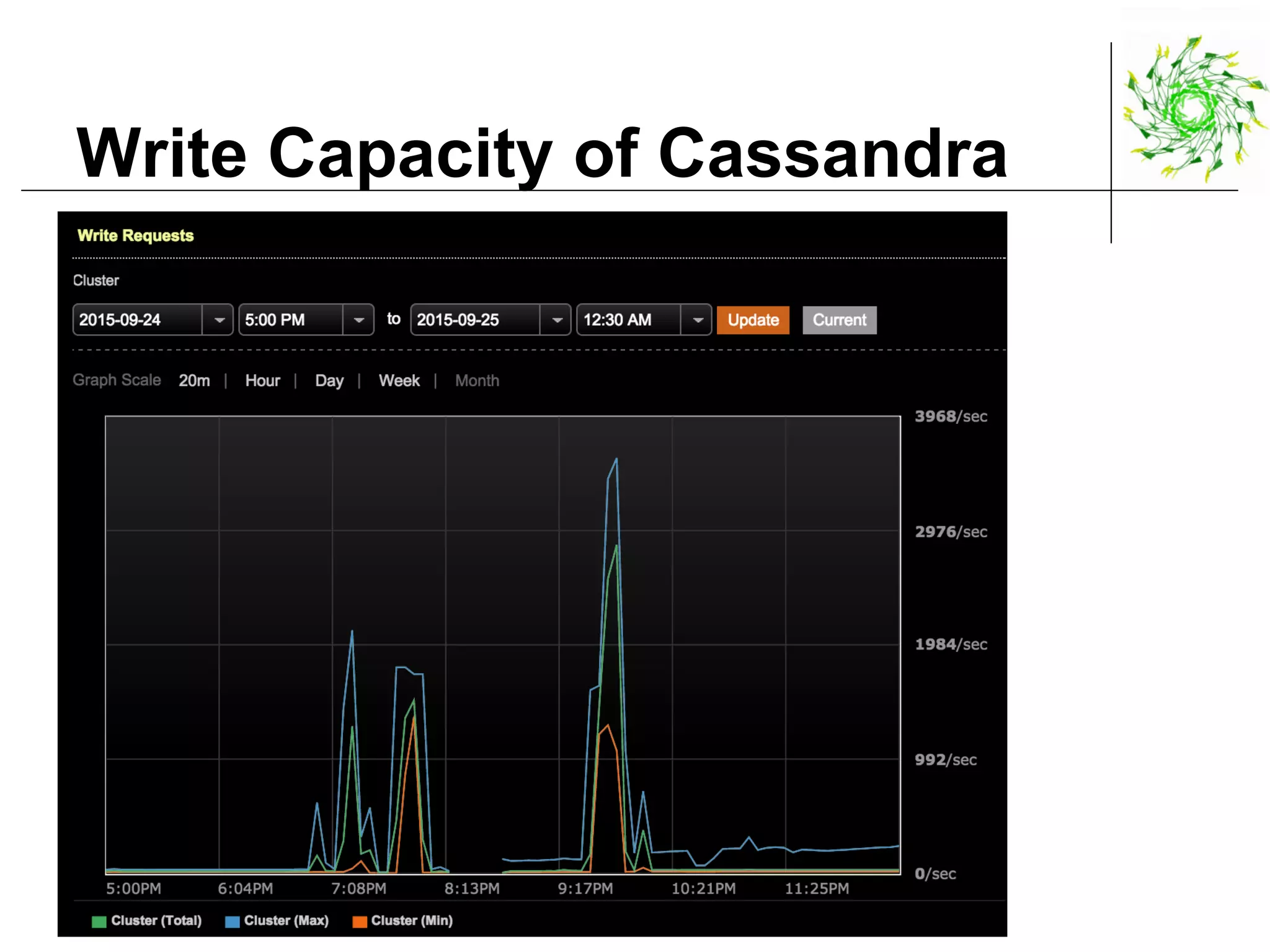

This document describes a data pipeline for processing large amounts of web crawl data from Common Crawl. It discusses ingesting over 160 TB of data per month from Common Crawl into AWS S3 storage and then using batch processing with T4 instances to index the data in Elasticsearch and store metadata in Cassandra. It also describes querying the hybrid database and some of the engineering challenges around approximating page rank with low latency.


















































































