Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Cloudera Japan
PDF, PPTX
17,020 views
Evolution of Impala #hcj2014
Hadoop Conference Japan 2014 で発表した、Impala の資料です。
Technology
◦
Read more
25
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 65
2
/ 65
3
/ 65
4
/ 65
5
/ 65
6
/ 65
7
/ 65
8
/ 65
9
/ 65
10
/ 65
11
/ 65
12
/ 65
13
/ 65
14
/ 65
15
/ 65
16
/ 65
17
/ 65
18
/ 65
19
/ 65
20
/ 65
21
/ 65
22
/ 65
23
/ 65
24
/ 65
25
/ 65
26
/ 65
27
/ 65
28
/ 65
29
/ 65
30
/ 65
31
/ 65
32
/ 65
33
/ 65
34
/ 65
35
/ 65
36
/ 65
37
/ 65
38
/ 65
39
/ 65
40
/ 65
41
/ 65
42
/ 65
43
/ 65
44
/ 65
45
/ 65
46
/ 65
47
/ 65
48
/ 65
49
/ 65
50
/ 65
51
/ 65
52
/ 65
53
/ 65
54
/ 65
55
/ 65
56
/ 65
57
/ 65
58
/ 65
59
/ 65
60
/ 65
61
/ 65
62
/ 65
63
/ 65
64
/ 65
65
/ 65
More Related Content
PPTX
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
PPTX
Impala 2.0 Update 日本語版 #impalajp
by
Cloudera Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PDF
[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...
by
Insight Technology, Inc.
PDF
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
PDF
Impala概要 道玄坂LT祭り 20150312 #dogenzakalt
by
Cloudera Japan
PDF
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
PDF
CDH5最新情報 #cwt2013
by
Cloudera Japan
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
Impala 2.0 Update 日本語版 #impalajp
by
Cloudera Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...
by
Insight Technology, Inc.
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
Impala概要 道玄坂LT祭り 20150312 #dogenzakalt
by
Cloudera Japan
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
CDH5最新情報 #cwt2013
by
Cloudera Japan
What's hot
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
Cloudera Impalaをサービスに組み込むときに苦労した話
by
Yukinori Suda
PDF
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
PDF
HBase at LINE
by
Shun Nakamura
PDF
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PPTX
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
PDF
HDFS HA セミナー #hadoop
by
Cloudera Japan
PDF
Impalaチューニングポイントベストプラクティス
by
Yahoo!デベロッパーネットワーク
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
PDF
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
PDF
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
PPTX
HBase×Impalaで作るアドテク 「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
by
Michio Katano
PDF
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
PDF
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
PDF
CDH4.1オーバービュー
by
Cloudera Japan
PDF
Cloudera impalaの性能評価(Hiveとの比較)
by
Yukinori Suda
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
Cloudera Impalaをサービスに組み込むときに苦労した話
by
Yukinori Suda
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
HBase at LINE
by
Shun Nakamura
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
HDFS HA セミナー #hadoop
by
Cloudera Japan
Impalaチューニングポイントベストプラクティス
by
Yahoo!デベロッパーネットワーク
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
HBase×Impalaで作るアドテク 「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
by
Michio Katano
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
CDH4.1オーバービュー
by
Cloudera Japan
Cloudera impalaの性能評価(Hiveとの比較)
by
Yukinori Suda
Similar to Evolution of Impala #hcj2014
PDF
基礎から学ぶ超並列SQLエンジンImpala #cwt2015
by
Cloudera Japan
PDF
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
PDF
CDHの歴史とCDH5新機能概要 #at_tokuben
by
Cloudera Japan
PDF
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
PDF
株式会社インタースペース 守安様 登壇資料
by
leverages_event
PDF
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PDF
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
PPTX
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
PDF
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
PDF
[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎
by
Insight Technology, Inc.
PPTX
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
PDF
C5.2 (Cloudera Manager + CDH) アップデート #cwt2014
by
Cloudera Japan
PDF
Hive chapter 2
by
masahiro_minami
PDF
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
PDF
OLAP options on Hadoop
by
Yuta Imai
PDF
Cloudera Impala #pyfes 2012.11.24
by
Sho Shimauchi
PDF
HBase活用事例 #hbase_ca
by
Cloudera Japan
PDF
Cloudera impala
by
外道 父
基礎から学ぶ超並列SQLエンジンImpala #cwt2015
by
Cloudera Japan
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
CDHの歴史とCDH5新機能概要 #at_tokuben
by
Cloudera Japan
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
株式会社インタースペース 守安様 登壇資料
by
leverages_event
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎
by
Insight Technology, Inc.
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
C5.2 (Cloudera Manager + CDH) アップデート #cwt2014
by
Cloudera Japan
Hive chapter 2
by
masahiro_minami
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
OLAP options on Hadoop
by
Yuta Imai
Cloudera Impala #pyfes 2012.11.24
by
Sho Shimauchi
HBase活用事例 #hbase_ca
by
Cloudera Japan
Cloudera impala
by
外道 父
More from Cloudera Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PDF
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PDF
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
PDF
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PDF
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PDF
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
PDF
Ibis: すごい pandas ⼤規模データ分析もらっくらく #summerDS
by
Cloudera Japan
PDF
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PDF
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
PDF
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
PPTX
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
Ibis: すごい pandas ⼤規模データ分析もらっくらく #summerDS
by
Cloudera Japan
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
HBase Across the World #LINE_DM
by
Cloudera Japan
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Evolution of Impala #hcj2014
1.
1 Evolu(on of
Impala Sho Shimauchi, Cloudera 2014/07/08
2.
2 今日のトピック •
Cloudera Impala とは? • クエリ言語とユーザビリティ • メタデータ管理 • UDF • リソース管理 • アドミッションコントロール • YARN と Llama (ラマ) • セキュリティ (Apache Sentry) • パフォーマンスと最適化 • HDFS • Parquet • ロードマップ
3.
3 Who am
I? • 嶋内 翔(しまうち しょう) • プロアクティブサポートエンジニア • 2011年4月にClouderaの最初の日本人社員として入 社 • email: sho@cloudera.com • twiUer: @shiumachi
4.
4 Cloudera Impala
5.
5 Cloudera Impala
とは? • Hadoop クラスタのための MPP SQL クエリエンジン • ハードウェア性能を最大に引き出すためネイティブ コードで記述 • オープンソース • hUp://impala.io/ • Cloudera / MapR / Amazon がサポートを提供 • 歴史 • 2012/10 パブリックベータリリース • 2013/04 Impala 1.0 リリース • 現在のバージョンは Impala 1.3.1
6.
6 Impala は使うのが簡単
• HDFS や HBase 上のデータに対し、仮想的なビューと してテーブルを作成することができる • スキーマは Hive メタストアに保存 • ODBC / JDBC で接続可能 • Kerberos / LDAP で認証可能 • 標準SQLを実行可能 • ANSI SQL-‐92 ベース • SELECT とバルクインサートに限定 • 相関サブクエリは未実装 (Impala 2.0 で実装予定) • UDF / UDAF に対応
7.
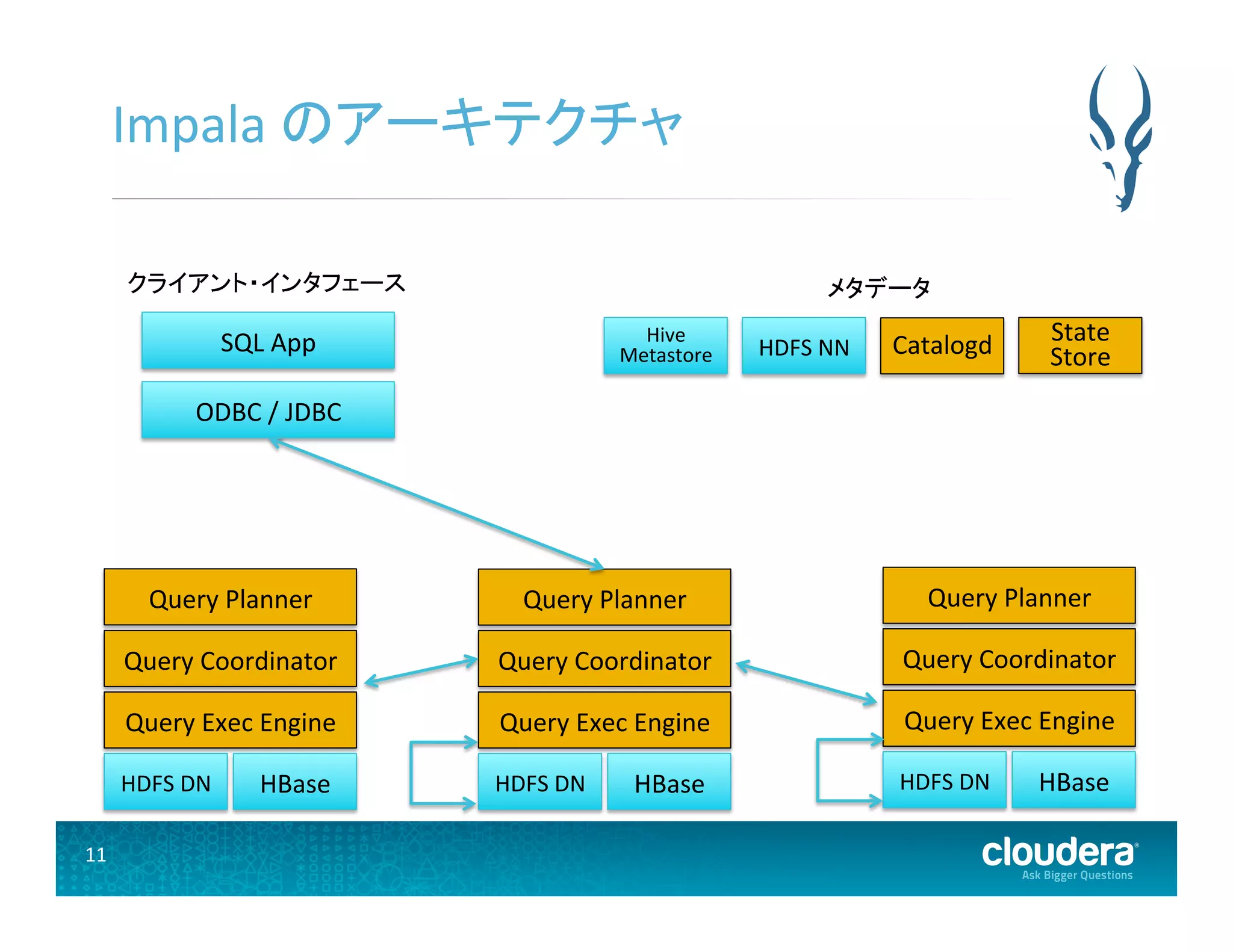
7 Impala のアーキテクチャ
• 分散サービス • コンポーネント • impalad • statestore • catalogd • インタフェース • impala-‐shell • ODBC / JDBC
8.
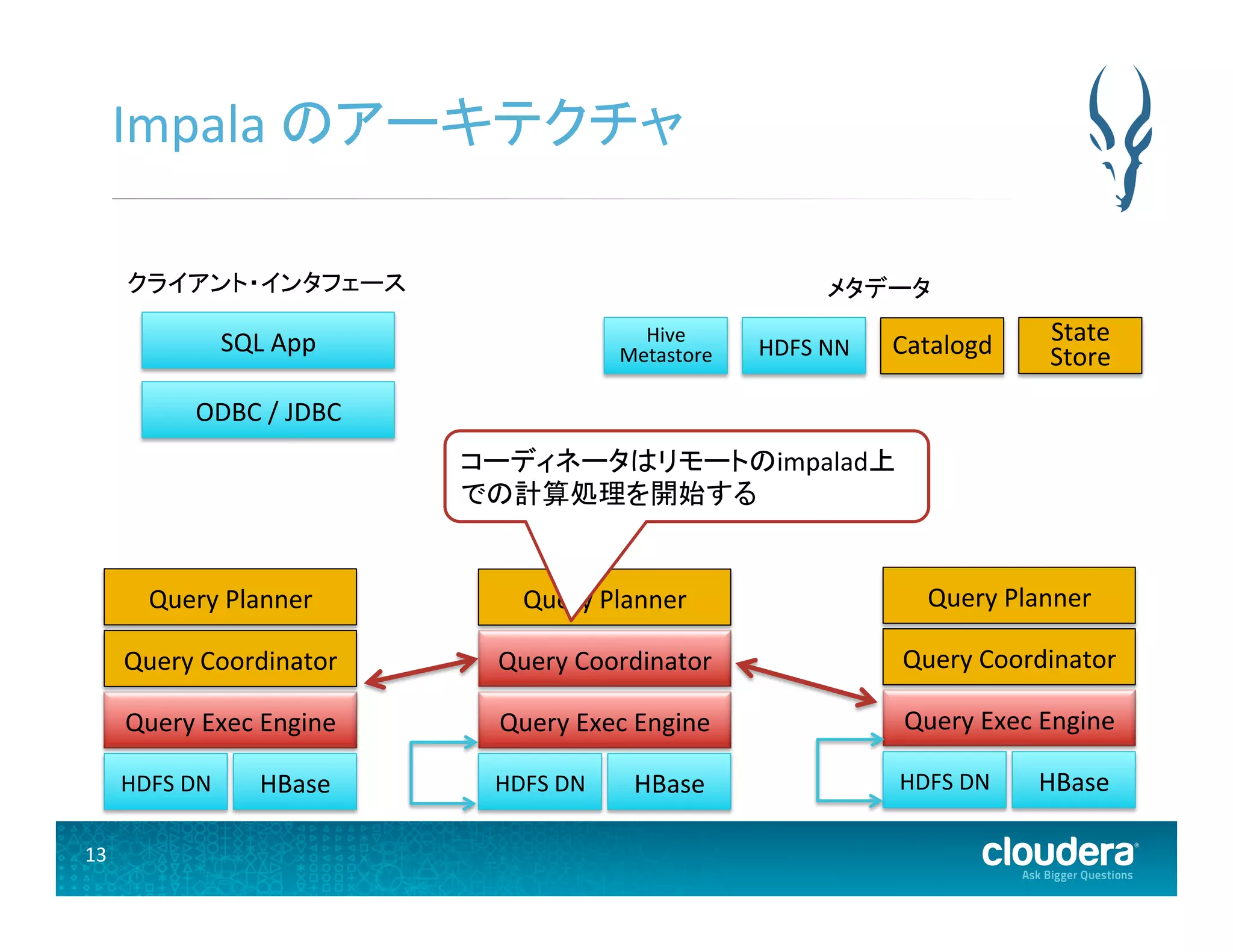
8 impalad •
データのあるノード全てで動作する • どの impalad でもユーザからのクエリを受け付けるこ とが可能 • クエリを受け付ける impalad は、通常「コーディネータノー ド」と呼ばれる • コーディネータノードは、リモートの impalad 上での 計算処理を開始する
9.
9 statestore •
ステートリポジトリ • ネームサービス • クラスタ毎に1ノード • ソフトステート • 起動時に全ての impalad はstatestoreに登録する • impalad への接続が切れたとき、statestore はその情報を 他の impalad へ周知する • Impala サービスは statestore がなくても動作継続する
10.
10 catalogd (Impala
1.2) • Impala SQL からクラスタ内の全ノードにメタデータの 変更をリレーする • クラスタ毎に1ノード • 詳細は後述
11.
11 Impala のアーキテクチャ
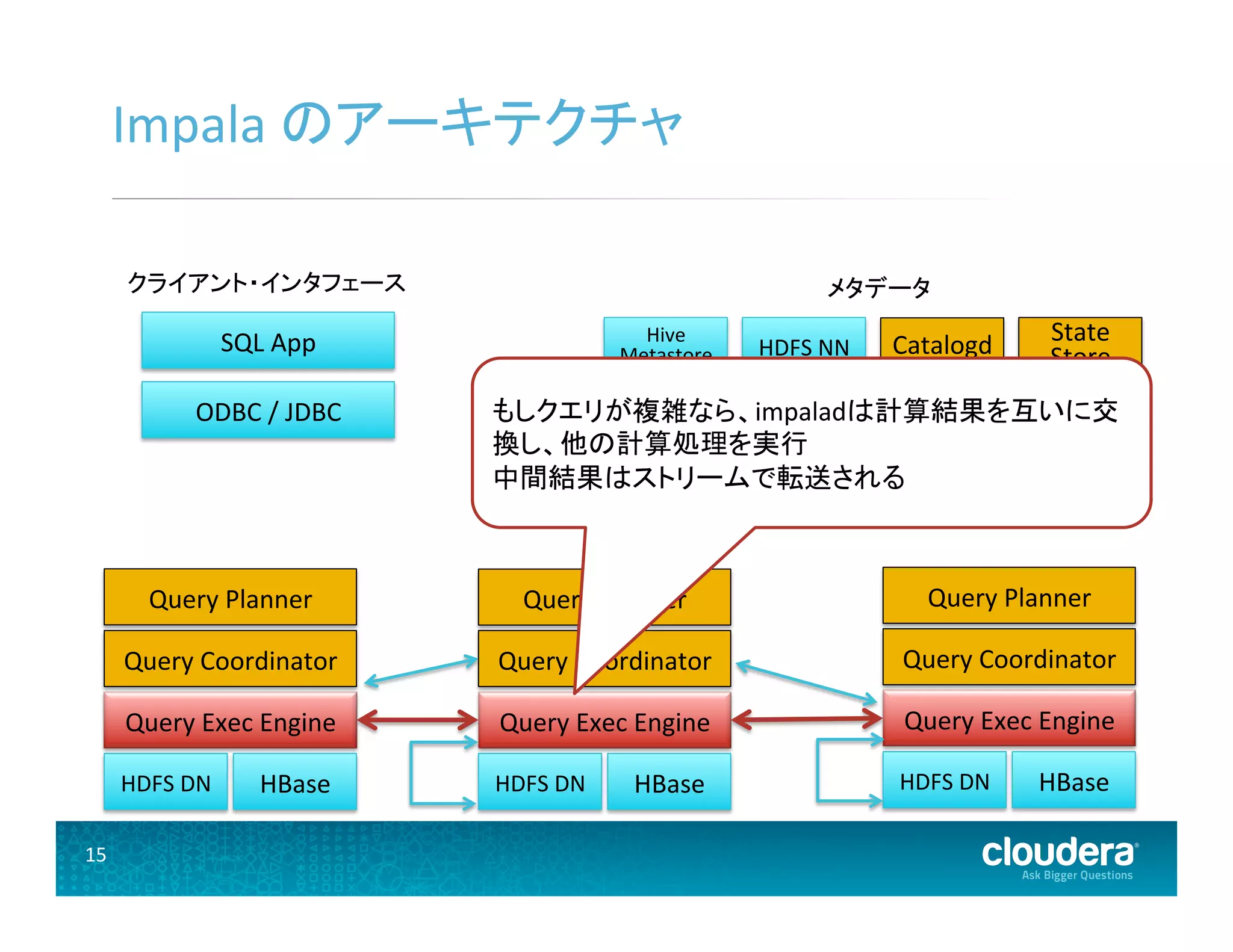
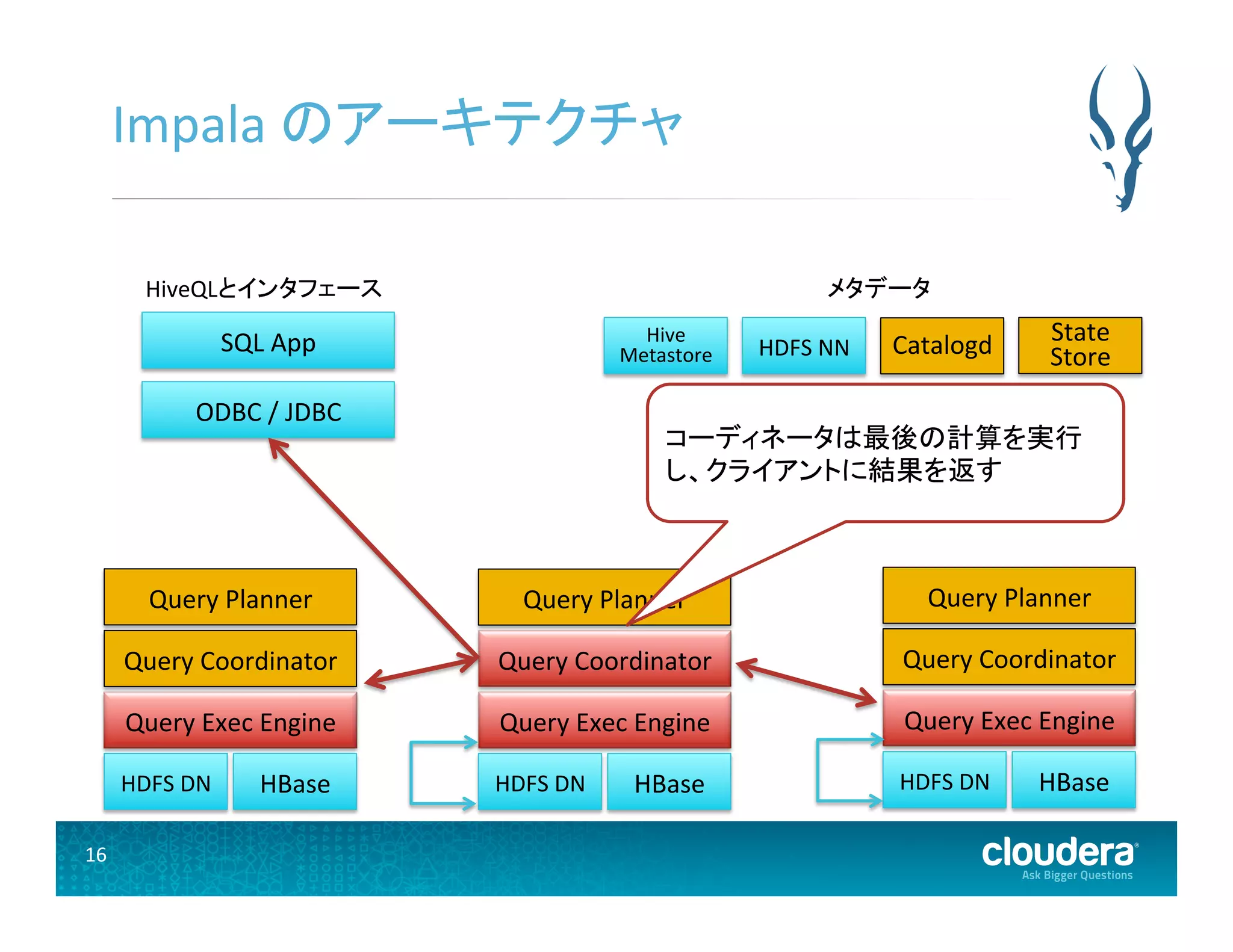
HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App クライアント・インタフェース メタデータ Hive Metastore HDFS NN State Store Catalogd
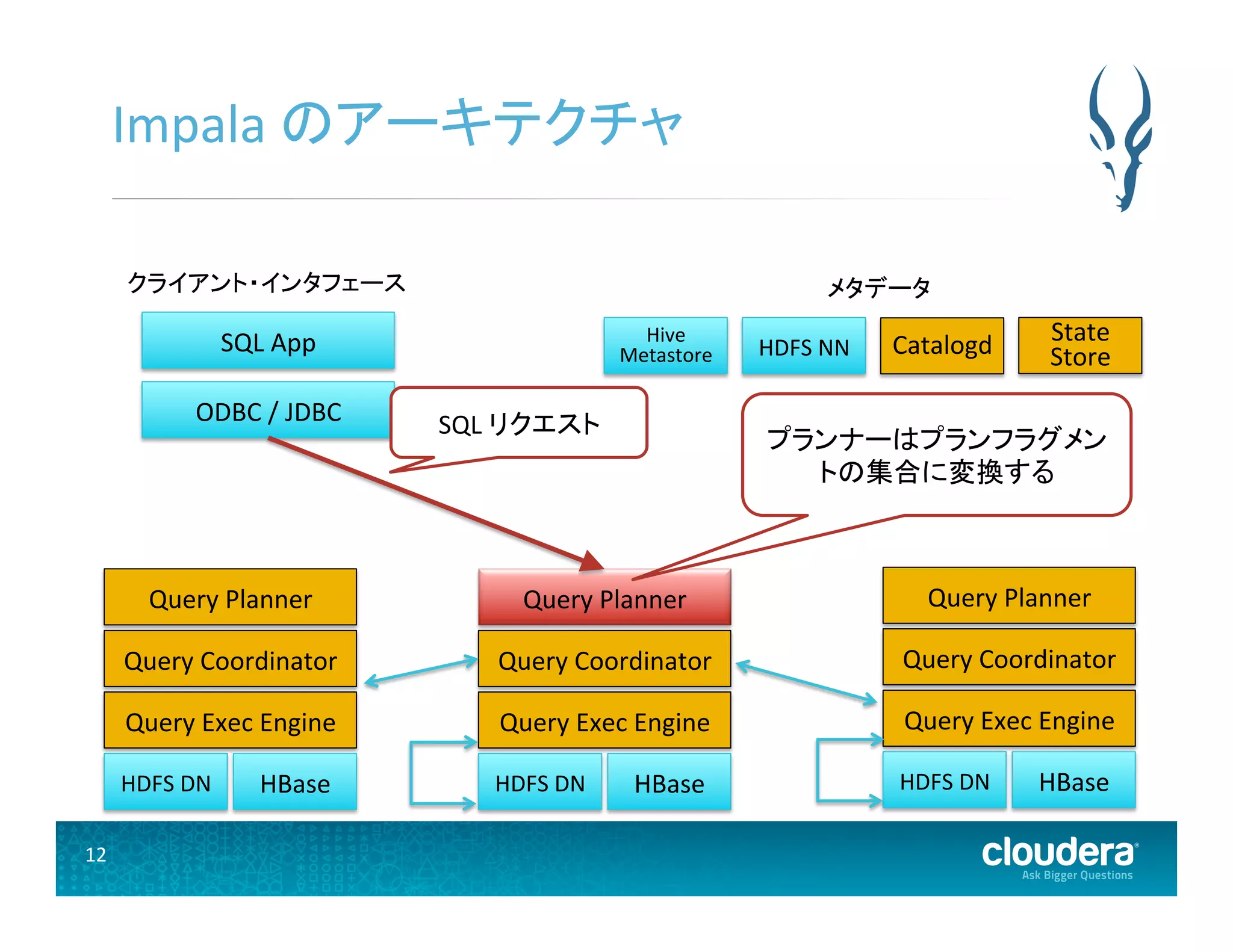
12.
12 Impala のアーキテクチャ
HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App メタデータ Hive Metastore HDFS NN State Store Catalogd SQL リクエスト プランナーはプランフラグメン トの集合に変換する クライアント・インタフェース
13.
13 Impala のアーキテクチャ
HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App メタデータ Hive Metastore HDFS NN State Store Catalogd コーディネータはリモートのimpalad上 での計算処理を開始する クライアント・インタフェース
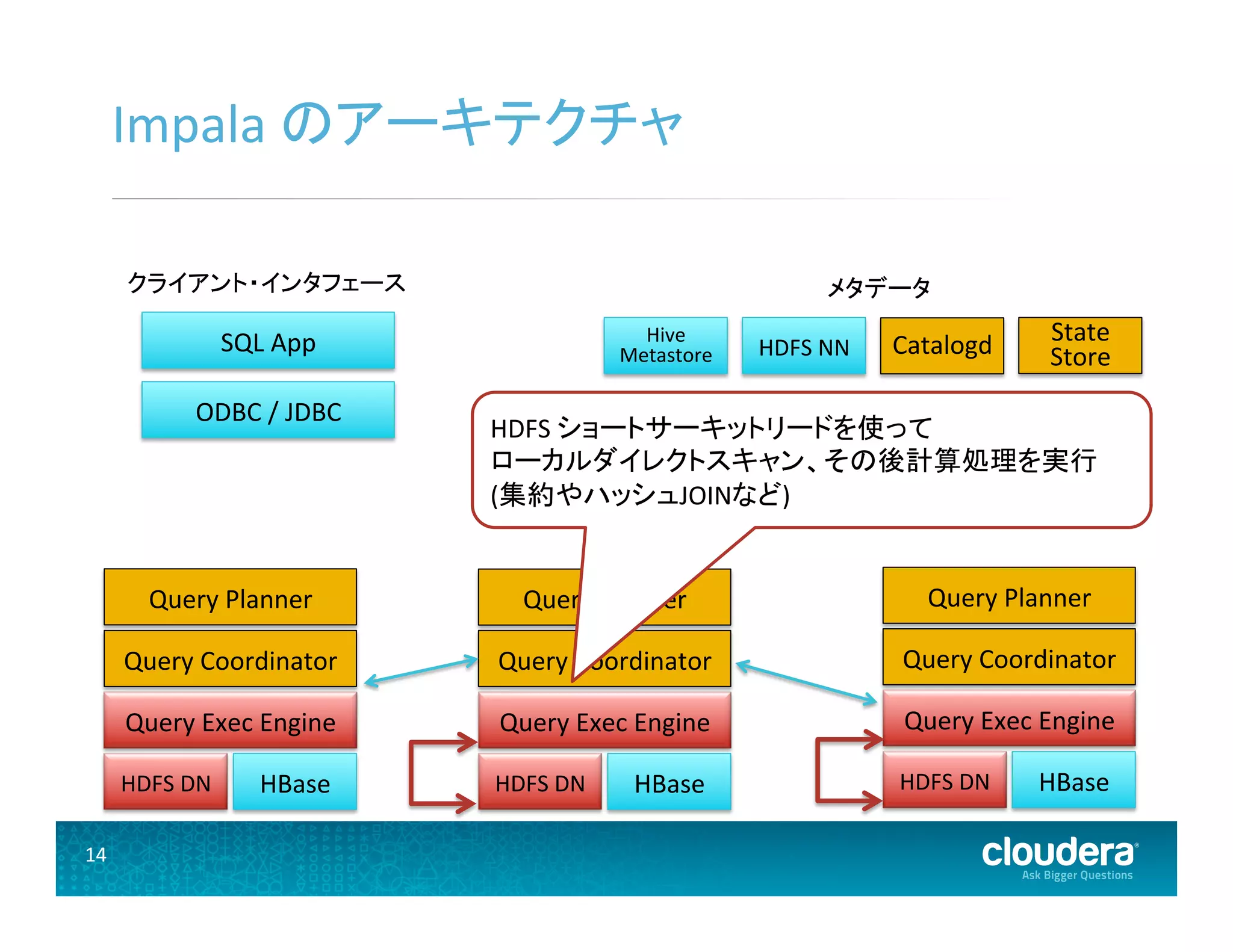
14.
14 Impala のアーキテクチャ
HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App メタデータ Hive Metastore HDFS NN State Store Catalogd HDFS ショートサーキットリードを使って ローカルダイレクトスキャン、その後計算処理を実行 (集約やハッシュJOINなど) クライアント・インタフェース
15.
15 Impala のアーキテクチャ
HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App メタデータ Hive Metastore HDFS NN State Store Catalogd もしクエリが複雑なら、impaladは計算結果を互いに交 換し、他の計算処理を実行 中間結果はストリームで転送される クライアント・インタフェース
16.
16 Impala のアーキテクチャ
HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App HiveQLとインタフェース メタデータ Hive Metastore HDFS NN State Store Catalogd コーディネータは最後の計算を実行 し、クライアントに結果を返す
17.
17 クエリ計画 •
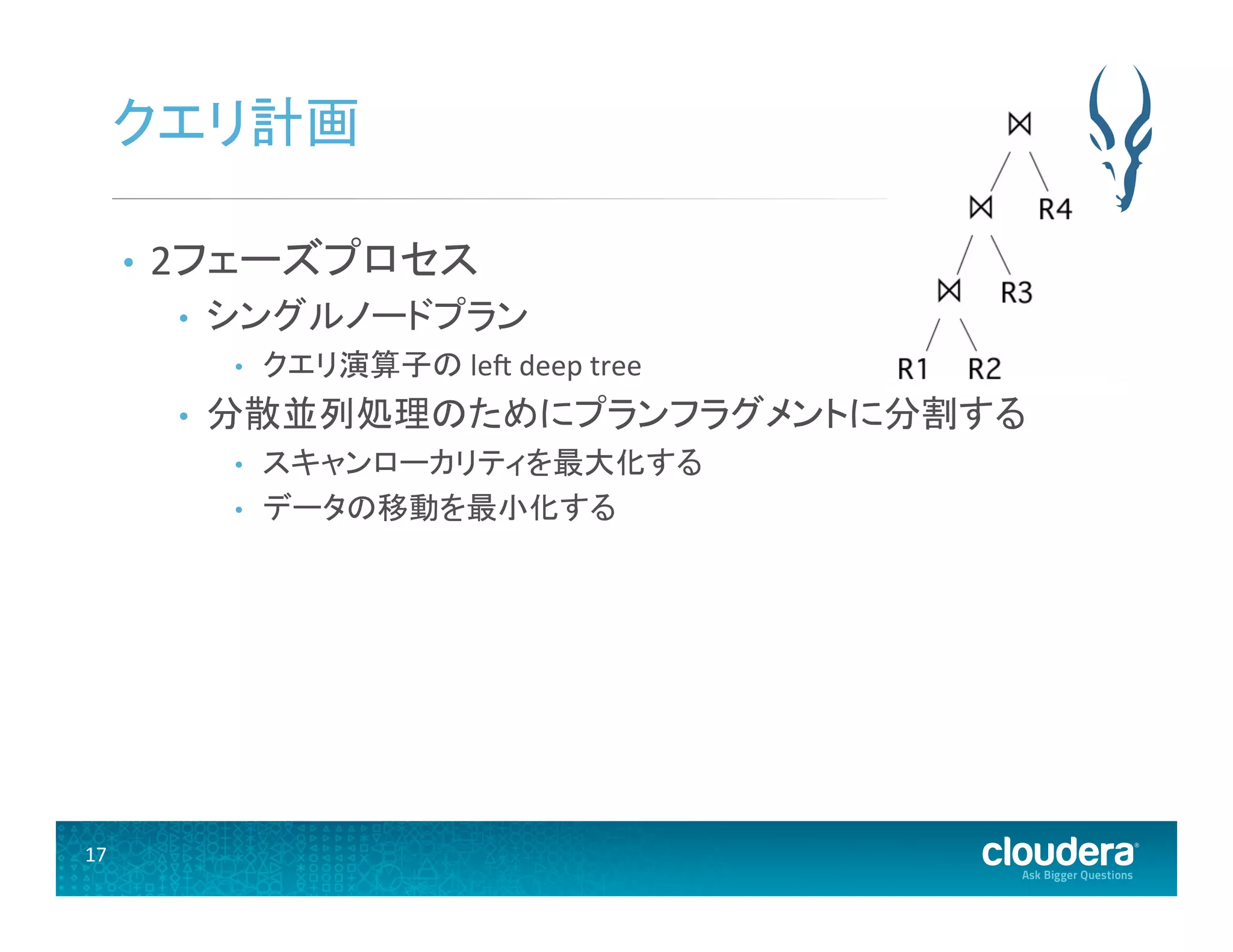
2フェーズプロセス • シングルノードプラン • クエリ演算子の lee deep tree • 分散並列処理のためにプランフラグメントに分割する • スキャンローカリティを最大化する • データの移動を最小化する
18.
18 クエリ計画 FRAGMENT
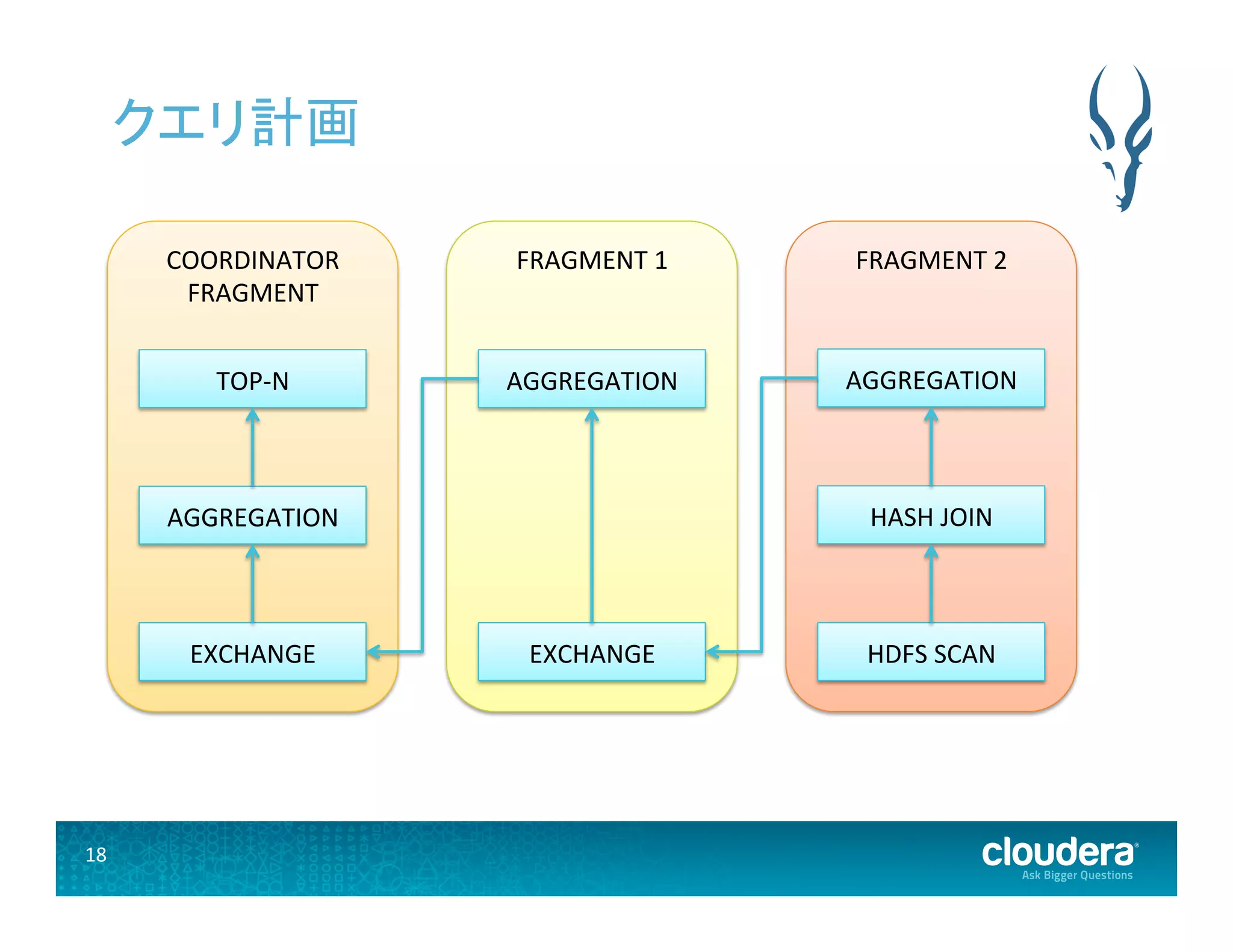
2 HDFS SCAN HASH JOIN AGGREGATION FRAGMENT 1 EXCHANGE AGGREGATION COORDINATOR FRAGMENT TOP-‐N EXCHANGE AGGREGATION
19.
19 クエリ実行 •
インメモリでの実行 • JOINの右側の入力をメモリにキャッシュし、結果を集約し ていく • 例: 1TB のテーブルを JOIN する。200列のうち2列を参照し、 行の10%を用いる • 1024 * (2 / 200) * 0.1 = 1GB を、全てのノード上のメモリにキャッ シュする必要がある • データはストリームで送信される • ディスクに書き出されることはない
20.
20 クエリ実行: ランタイムコード生成
• LLVMを使って、クエリのランタイム依存の部分をJITコ ンパイルする • クエリのカスタムコーディングと同じ効果がある • 分岐の削除 • 定数、オフセット、ポインタなどのプロパゲート • インライン関数呼び出し • 最近のCPUのための実行最適化(命令パイプライン)
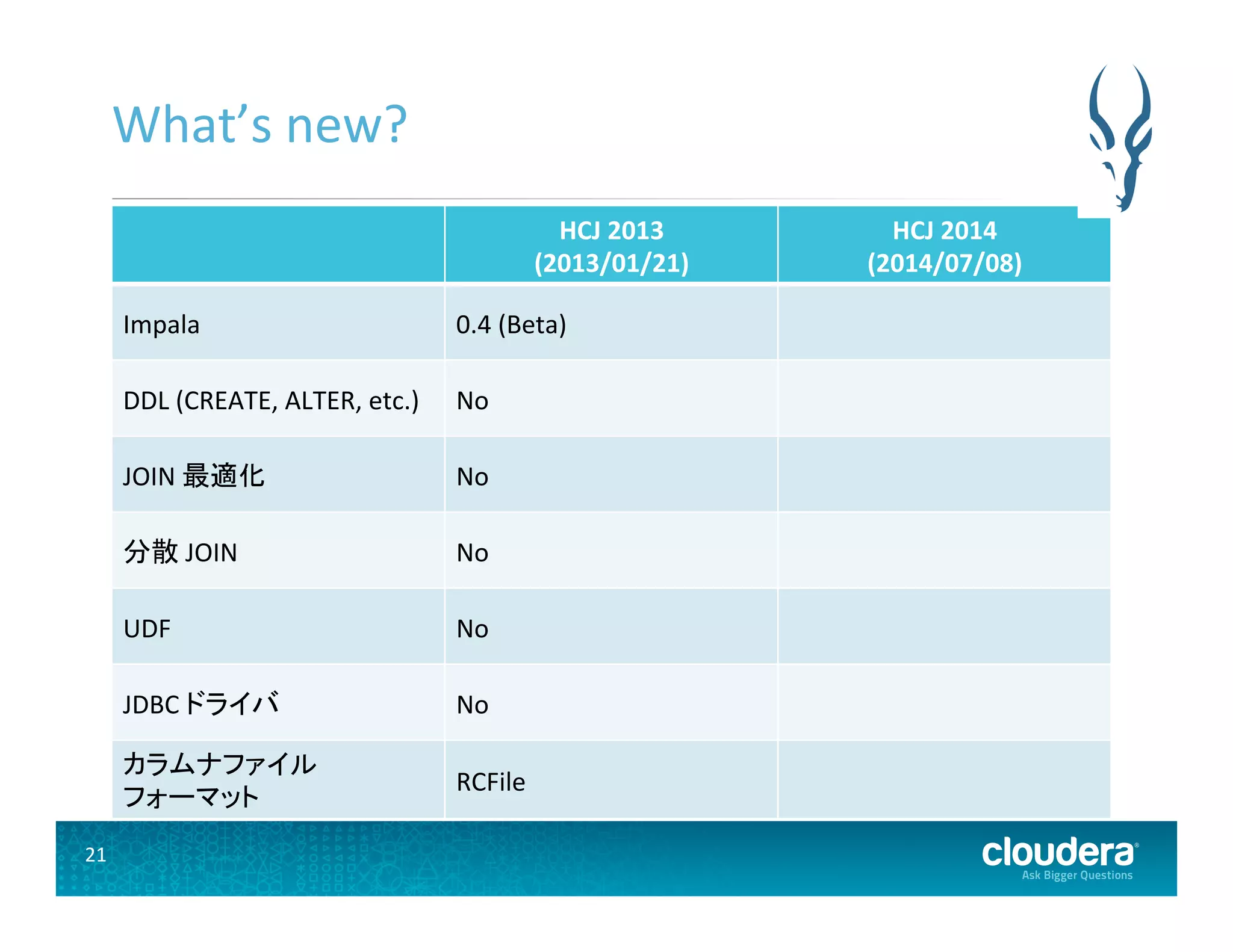
21.
21 What’s new?
HCJ 2013 (2013/01/21) HCJ 2014 (2014/07/08) Impala 0.4 (Beta) DDL (CREATE, ALTER, etc.) No JOIN 最適化 No 分散 JOIN No UDF No JDBC ドライバ No カラムナファイル フォーマット RCFile
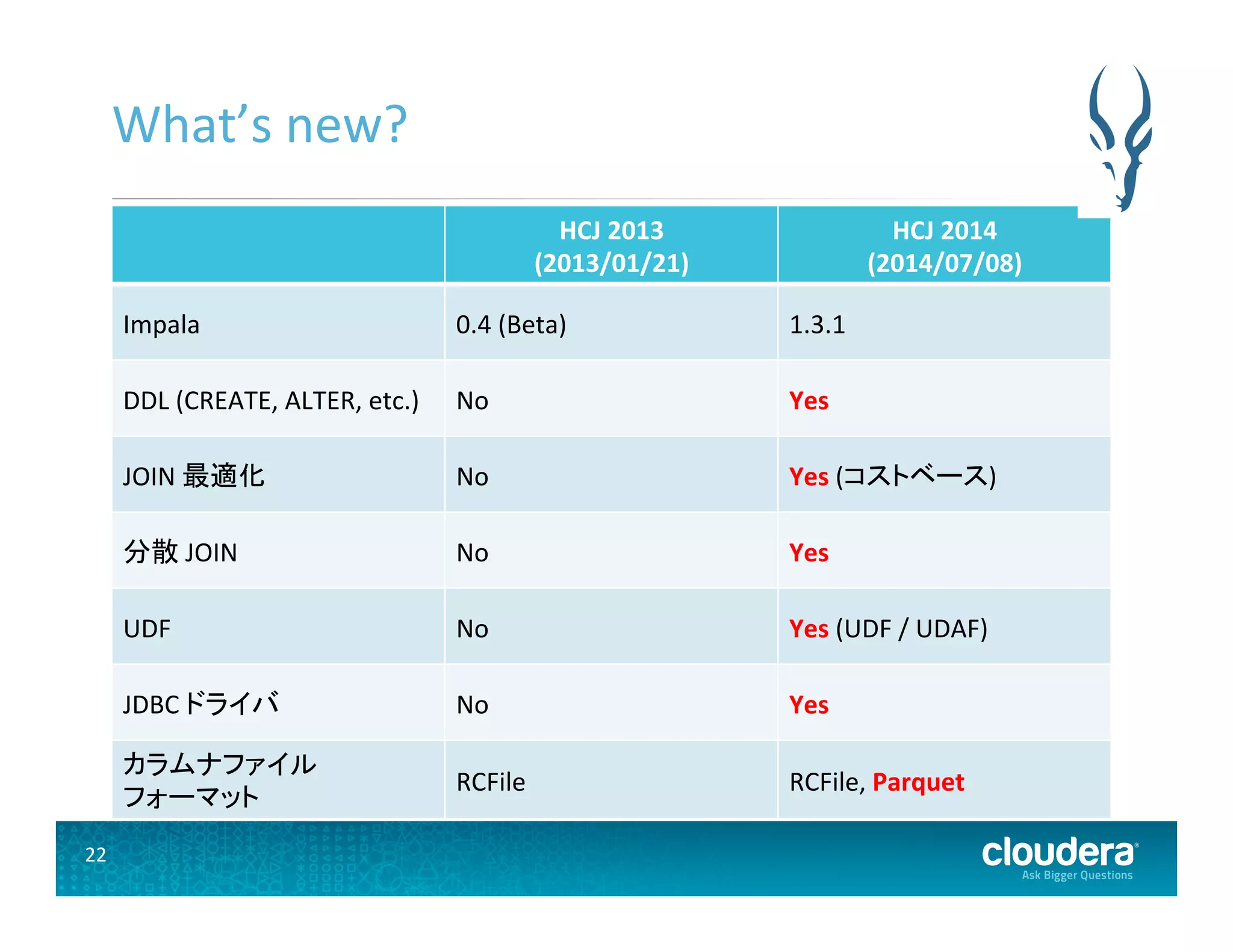
22.
22 What’s new?
HCJ 2013 (2013/01/21) HCJ 2014 (2014/07/08) Impala 0.4 (Beta) 1.3.1 DDL (CREATE, ALTER, etc.) No Yes JOIN 最適化 No Yes (コストベース) 分散 JOIN No Yes UDF No Yes (UDF / UDAF) JDBC ドライバ No Yes カラムナファイル フォーマット RCFile RCFile, Parquet
23.
23 クエリ言語とユーザビリティ
24.
24 メタデータ管理 •
catalogd (Impala 1.2) • Impala SQL からクラスタ内の全ノードにメタデータの変更をリ レーする • クラスタ毎に1ノード • DDL(CREATE や DROP TABLEなど)の後に、 REFRESH や INVALIDATE METADATA を実行する必要がなくなった • HiveでDDLを実行した場合は引き続き実行が必要 • INVALIDATE METADATA new_table_name (Impala 1.2.4) • INVALIDATE METADATA はコスト高の処理 • このクエリにより指定したテーブルだけに実行することが可能
25.
25 UDF (ユーザ定義関数)
• Impala 1.1 / 1.2 からの新機能 • UDF と UDAF をサポート • 以下のUDFを作成可能 • C++ でネイティブコードを書く • Java で書かれた Hive UDF をポートする • Python UDF も開発中! • hUps://github.com/cloudera/impyla IntVal AddUdf (UdfContext* context, const IntVal& arg1, const IntVal& arg2) { if (arg1.is_null || arg2.is_null) { return IntVal::null(); } return IntVal(arg1.val + arg2.val) }
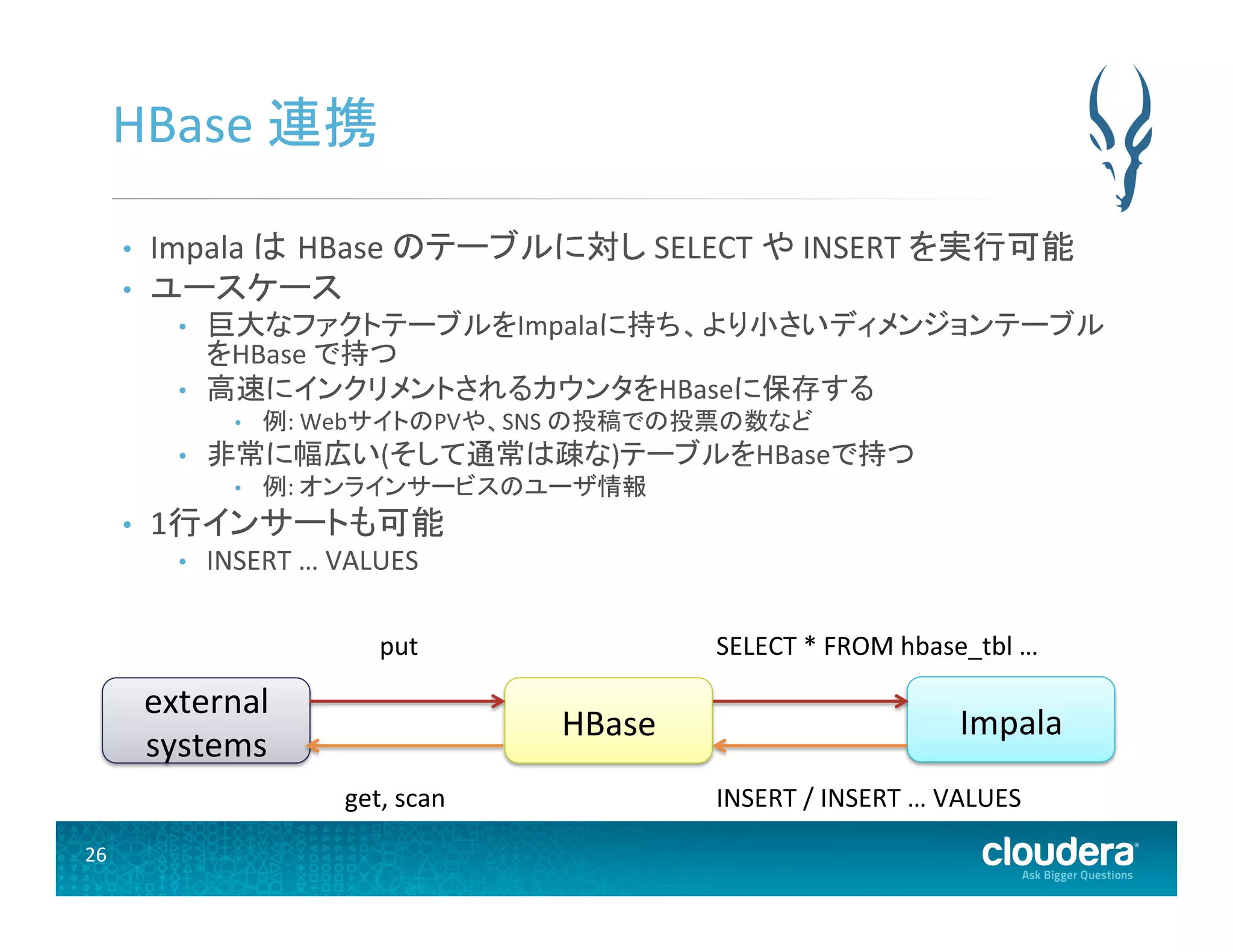
26.
26 HBase 連携
• Impala は HBase のテーブルに対し SELECT や INSERT を実行可能 • ユースケース • 巨大なファクトテーブルをImpalaに持ち、より小さいディメンジョンテーブル をHBase で持つ • 高速にインクリメントされるカウンタをHBaseに保存する • 例: WebサイトのPVや、SNS の投稿での投票の数など • 非常に幅広い(そして通常は疎な)テーブルをHBaseで持つ • 例: オンラインサービスのユーザ情報 • 1行インサートも可能 • INSERT … VALUES Impala HBase external systems put SELECT * FROM hbase_tbl … INSERT / INSERT … VALUES get, scan
27.
27 リソース管理
28.
28 アドミッションコントロール (Impala
1.3) • 高速・軽量なリソース管理機構 • 並列ワークロードに対するリソースの過剰利用を避 ける • 設定した限界値を超えたらクエリはキューイングされる • 全 impalad で動作 • SPOF なし
29.
29 アドミッションコントロール (Impala
1.3) • 設定可能なリソースプール • クエリの最大並列実行数 • キューの最大長 • プールのメモリ総量 • 設定方法は2通り • Cloudera Manager の「動的リソースプール」 • fair-‐scheduler.xml と llama-‐site.xml を手動編集する
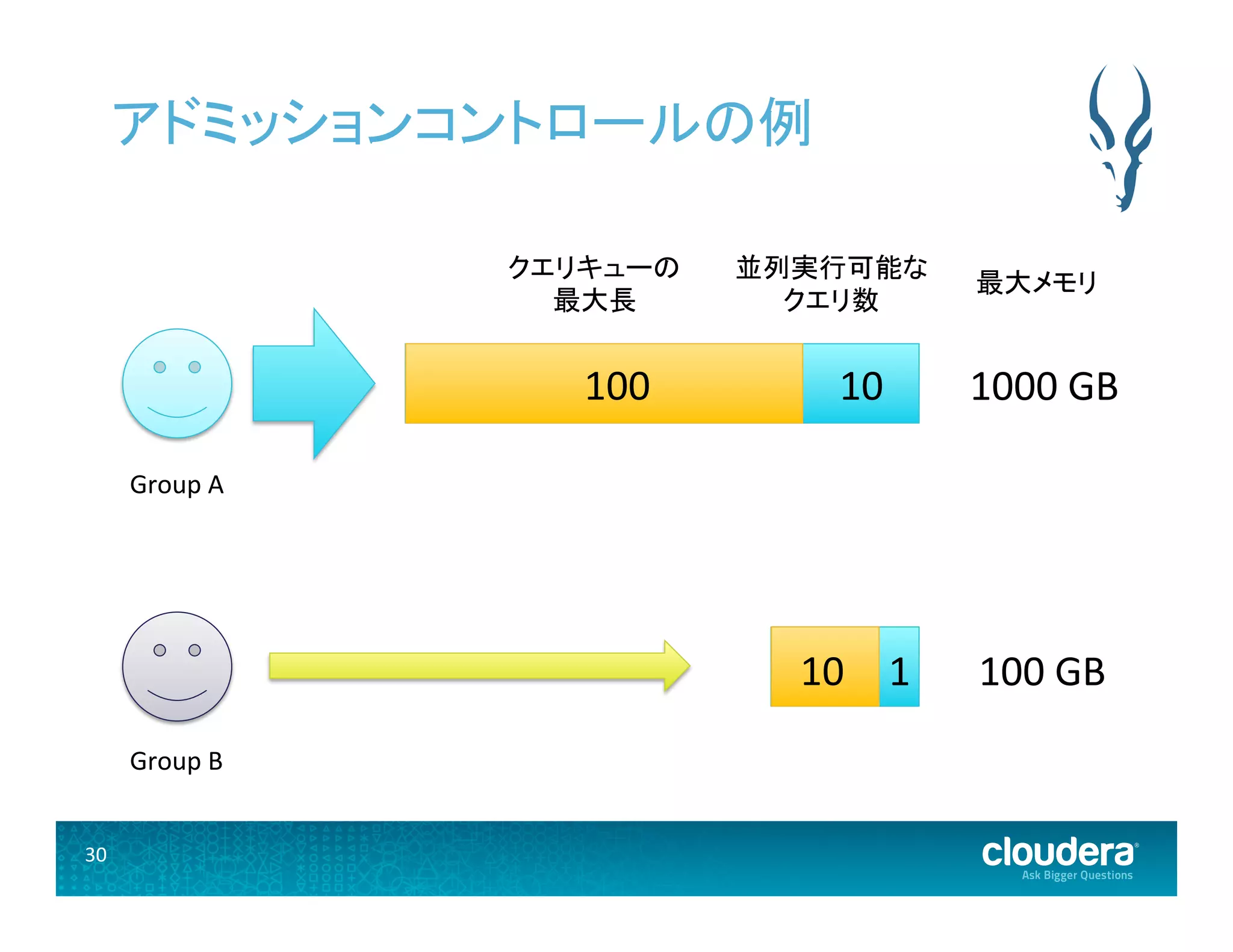
30.
30 アドミッションコントロールの例 並列実行可能な
クエリ数 クエリキューの 最大長 100 10 10 1 最大メモリ 1000 GB 100 GB Group A Group B
31.
31 アドミッションコントロール (Impala
1.3) • 制限は「ソフトリミット」 • 実行可能クエリ数の最大値を少しだけオーバーすること がある • クエリを statestore のハートビート間隔(500ms)より速い間 隔で送信していると発生する可能性がある
32.
32 YARN と
Llama (ラマ) • Llama: Low Latency Applica(on MAster • 低レイテンシ・短寿命のクエリで用いるために、粒度 の粗いYARNのスケジューリングをよりきめ細かくする • YARNプールごとに長寿命のAMを登録する • YARNから割り当てられたリソースを短時間キャッシュ する • Impala クエリに高速に再割り当てする • YARN を待つよりもはるかに高速 • Impala 1.3 ではベータ版 • Produc(on Ready in Impala 1.4
33.
33 セキュリティ
34.
34 34 Apache
Sentry • Apache Incubatorプロジェクト • オープンソースで開発 • Oracle社やCloudera社が主導 • データベース、テーブル、ビュー、列/行 の粒度でアクセス制御 • HiveやImpalaなど幅広いHadoop エコシステムで利用可能
35.
35 パフォーマンスと最適化
36.
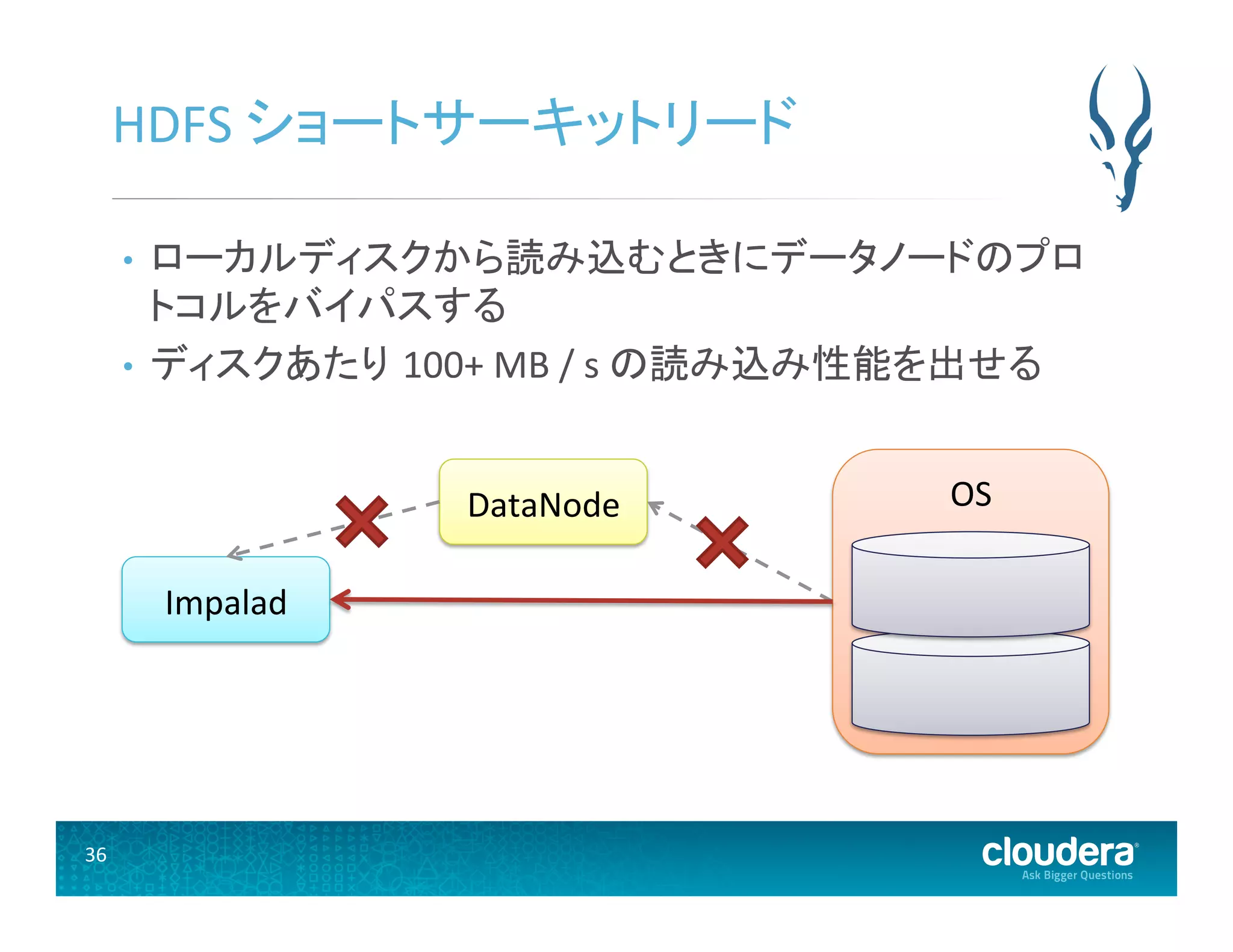
36 HDFS ショートサーキットリード
• ローカルディスクから読み込むときにデータノードのプロ トコルをバイパスする • ディスクあたり 100+ MB / s の読み込み性能を出せる Impalad DataNode OS
37.
37 HDFS キャッシング
• メモリ常駐データへのゼロオーバヘッドアクセス • チェックサム計算とデータコピーを回避する • 新しい HDFS API が CDH5.0 で導入された • Impala DDL でキャッシュ指定することが可能 (Impala 1.4) • CREATE TABLE tbl_name CACHED IN ‘<pool>’ • ALTER TABLE tbl_name ADD PARTITION … CACHED IN ‘<pool>’
38.
38 Parquet •
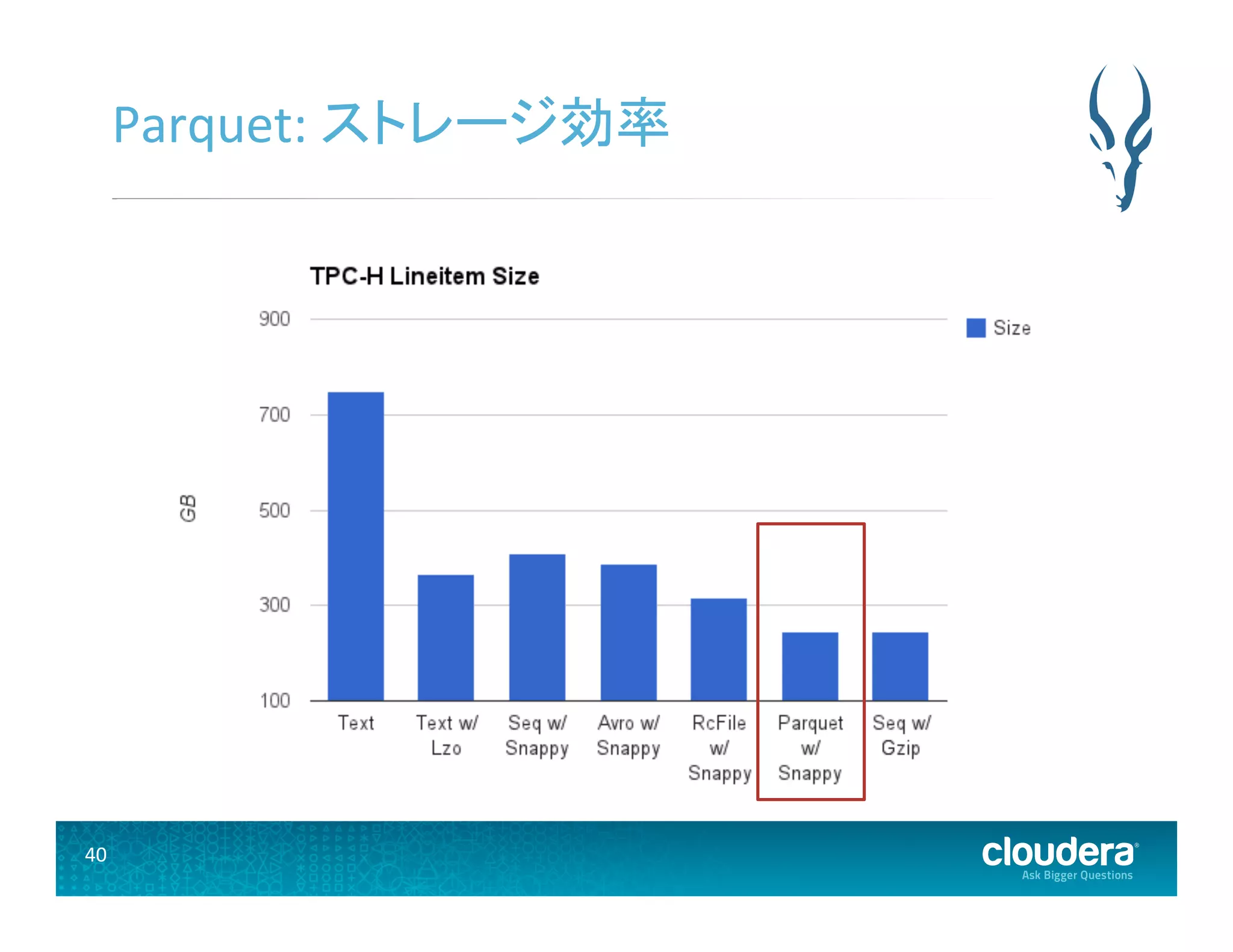
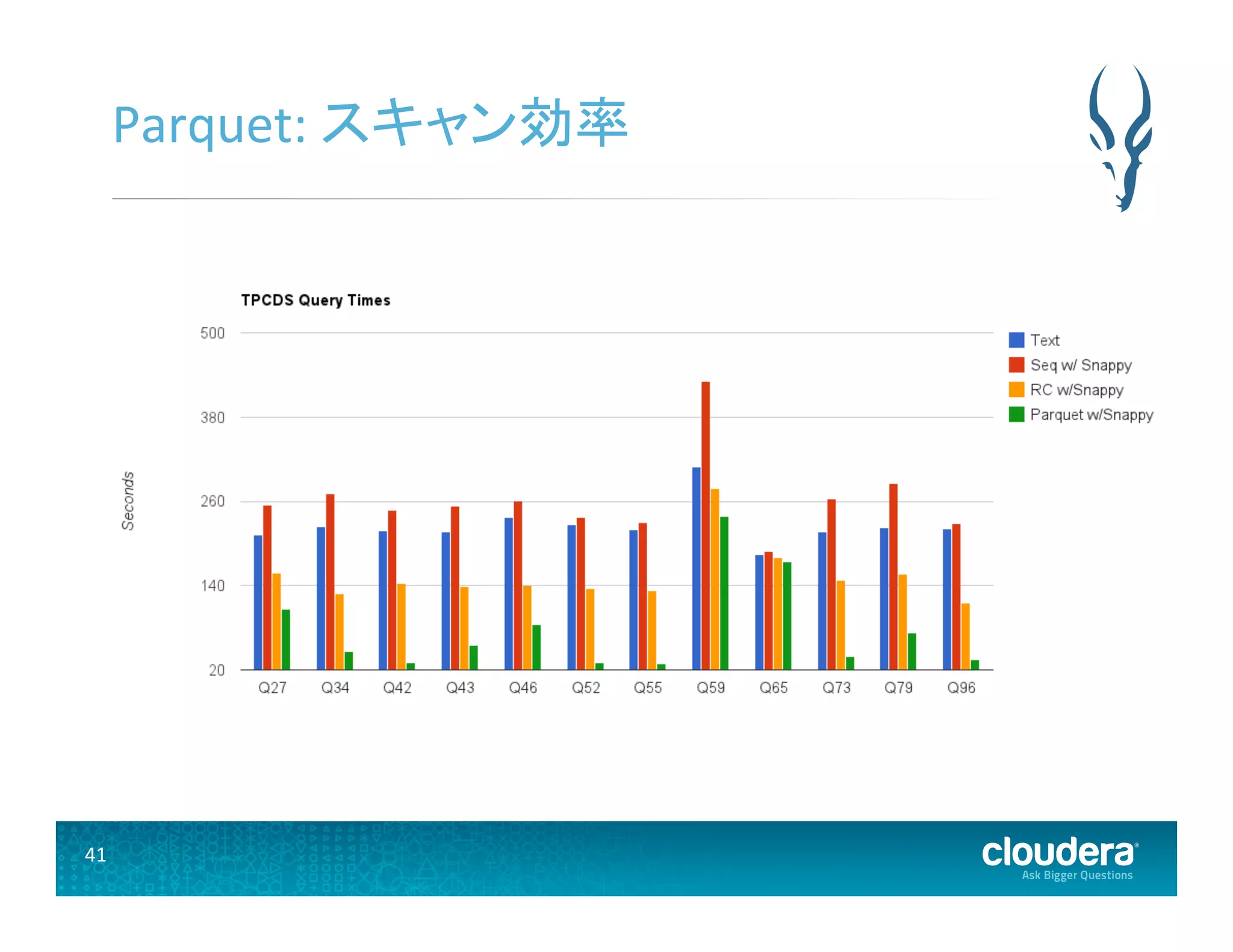
Hadoop 用カラムナストレージ • 多くの Hadoop エコシステムがサポートしている • Impala, Hive, Pig, MapReduce, Cascading • 高圧縮かつ高スキャン効率 • TwiUer と Cloudera の共同開発 • 2014年5月にApache インキュベータプロジェクトに なった • hUp://incubator.apache.org/projects/parquet.html • 現在のプロジェクトページ: hUp://parquet.io/
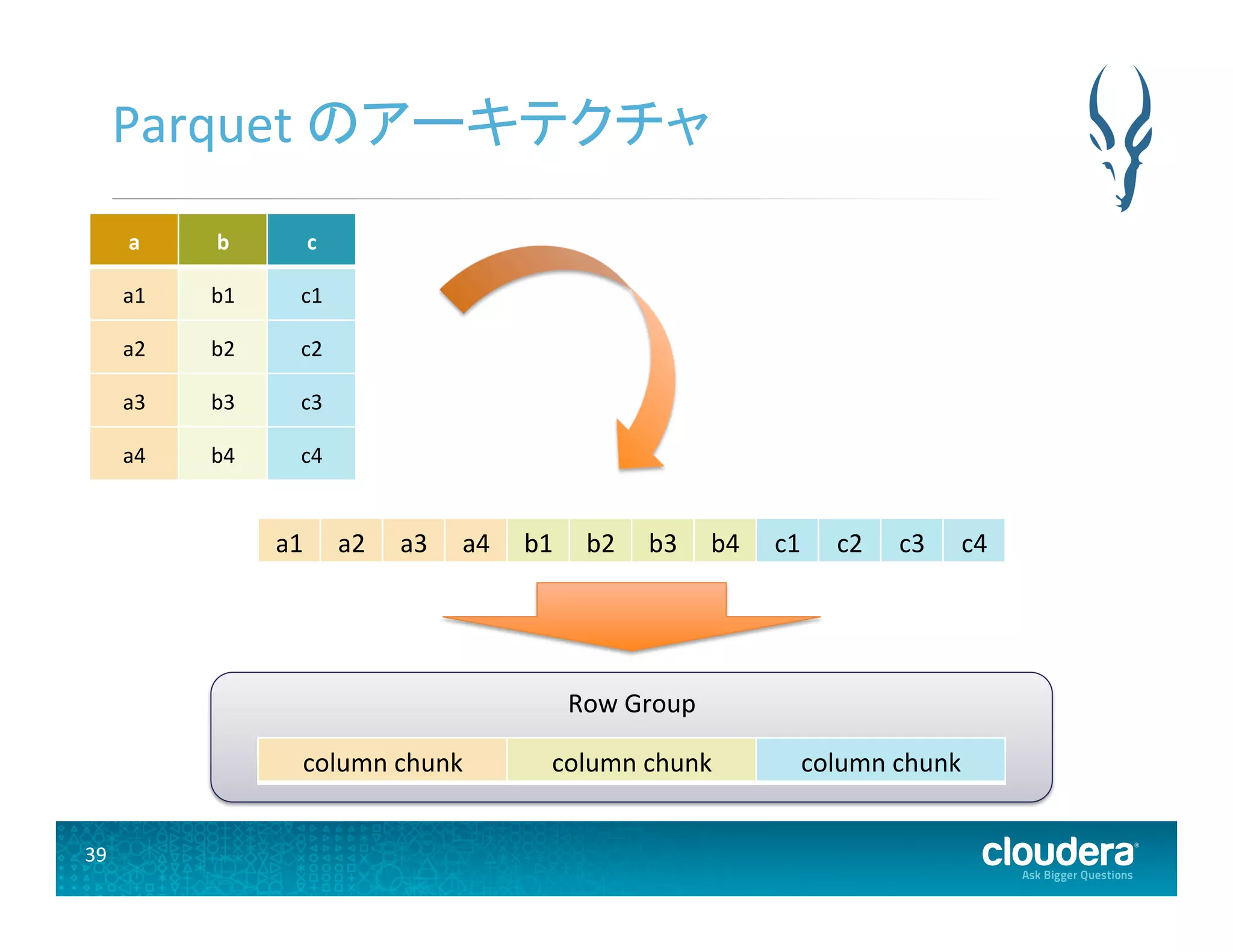
39.
39 Parquet のアーキテクチャ
a b c a1 b1 c1 a2 b2 c2 a3 b3 c3 a4 b4 c4 a1 a2 a3 a4 b1 b2 b3 b4 c1 c2 c3 c4 Row Group column chunk column chunk column chunk
40.
40 Parquet: ストレージ効率
41.
41 Parquet: スキャン効率
42.
42 COMPUTE STATS
(Impala 1.2.2) • テーブルや列の統計情報を収集し、メタストアに保存 する • ETL処理の終わりには必ず COMPUTE STATS を実行 しましょう • コストベースのJOIN順序の最適化 • JOINクエリの性能改善とメモリ使用量削減 • ParquetテーブルへのINSERTの性能改善とメモリ使用量削 減 • Impala 1.4 では COMPUTE STATS 自体が高速化
43.
43 Impala ベンチマーク
• TPC-‐DS を使ったベンチマーク • 21種類のクエリ • 15TB スケールファクタ―データセット • 21ノードクラスタ • Impala で TPC-‐DS を試したい人は以下のツールを使 うと楽 • hUps://github.com/cloudera/impala-‐tpcds-‐kit
44.
44 Impala ベンチマーク
Hardware # of nodes 21 CPU Intel Xeon CPU E5-‐2630L 0 at 2.00GHz 2 processors 12 cores disk 12 disks 932GB each OS: 1 disk HDFS: 11 disks memory 348GB So>ware Impala 1.3 Hive-‐on-‐Tez 13.0 Shark (RDD) 0.9.2 Shark (HDFS) 0.9.2 Presto 0.60
45.
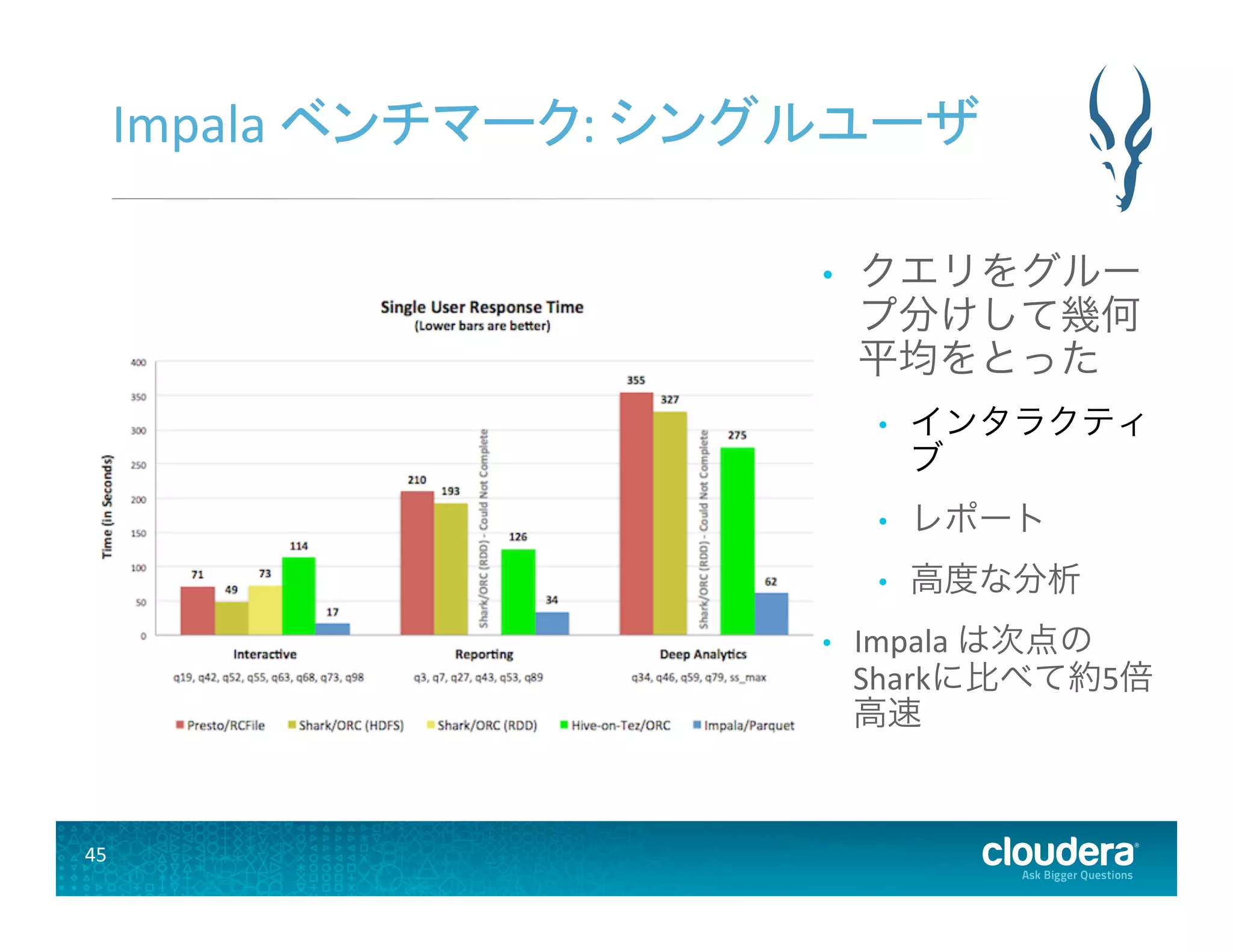
45 Impala ベンチマーク:
シングルユーザ • クエリをグルー プ分けして幾何 平均をとった • インタラクティ ブ • レポート • 高度な分析 • Impala は次点の Sharkに比べて約5倍 高速
46.
46 Impala ベンチマーク:
シングルユーザ • クエリをグルー プ分けして幾何 平均をとった • インタラクティ ブ • レポート • 高度な分析 • Impala は次点の Sharkに比べて約5倍 高速 17 34 62 49 193 327 Shark / ORC (HDFS) Impala
47.
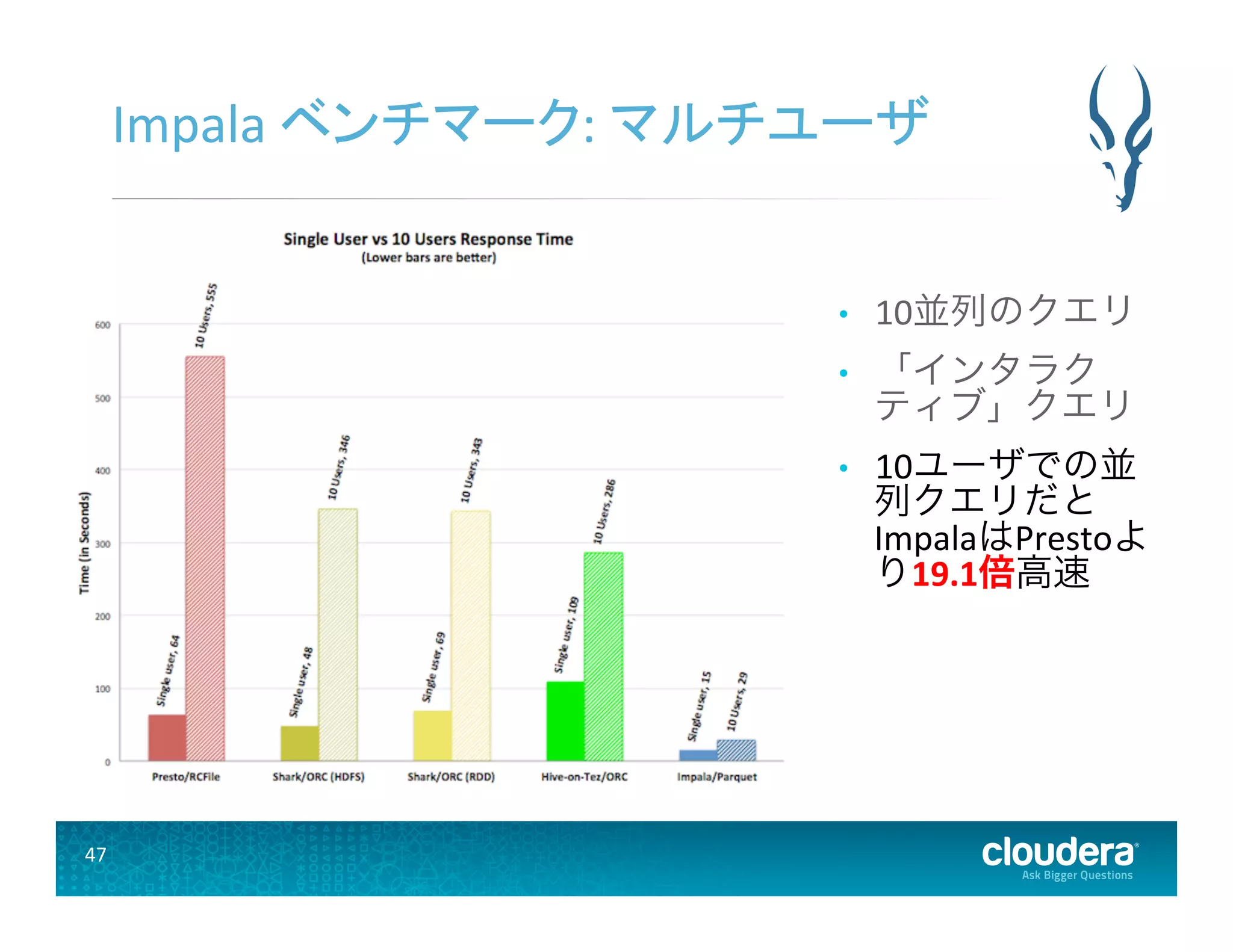
47 Impala ベンチマーク:
マルチユーザ • 10並列のクエリ • 「インタラク ティブ」クエリ • 10ユーザでの並 列クエリだと ImpalaはPrestoよ り19.1倍高速
48.
48 Impala ベンチマーク:
マルチユーザ • 10並列のクエリ • 「インタラク ティブ」クエリ • 10ユーザでの並 列クエリだと ImpalaはPrestoよ り19.1倍高速 Impala 1クエリ: 15 10並列: 29 Presto 1クエリ: 64 10並列: 555
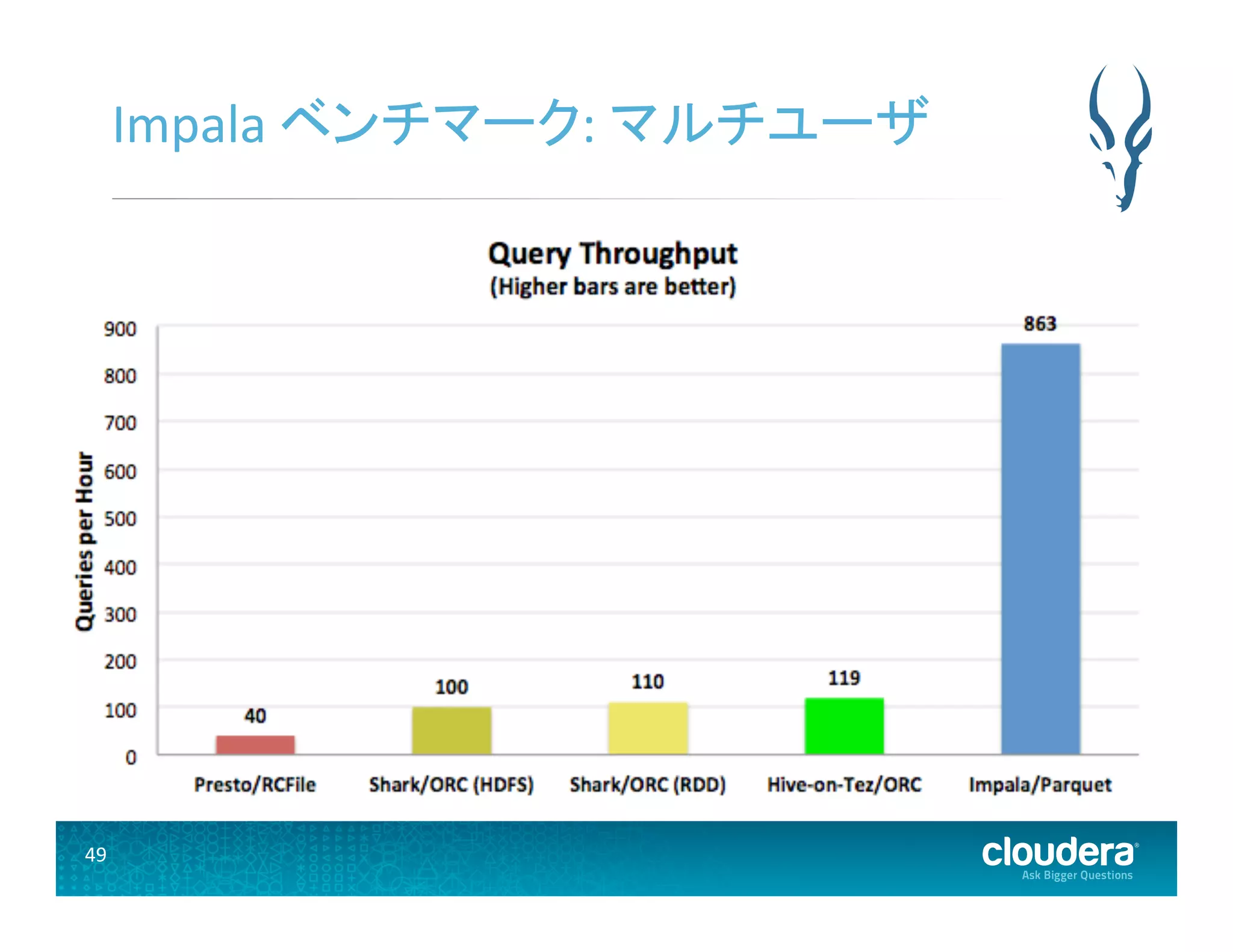
49.
49 Impala ベンチマーク:
マルチユーザ
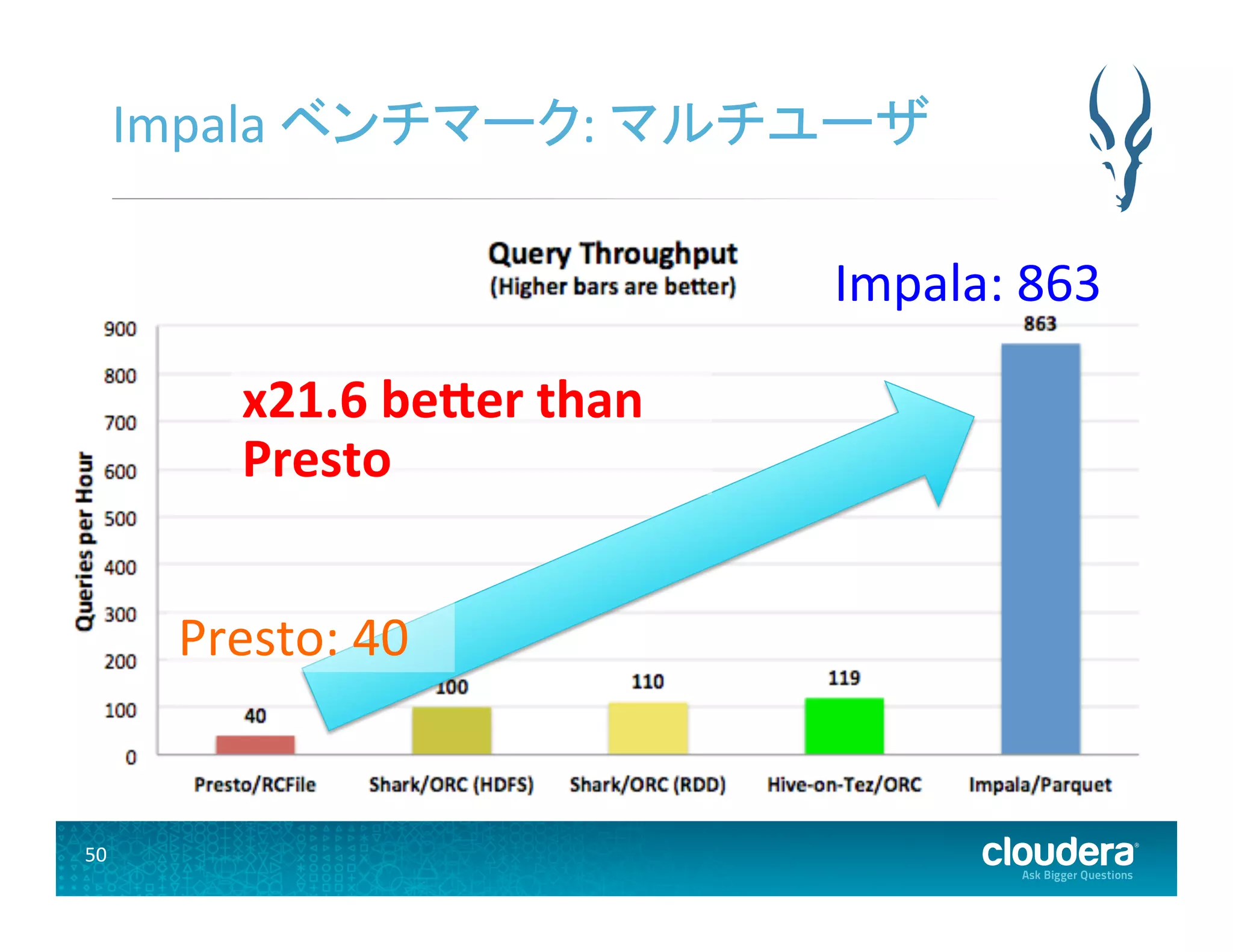
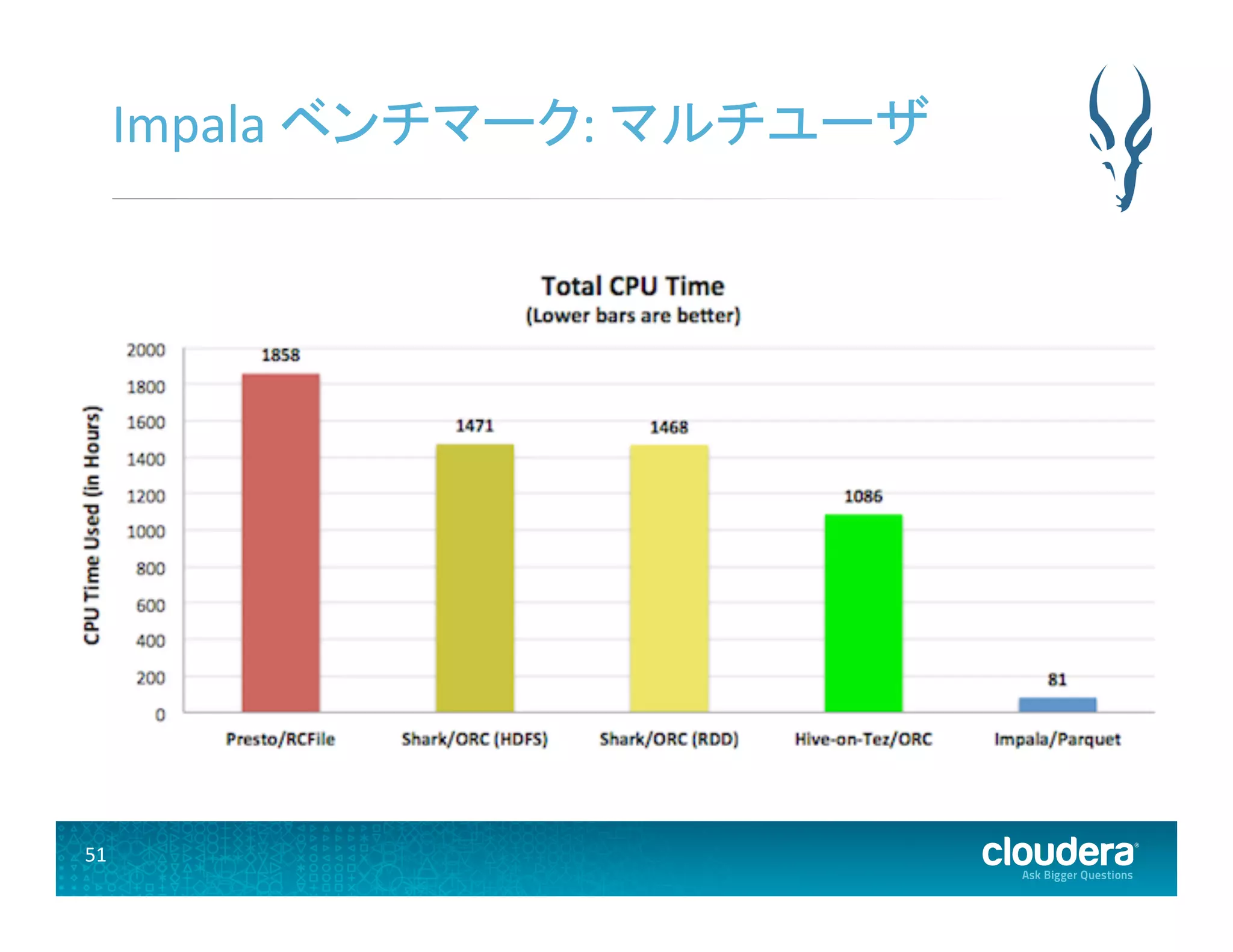
50.
50 Impala ベンチマーク:
マルチユーザ x21.6 beCer than Presto Impala: 863 Presto: 40
51.
51 Impala ベンチマーク:
マルチユーザ
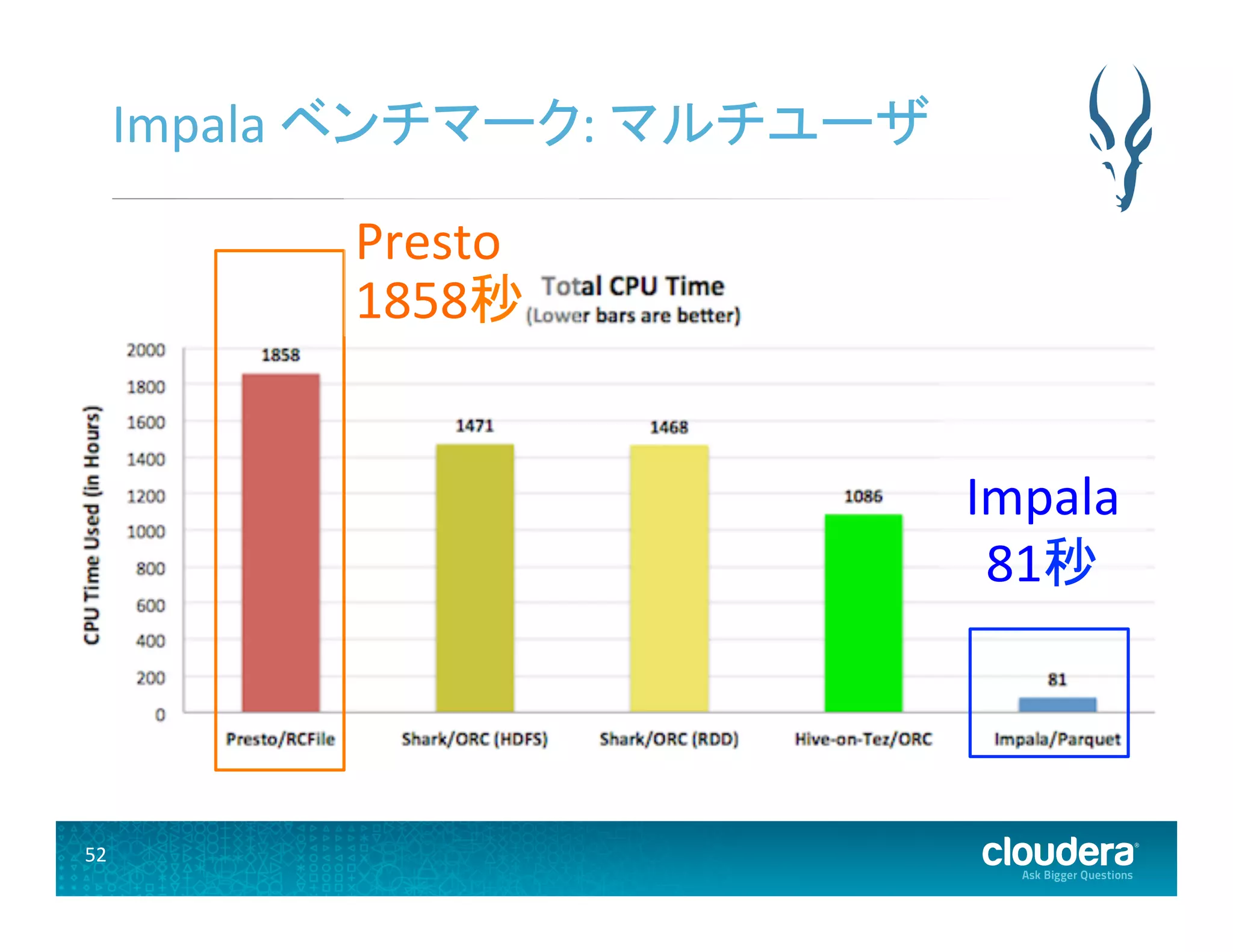
52.
52 Impala ベンチマーク:
マルチユーザ Impala 81秒 Presto 1858秒
53.
53 Impala ベンチマーク:
vs. DBMS-‐Y
54.
54 Hadoopにおけるスケーラビリティ • Hadoopにはリニアスケーラビリティがある
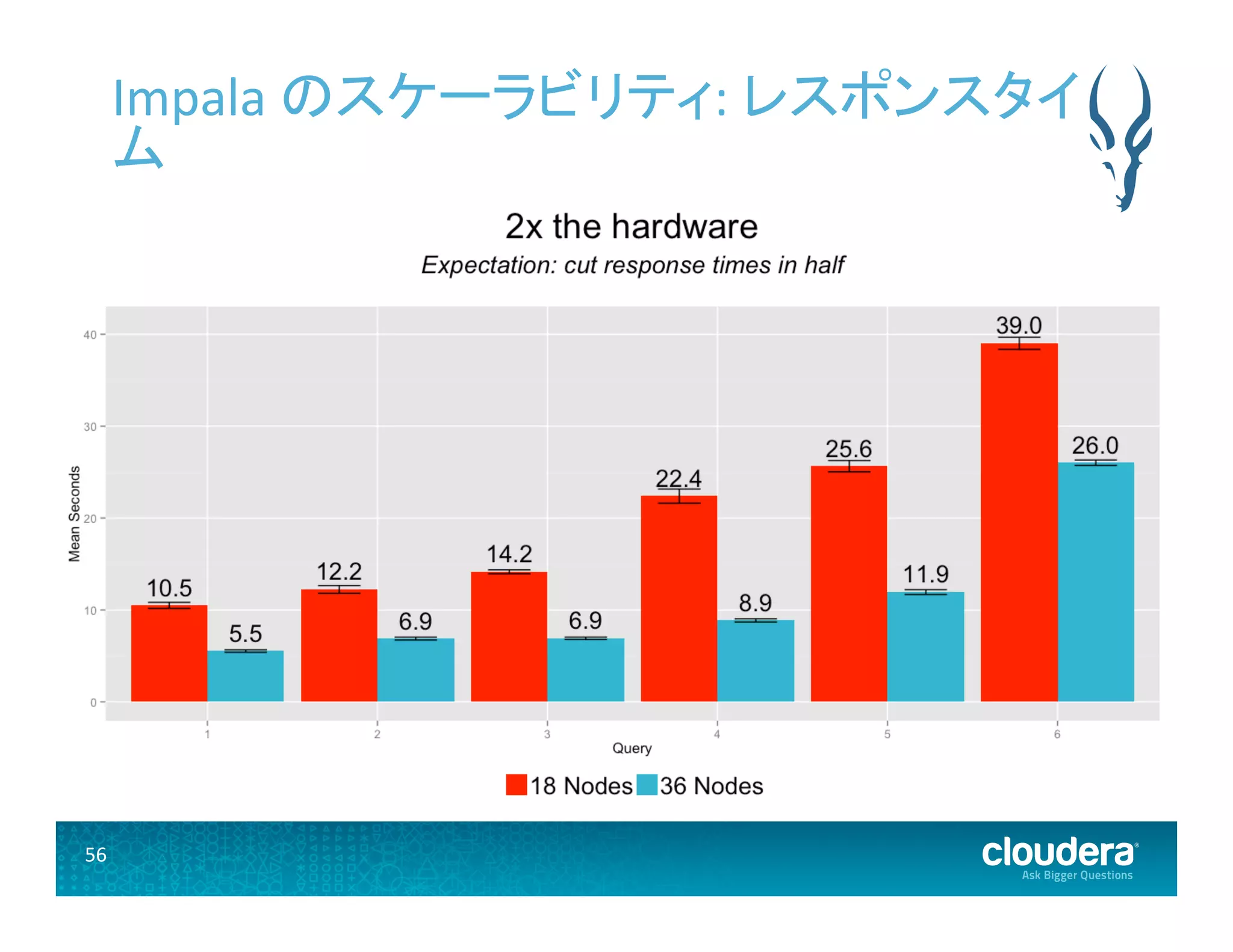
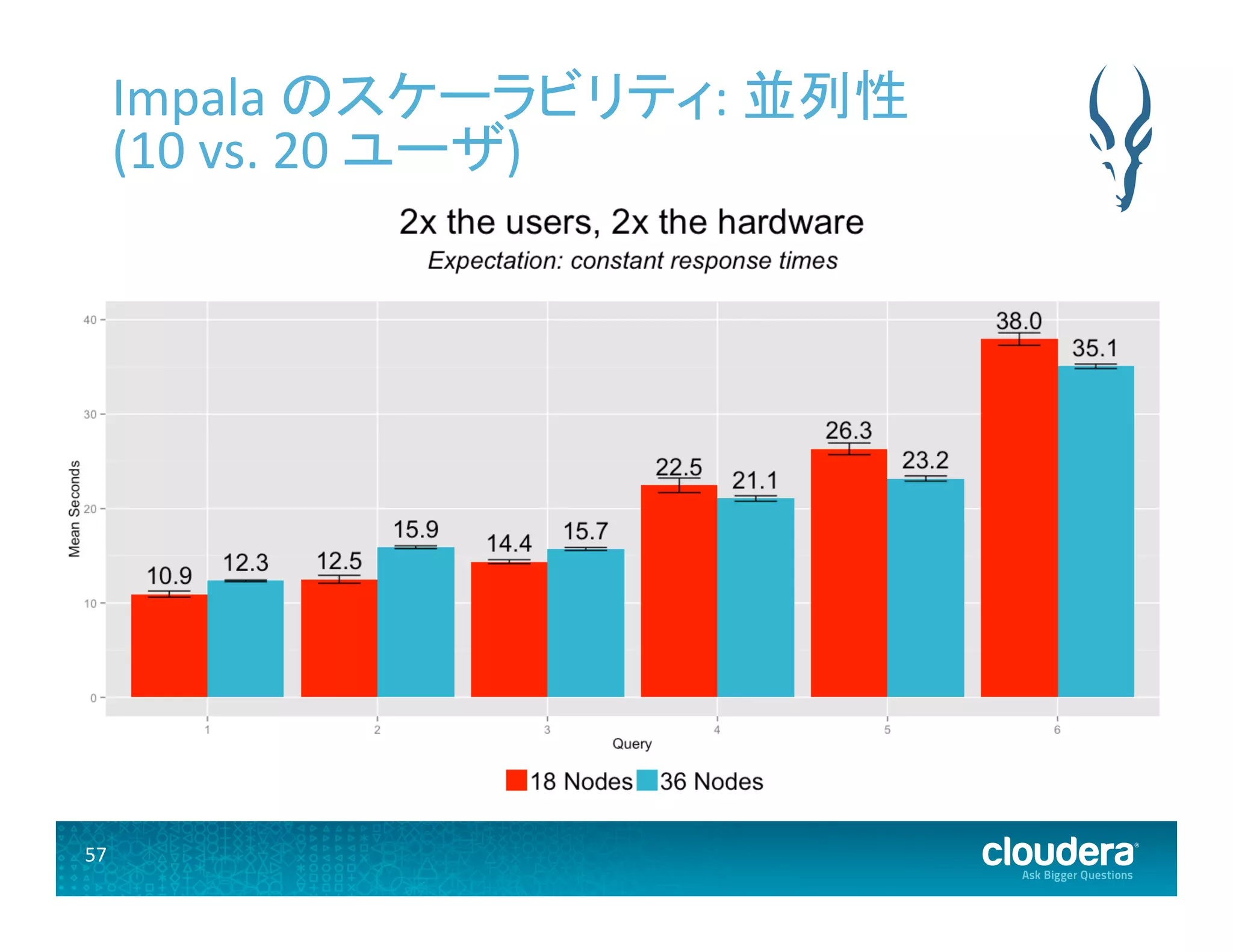
• クラスタにノードを追加すれば、それに比 例して性能が向上する • 性能増はあらゆるワークロードに適用され る • EDWワークロードにおける評価指標 • レスポンスタイム • 並列性とクエリスループット • データサイズ
55.
55 Hadoopにおけるスケーラビリティ •
Impalaのスケーラビリティ評価結果 • クラスタ: 18 ノードと 36 ノード • データセット: 15TB と 30TB の TPC-‐DS データセット • クエリ: 6種類の「インタラクティブ」TPC-‐DSクエリ • 並列性: 10 クエリと 20 クエリ (並列性以外のテストでは 1 クエリ)
56.
56 Impala のスケーラビリティ:
レスポンスタイ ム
57.
57 Impala のスケーラビリティ:
並列性 (10 vs. 20 ユーザ)
58.
58 Impala のスケーラビリティ:
データサイズ (15TB vs. 30TB データセット)
59.
59 ロードマップ
60.
60 ロードマップ •
Impala 1.4 (2014年夏) • HDFS キャッシング DDL • COMPUTE STATS の高速化 • LIMIT なしの ORDER BY • DECIMAL(<precision>, <scale>) • ブロードキャストJOIN用のブルームフィルタ • Llama が produc(on ready になる • EDW システム用の追加のビルトイン • そして……さらに高速化!
61.
61 ロードマップ •
Impala 2.0 (2014年下半期) • SQL 2003 準拠の分析ウィンドウ関数 • LEAD(), LAG(), etc. • 相関サブクエリ • ハッシュテーブルをディスクに書き出せるようになる • 任意のサイズのテーブルをJOIN、集約することが可能に • Nested data type • map, struct, and array
62.
62 まとめ
63.
63 Cloudera Impala
• Hadoop クラスタのためのオープンソースの高速SQL エンジン • 他の類似ソフトに比べて圧倒的に高速 • リソース管理、セキュリティなど機能も豊富 Hadoop上の分析SQLエンジンは Cloudera Impala を使いましょう hUp://impala.io/
64.
64 Cloudera Impala
の⽇日本語フリーブック • オライリーの「インパラ本」、日本語PDF版が無償公開されました! • http://www.oreilly.co.jp/books/9784873116723/ • Cloudera の John Russell 著 • Hadoop、HBase、Hadoopオペレーション、 プログラミングHiveなどを翻訳された 玉川竜司さんが翻訳! 「これまでClouderaの皆 さんにご尽力いただいた 翻訳レビューへの感謝の 気持ちとして、Cloudera World Tokyo開催のお祝 いに翻訳寄贈します!」
65.
65
Download













































![[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...](https://cdn.slidesharecdn.com/ss_thumbnails/tehahj7vqmsswpgrzrq6-signature-4c7632456c9c538ff9d2a30431910153be9e17d570b88fac06692ab02f11f222-poli-160725043205-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




























