Impala Meetup 2014/10/31 @Tokyo 講演資料
【注意事項】
本資料で紹介している検証結果は2014年当時のものです。当該ソフトウェアは成長や改善が早く、現時点のバージョンでは大きく異なる機能や性能となっています。
SQL on Hadoopの最新情報に基づくサービスやシステムインテグレーションにご興味をお持ちの方は、NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス(電子メール: hadoop [AT] kits.nttdata.co.jp) にご相談ください。








![10Copyright © 2014 NTT DATA Corporation
はじめに
ベンチマーク
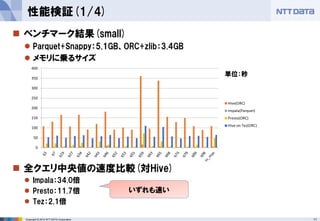
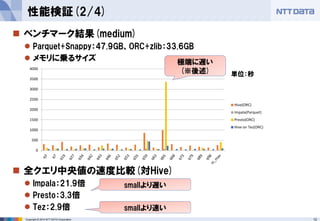
TPC-DSはオンライン処理のベンチマーク
検証の趣旨と合致するが、ETLでは結果が異なることが予想される
HWのスペック
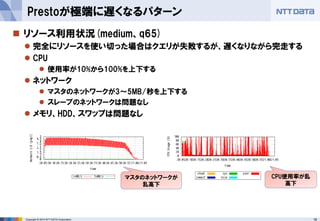
Impalaのことを考えるなら、メモリをもっと積んだほうがよい
しかし、Hadoopに合わせるなら、64GBは妥当なところでは
ディスク容量の都合で、TB以上の検証ができていない
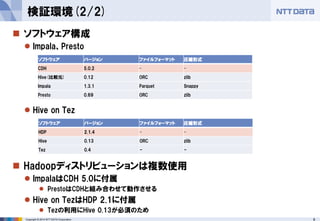
SWのバージョン
各プロダクトのバージョンが若干古い(すみません...)
CDH 5.2でImpala 2.0が入った
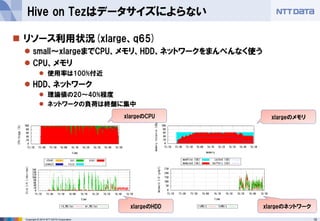
Prestoは週替りのリリースで0.79まで進んだ
HDP 2.2のリリースがそろそろ。Hive 0.14、Tez 0.60が入る
各プロダクトとも活発に開発が進められているため、
すぐに検証結果が古くなる
[参考]Impalaレポートは
384GB](https://image.slidesharecdn.com/sqlonhadoopcloudera-141104215117-conversion-gate02/85/SQL-on-Hadoop-2014-11-10-320.jpg)


















































![[Aws]database migration seminar_20191008](https://cdn.slidesharecdn.com/ss_thumbnails/awsdatabasemigrationseminar20191008-191009110716-thumbnail.jpg?width=640&height=640&fit=bounds)



















