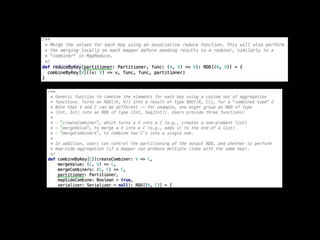
TeraSort 50GB
•MapReduce 22m34.220s
• Tez 14m52.593s
• Spark [ポーティング中]
• spark-perf is good place to port
• https://github.com/rxin/spark/blob/terasort/examples/
src/main/scala/org/apache/spark/examples/terasort/
TeraSort.scala
8.
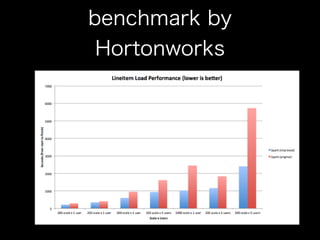
Wordcount 20GB
•MapReduce 11m13.173s
• Tez 7m19.763s
• Spark 4m 17s
• Spark is too fast … why?
9.
Benchmark comparision
•MapReduce and Tez
• bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-
2.5.1.jar terasort -Dmapreduce.job.reduces=16
teragenInput50G out
• Spark
• sc.textFile("hdfs:///user/ozawa/wordcountInput20G")
.flatMap(line => line.split(" "))
.map(word => (word, 1)).persist()
.reduceByKey((a, b) => a + b, 16)
.saveAsTextFile(“hdfs:///user/ozawa/sparkWordcountOutNew1");
• Checking reduceByKey
Spark on Tez
• Allow for pluggable execution contexts in
Spark
• https://issues.apache.org/jira/browse/
SPARK-3561
• Exposing Spark API to everyone :-)
• http://hortonworks.com/blog/improving-spark-
data-pipelines-native-yarn-integration/
15.
アーキテクチャ
Spark API(SparkContext)
Disk-based RDD
on Tez
In-memory RDD
on Spark
16.
Why do so?
• ユーザ面の利点
• Tez は Disk に最適化されているので,ディスクベースのワー
クロードで高速に動作する…かも?
• YARN の機能を利用することでマルチユーザ環境で高いス
ループットを実現
• ベンチマーク視点で見ると…
• API が合うのでフェアなベンチマークが可能になるかも
• https://github.com/hortonworks/spark-native-yarn
![[Work-In-Progress]
MapReduce/Spark/Tez の
フェアな
性能比較に向けて
oza](https://image.slidesharecdn.com/cwt2014-mr-spark-tez-comparision-141107023141-conversion-gate02/85/MapReduce-Spark-Tez-Cloudera-World-Tokyo-2014-LT-1-320.jpg)
![[Work-In-Progress]
MapReduce/Spark/Tez の
フェアな
性能比較に向けて
oza](https://image.slidesharecdn.com/cwt2014-mr-spark-tez-comparision-141107023141-conversion-gate02/75/MapReduce-Spark-Tez-Cloudera-World-Tokyo-2014-LT-1-2048.jpg)




![当初想定していたworkload
• [WIP]TeraSort (sort)
• 50GB
• WordCount (aggregation)
• 20GB (10GB per node)
• Join
• やってない](https://image.slidesharecdn.com/cwt2014-mr-spark-tez-comparision-141107023141-conversion-gate02/85/MapReduce-Spark-Tez-Cloudera-World-Tokyo-2014-LT-6-320.jpg)
![TeraSort 50GB
• MapReduce 22m34.220s
• Tez 14m52.593s
• Spark [ポーティング中]
• spark-perf is good place to port
• https://github.com/rxin/spark/blob/terasort/examples/
src/main/scala/org/apache/spark/examples/terasort/
TeraSort.scala](https://image.slidesharecdn.com/cwt2014-mr-spark-tez-comparision-141107023141-conversion-gate02/85/MapReduce-Spark-Tez-Cloudera-World-Tokyo-2014-LT-7-320.jpg)












































































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)













