Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yifeng Jiang
1,108 views
Hive-sub-second-sql-on-hadoop-public
数千億行のデータをApache Hiveで処理する2つの具体的なユースケースをご紹介します。
Software
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
7
/ 24
8
/ 24
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PDF
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
PDF
HDP Security Overview
by
Yifeng Jiang
PDF
OLAP options on Hadoop
by
Yuta Imai
PDF
Start of a New era: Apache YARN 3.1 and Apache HBase 2.0
by
DataWorks Summit
PDF
Yifeng hadoop-present-public
by
Yifeng Jiang
PDF
Yifeng spark-final-public
by
Yifeng Jiang
PDF
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
PDF
Comparison of Transactional Libraries for HBase
by
DataWorks Summit/Hadoop Summit
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
HDP Security Overview
by
Yifeng Jiang
OLAP options on Hadoop
by
Yuta Imai
Start of a New era: Apache YARN 3.1 and Apache HBase 2.0
by
DataWorks Summit
Yifeng hadoop-present-public
by
Yifeng Jiang
Yifeng spark-final-public
by
Yifeng Jiang
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
Comparison of Transactional Libraries for HBase
by
DataWorks Summit/Hadoop Summit
What's hot
PDF
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
PDF
IoTアプリケーションで利用するApache NiFi
by
Yuta Imai
PDF
第25回 Hadoopソースコードリーディング 「HBase 最新情報」
by
Toshihiro Suzuki
PDF
Treasure Dataを支える技術 - MessagePack編
by
Taro L. Saito
PDF
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
PDF
Apache NiFiで、楽して、つながる、広がる IoTプロジェクト
by
Koji Kawamura
PDF
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PDF
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
PPTX
A Benchmark Test on Presto, Spark Sql and Hive on Tez
by
Gw Liu
PPTX
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
PDF
Evolution of Impala #hcj2014
by
Cloudera Japan
PDF
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
PDF
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
PDF
Tez on EMRを試してみた
by
Satoshi Noto
PDF
Data Science on Hadoop
by
Yifeng Jiang
PDF
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
PPTX
The truth about SQL and Data Warehousing on Hadoop
by
DataWorks Summit/Hadoop Summit
PPTX
Struggle against crossdomain data complexity in Recruit Group
by
DataWorks Summit/Hadoop Summit
PDF
Deep Learning On Apache Spark
by
Yuta Imai
PDF
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
IoTアプリケーションで利用するApache NiFi
by
Yuta Imai
第25回 Hadoopソースコードリーディング 「HBase 最新情報」
by
Toshihiro Suzuki
Treasure Dataを支える技術 - MessagePack編
by
Taro L. Saito
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
Apache NiFiで、楽して、つながる、広がる IoTプロジェクト
by
Koji Kawamura
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
A Benchmark Test on Presto, Spark Sql and Hive on Tez
by
Gw Liu
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
Evolution of Impala #hcj2014
by
Cloudera Japan
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
Tez on EMRを試してみた
by
Satoshi Noto
Data Science on Hadoop
by
Yifeng Jiang
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
The truth about SQL and Data Warehousing on Hadoop
by
DataWorks Summit/Hadoop Summit
Struggle against crossdomain data complexity in Recruit Group
by
DataWorks Summit/Hadoop Summit
Deep Learning On Apache Spark
by
Yuta Imai
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
Similar to Hive-sub-second-sql-on-hadoop-public
PDF
Apache Hiveの今とこれから
by
Yifeng Jiang
PPTX
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
PDF
Apache Hiveの今とこれから - 2016
by
Yuta Imai
PDF
Impalaチューニングポイントベストプラクティス
by
Yahoo!デベロッパーネットワーク
PDF
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PDF
株式会社インタースペース 守安様 登壇資料
by
leverages_event
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
PDF
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
PPT
Apache Hive 紹介
by
あしたのオープンソース研究所
PDF
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
PPTX
B34 Extremely Tuned Hadoop Cluster by Daisuke Hirama
by
Insight Technology, Inc.
PDF
20100916_EMRを使ったシステム構築案件
by
Kotaro Tsukui
PDF
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
PPTX
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
PDF
Programming Hive Reading #3
by
moai kids
PDF
Hive undocumented feature
by
tamtam180
PPTX
HDPをWindowsで動かしてみた
by
adachij2002
PDF
20100930 sig startups
by
Ichiro Fukuda
PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
Apache Hiveの今とこれから
by
Yifeng Jiang
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
Apache Hiveの今とこれから - 2016
by
Yuta Imai
Impalaチューニングポイントベストプラクティス
by
Yahoo!デベロッパーネットワーク
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
株式会社インタースペース 守安様 登壇資料
by
leverages_event
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
Apache Hive 紹介
by
あしたのオープンソース研究所
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
B34 Extremely Tuned Hadoop Cluster by Daisuke Hirama
by
Insight Technology, Inc.
20100916_EMRを使ったシステム構築案件
by
Kotaro Tsukui
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
Programming Hive Reading #3
by
moai kids
Hive undocumented feature
by
tamtam180
HDPをWindowsで動かしてみた
by
adachij2002
20100930 sig startups
by
Ichiro Fukuda
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
More from Yifeng Jiang
PDF
Sub-second-sql-on-hadoop-at-scale
by
Yifeng Jiang
PDF
Nifi workshop
by
Yifeng Jiang
PDF
Hadoop Present - Open Enterprise Hadoop
by
Yifeng Jiang
PDF
HDFS Deep Dive
by
Yifeng Jiang
PDF
Hive spark-s3acommitter-hbase-nfs
by
Yifeng Jiang
PDF
Spark Security
by
Yifeng Jiang
PDF
Real-time Analytics in Financial
by
Yifeng Jiang
PDF
Kinesis vs-kafka-and-kafka-deep-dive
by
Yifeng Jiang
PPTX
Hive present-and-feature-shanghai
by
Yifeng Jiang
PDF
introduction-to-apache-kafka
by
Yifeng Jiang
PDF
Hortonworks Data Cloud for AWS 1.11 Updates
by
Yifeng Jiang
PDF
Hive2 Introduction -- Interactive SQL for Big Data
by
Yifeng Jiang
PDF
Introduction to Hortonworks Data Cloud for AWS
by
Yifeng Jiang
PDF
Introduction to Streaming Analytics Manager
by
Yifeng Jiang
PDF
HDF 3.0 IoT Platform for Everyone
by
Yifeng Jiang
Sub-second-sql-on-hadoop-at-scale
by
Yifeng Jiang
Nifi workshop
by
Yifeng Jiang
Hadoop Present - Open Enterprise Hadoop
by
Yifeng Jiang
HDFS Deep Dive
by
Yifeng Jiang
Hive spark-s3acommitter-hbase-nfs
by
Yifeng Jiang
Spark Security
by
Yifeng Jiang
Real-time Analytics in Financial
by
Yifeng Jiang
Kinesis vs-kafka-and-kafka-deep-dive
by
Yifeng Jiang
Hive present-and-feature-shanghai
by
Yifeng Jiang
introduction-to-apache-kafka
by
Yifeng Jiang
Hortonworks Data Cloud for AWS 1.11 Updates
by
Yifeng Jiang
Hive2 Introduction -- Interactive SQL for Big Data
by
Yifeng Jiang
Introduction to Hortonworks Data Cloud for AWS
by
Yifeng Jiang
Introduction to Streaming Analytics Manager
by
Yifeng Jiang
HDF 3.0 IoT Platform for Everyone
by
Yifeng Jiang
Hive-sub-second-sql-on-hadoop-public
1.
Apache Hive Hadoop上のSub-second SQL Yifeng
Jiang Solutions Engineer, Hortonworks Japan 2015/10/14 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
2.
Page 2 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved アジェンダ • Hiveユースケース#1: 超⼤量データの⾼並列処理 • Hiveユースケース#2: Hive LLAPによるオンラインレポーティング
3.
© Hortonworks Inc.
2015. All Rights Reserved Hiveユースケース#1: 超大量データの高並列処理 Page 3 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
4.
Page 4 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved ユースケース #1 バッチ レポーティング 超巨⼤なデータセット • 13ヶ⽉、5千億⾏以上 • 毎⽇13億⾏が追加 ⾼いスループットが求められます • ⼀⽇ 100,000 レポート • 15,000クエリを1時間以内で完了しなけ ればならない Input Dataset
5.
Page 5 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved Hiveチューニング 4つの Hive チューニング ポイント • パーティション • データロード • クエリ実⾏ • 並列のためのチューニング
6.
Page 6 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved パーティション パーティションの数を最⼤化 • パフォーマンスにとって基本的かつ最も重 要なポイント • 必要なデータのみ読込み 合計数千パーティション以下になるように • Hiveはクエリを早く処理するための適切 な数 CREATE TABLE access_logs ( host string, path string, referrer string, … ) PARTITIONED BY ( site int, ymd date )
7.
Page 7 ©
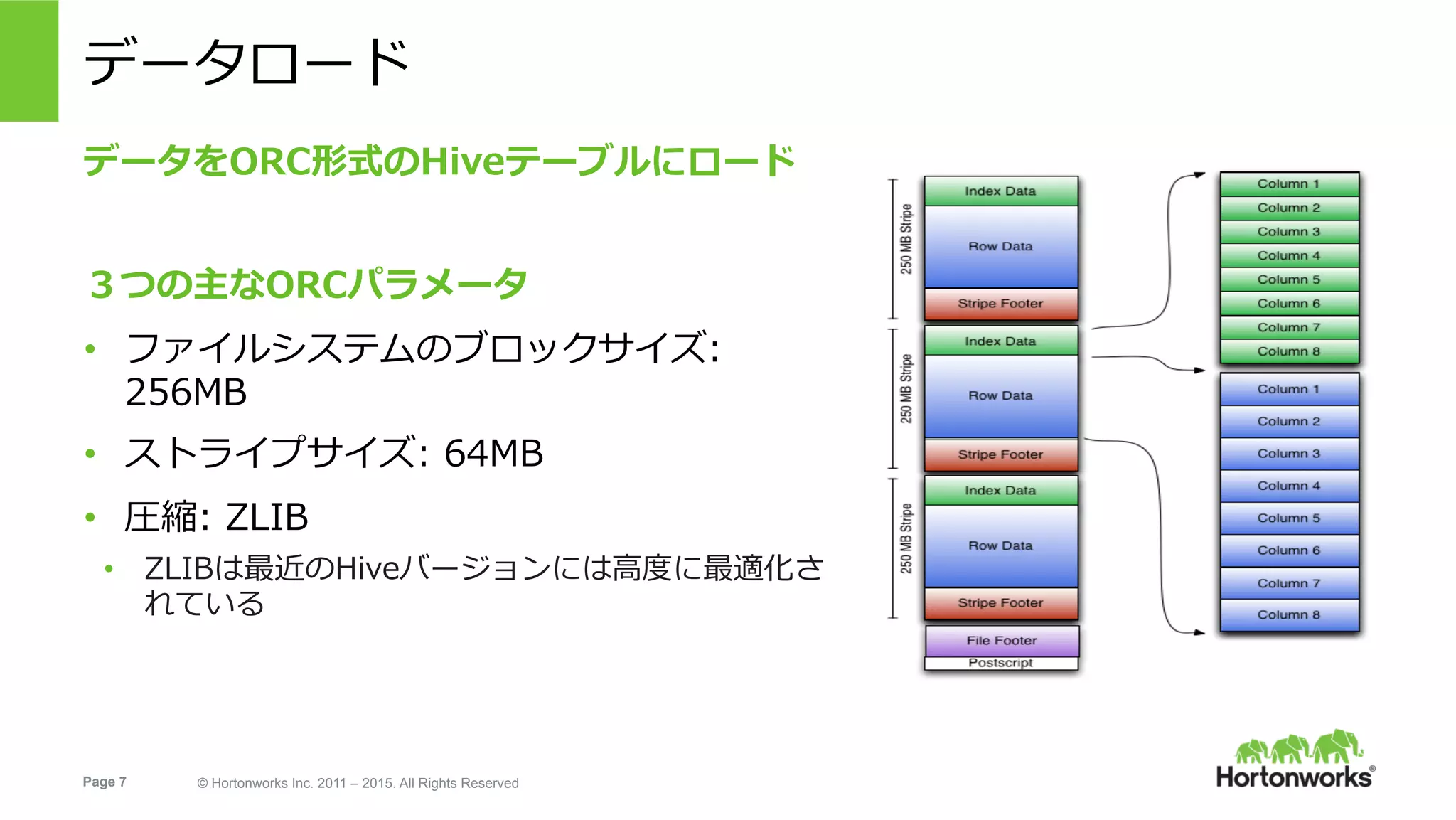
Hortonworks Inc. 2011 – 2015. All Rights Reserved データロード データをORC形式のHiveテーブルにロード 3つの主なORCパラメータ • ファイルシステムのブロックサイズ: 256MB • ストライプサイズ: 64MB • 圧縮: ZLIB • ZLIBは最近のHiveバージョンには⾼度に最適化さ れている
8.
Page 8 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved データロード ORCファイルは⼗分に⼤きいことを確認 • 可能なら1〜10HDFSブロックぐらい • たくさんの reducers がすべてのパーティションへの書込みを避ける • Optimize sort dynamic partitioning を有効に • あるいは DISTRIBUTED BY 句を使う • 細かいコントロールがきくため DISTRIBUTED BY を選んだ INSERT INTO orc_sales PARTITION ( country ) SELECT FROM daily_sales DISTRIBUTE BY country, gender;
9.
Page 9 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved クエリ実⾏ クエリ実⾏は最終的⼀連の組合せ • クライアントの実⾏ [ 正しくやれば 0s ] • オプティマイゼーション [HiveServer2] [~ 0.1s] • HCatalog問合せ [Hcatalog, Metastore] [ hive 0.14 は⾮常に早い ] • Application Master 作成 [4-5s] • コンテナ割当 [3-5s] • クエリ実⾏ YARN and HDFS HiveServer2 Server #1 Client Running testing tool N connections N connections Metastore Metastore DB HiveServer2 Server #2 Tez AM Tez Container Tez Container …
10.
Page 10 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved クエリ実⾏ コレクション作成がオーバヘッドが⾼い • 1つのコレクション接続に⼤量のクエリを実⾏ • 標準なコレクション プールを利⽤ 2つの HiveServer2 でクエリを分散 • HiveServer2 が 8-15 queries/s でボトルネックになった • 複数の HiveServer2 をAmbariからデプロイ • 新しいバージョンではクエリの並列コンパイルを対応予定
11.
Page 11 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved クエリ実⾏ Tezセッションの再利⽤と暖機運転 • Tezセッションの再⽣成が5秒以上かかる • Tezセッション再利⽤を有効に • 暖機運転による事前⽣成も可能 • 暖機運転を有効にした場合、フルスピードは実質的に⼀瞬で出せる Tezコンテナの再利⽤ • コンテナの作成は3秒かかる • コンテナ再利⽤を有効に。短い間キープする。 • キーは100%利⽤率を実現しながらリソースを無駄にしない
12.
Page 12 ©
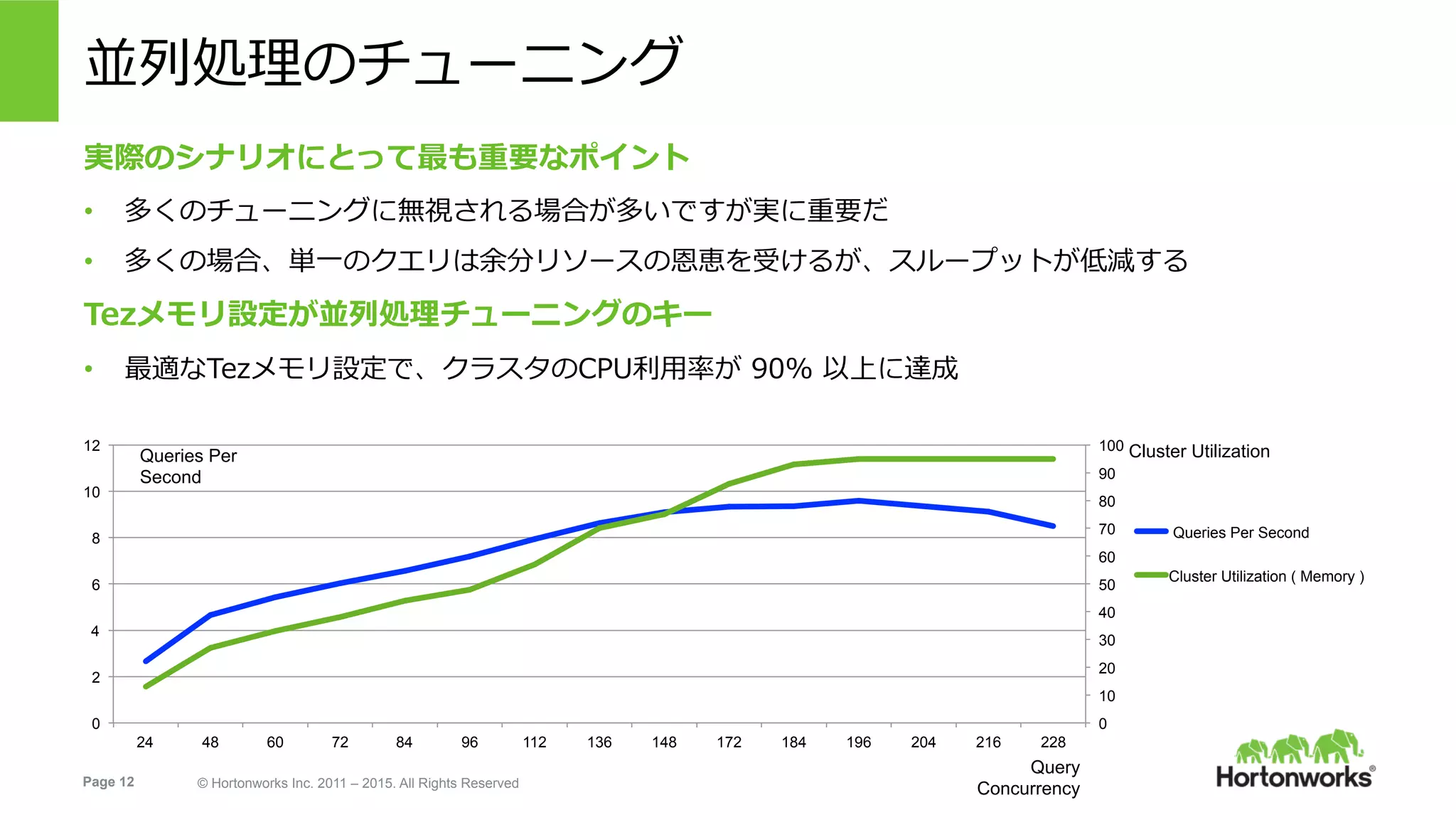
Hortonworks Inc. 2011 – 2015. All Rights Reserved 0 10 20 30 40 50 60 70 80 90 100 0 2 4 6 8 10 12 24 48 60 72 84 96 112 136 148 172 184 196 204 216 228 Queries Per Second Cluster Utilization ( Memory ) 並列処理のチューニング 実際のシナリオにとって最も重要なポイント • 多くのチューニングに無視される場合が多いですが実に重要だ • 多くの場合、単⼀のクエリは余分リソースの恩恵を受けるが、スループットが低減する Tezメモリ設定が並列処理チューニングのキー • 最適なTezメモリ設定で、クラスタのCPU利⽤率が 90% 以上に達成 Cluster UtilizationQueries Per Second Query Concurrency
13.
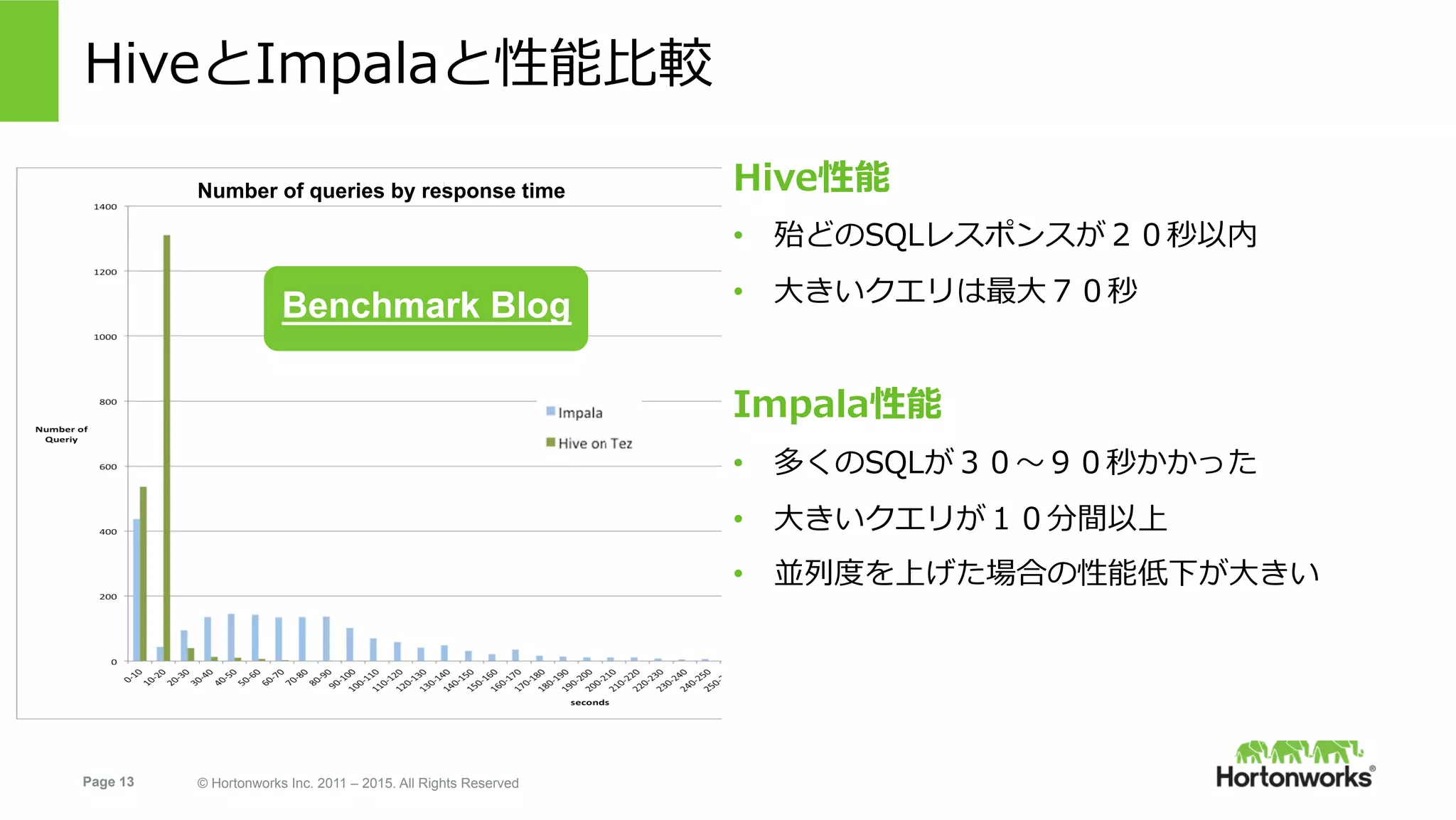
Page 13 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved HiveとImpalaと性能⽐較 Hive性能 • 殆どのSQLレスポンスが20秒以内 • ⼤きいクエリは最⼤70秒 Impala性能 • 多くのSQLが30〜90秒かかった • ⼤きいクエリが10分間以上 • 並列度を上げた場合の性能低下が⼤きい Benchmark Blog Number of queries by response time
14.
© Hortonworks Inc.
2015. All Rights Reserved Hiveユースケース#2: Hive LLAPによるオンラインレポーティング Page 14 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
15.
Page 15 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved Hive性能を振返ってみる Hiveは早い: インタラクティブな応答 • ベクトル化の SQL エンジン • Tez 実⾏エンジン • ORC カラム型ファイルフォーマット • コスト ベース オプティマイザ (COB) Hive 0.10 バッチ処理 100-150x 速度アップ Hive 0.14 インタラクティブ 処理 (5秒)
16.
Page 16 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved Hiveユースケース#2 オンライン レポーティング • インタラクティブなオンライン レポート • 巨⼤なデータセット • 低レイテンシ:秒以下(sub-second)〜数秒(超巨⼤なデータの場合) • ⾼い並列度
17.
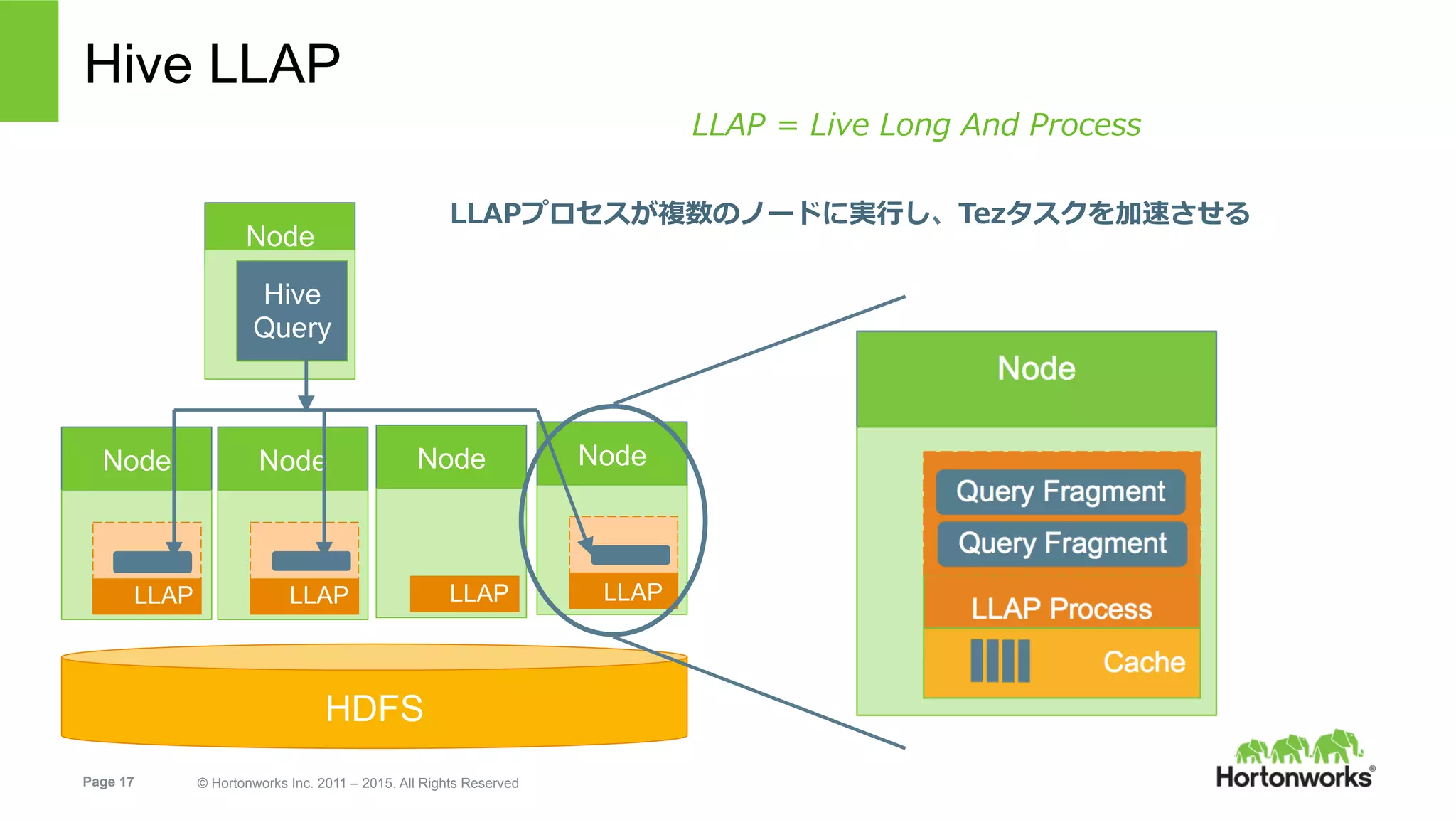
Page 17 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved Hive LLAP HDFS LLAPプロセスが複数のノードに実⾏し、Tezタスクを加速させる Node Hive Query Node NodeNode Node LLAP LLAP LLAP LLAP LLAP = Live Long And Process
18.
Page 18 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved Hive LLAP – 主な利点 パフォーマンスの利点 • 起動時間の短縮 • データ キャッシュ • 常時稼働のため最適化しやすい: JIT、 並列 I/O、 など
19.
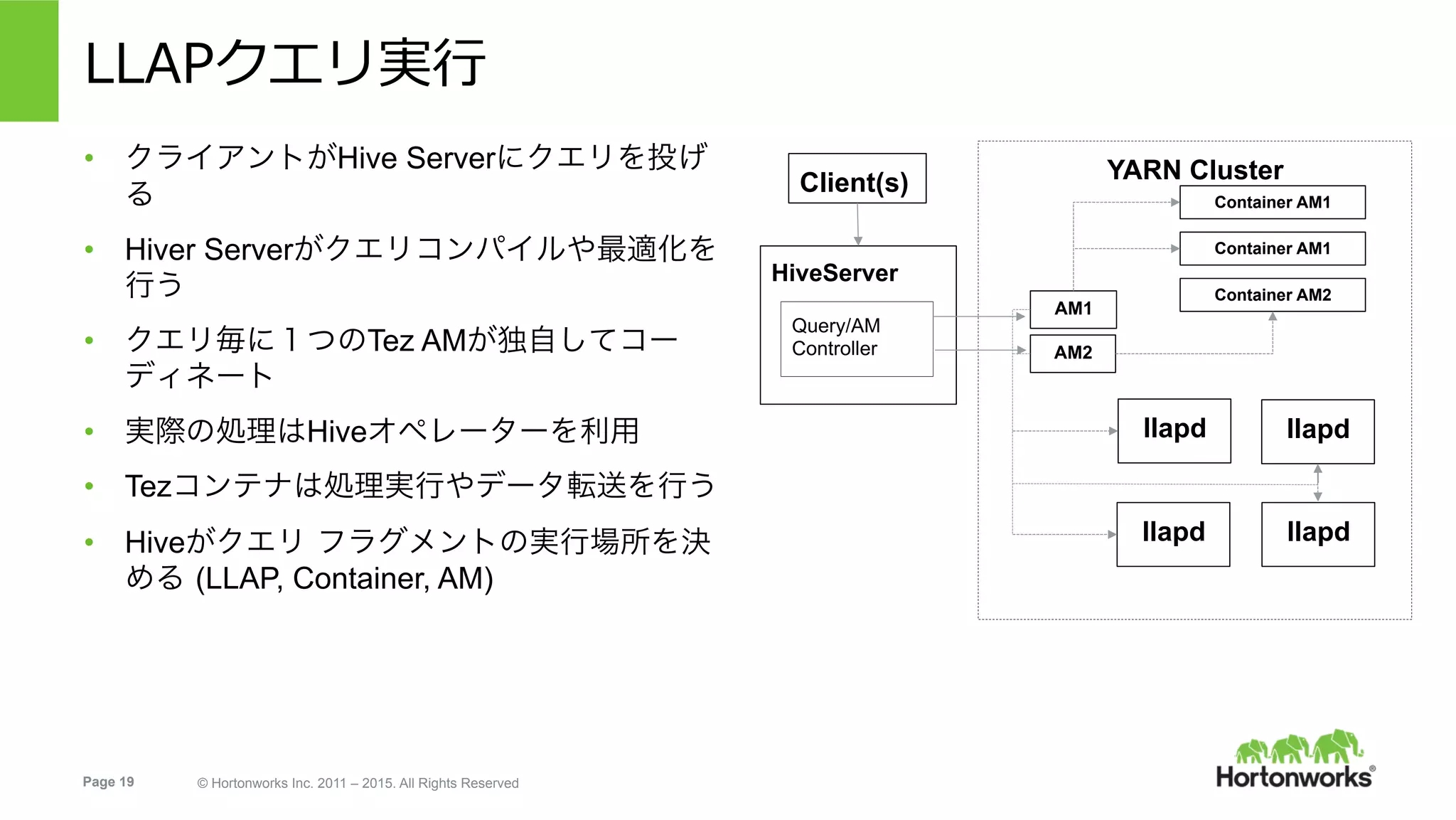
Page 19 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved LLAPクエリ実⾏ • クライアントがHive Serverにクエリを投げ る • Hiver Serverがクエリコンパイルや最適化を 行う • クエリ毎に1つのTez AMが独自してコー ディネート • 実際の処理はHiveオペレーターを利用 • Tezコンテナは処理実行やデータ転送を行う • Hiveがクエリ フラグメントの実行場所を決 める (LLAP, Container, AM) HiveServer Query/AM Controller Client(s) YARN Cluster AM1 llapd llapd llapd Container AM1 Container AM1 llapd Container AM2 AM2
20.
Page 20 ©
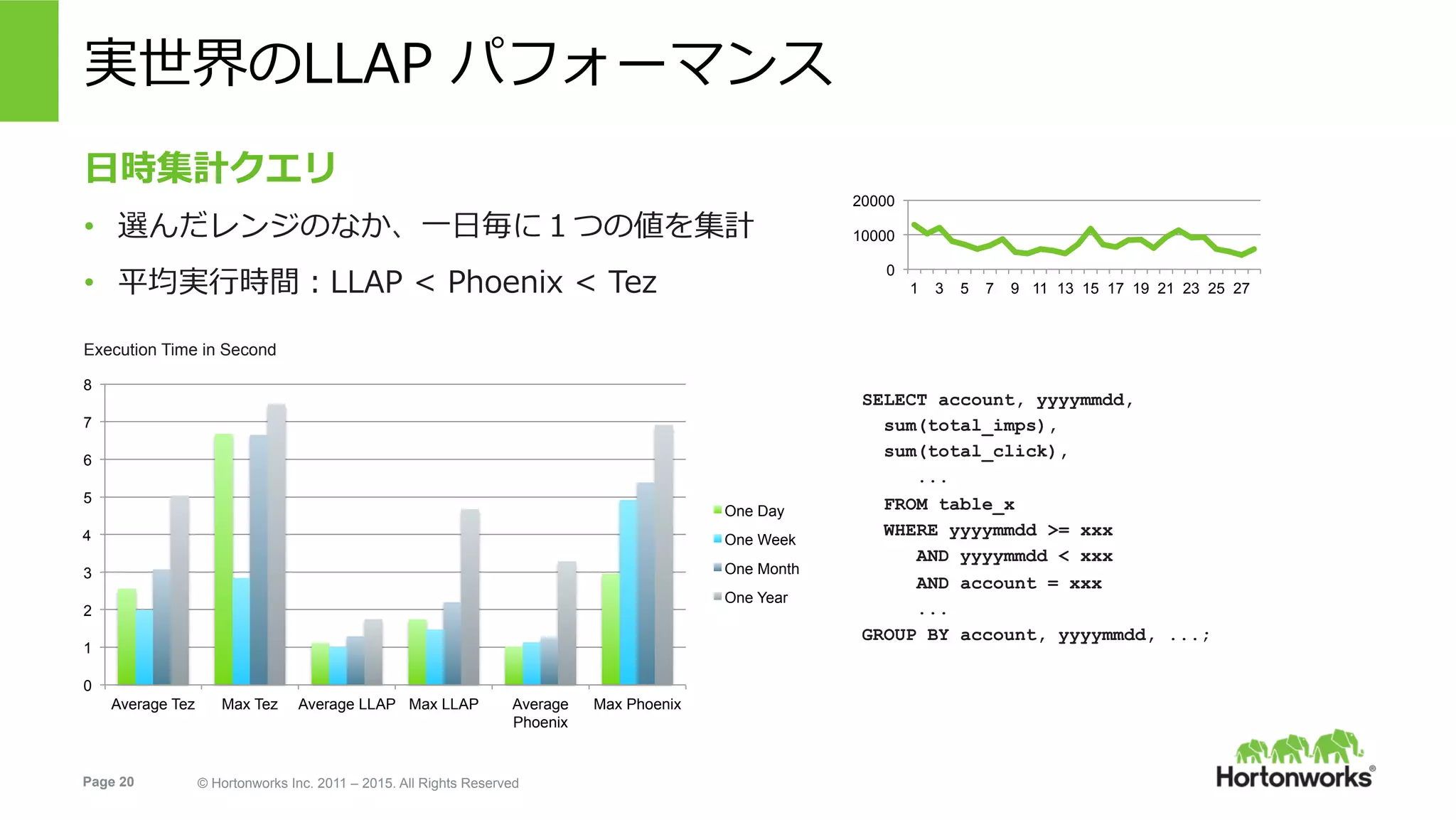
Hortonworks Inc. 2011 – 2015. All Rights Reserved 実世界のLLAP パフォーマンス 0 10000 20000 1 3 5 7 9 11 13 15 17 19 21 23 25 27 ⽇時集計クエリ • 選んだレンジのなか、⼀⽇毎に1つの値を集計 • 平均実⾏時間:LLAP < Phoenix < Tez Execution Time in Second 0 1 2 3 4 5 6 7 8 Average Tez Max Tez Average LLAP Max LLAP Average Phoenix Max Phoenix One Day One Week One Month One Year SELECT account, yyyymmdd, sum(total_imps), sum(total_click), ... FROM table_x WHERE yyyymmdd >= xxx AND yyyymmdd < xxx AND account = xxx ... GROUP BY account, yyyymmdd, ...;
21.
Page 21 ©
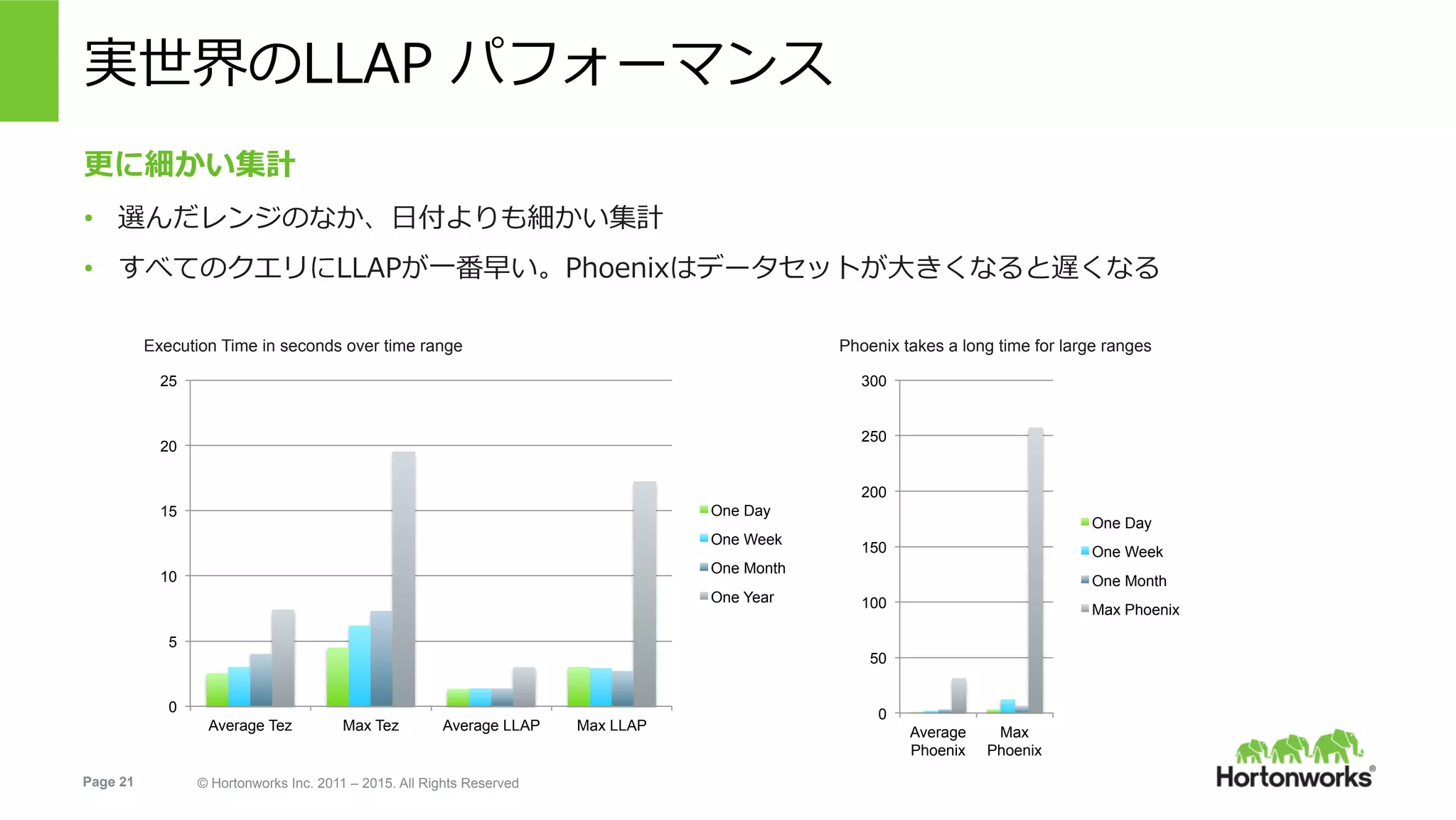
Hortonworks Inc. 2011 – 2015. All Rights Reserved 実世界のLLAP パフォーマンス Execution Time in seconds over time range 0 5 10 15 20 25 Average Tez Max Tez Average LLAP Max LLAP One Day One Week One Month One Year 0 50 100 150 200 250 300 Average Phoenix Max Phoenix One Day One Week One Month Max Phoenix Phoenix takes a long time for large ranges 更に細かい集計 • 選んだレンジのなか、⽇付よりも細かい集計 • すべてのクエリにLLAPが⼀番早い。Phoenixはデータセットが⼤きくなると遅くなる
22.
Page 22 ©
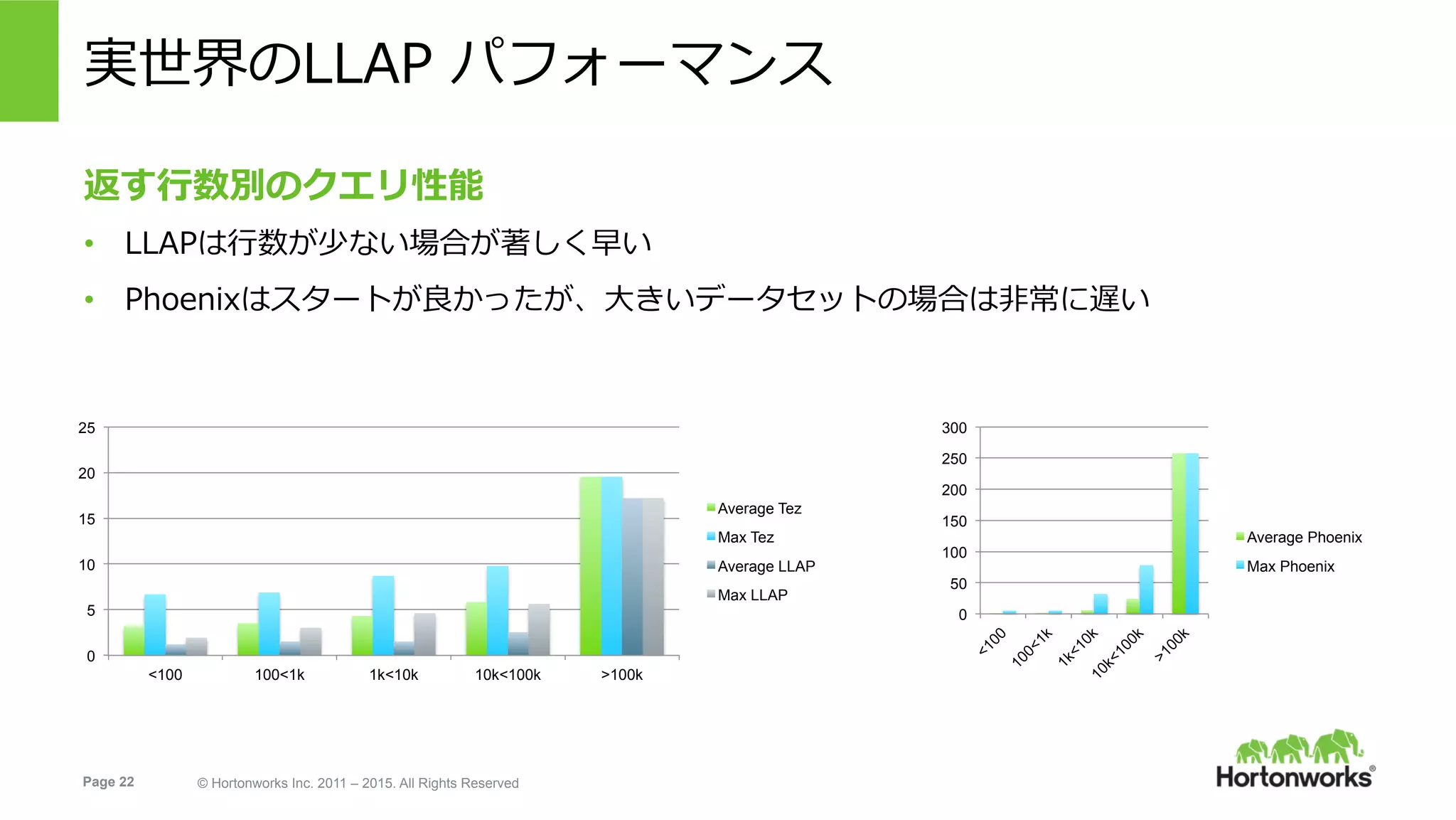
Hortonworks Inc. 2011 – 2015. All Rights Reserved 実世界のLLAP パフォーマンス 返す⾏数別のクエリ性能 • LLAPは⾏数が少ない場合が著しく早い • Phoenixはスタートが良かったが、⼤きいデータセットの場合は⾮常に遅い 0 5 10 15 20 25 <100 100<1k 1k<10k 10k<100k >100k Average Tez Max Tez Average LLAP Max LLAP 0 50 100 150 200 250 300 Average Phoenix Max Phoenix
23.
Page 23 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved まとめ Page 23 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
24.
Page 24 ©
Hortonworks Inc. 2011 – 2015. All Rights Reserved Hiveの今とこれから Hive SQL on Hadoopの事実上の標準 • 1つのツールで、バッチやインタラクティブ処理 • 1つのツールで、すべてのビッグデータSQLユースケース • ETL、レポーティング、BI、ディープ分析など • LLAP が実現するSub-second Hive • 実世界の超巨⼤スケールで証明されたパフォーマンス
Download







![Page 9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
クエリ実⾏
クエリ実⾏は最終的⼀連の組合せ
• クライアントの実⾏ [ 正しくやれば 0s ]
• オプティマイゼーション [HiveServer2] [~ 0.1s]
• HCatalog問合せ [Hcatalog, Metastore] [ hive 0.14 は⾮常に早い ]
• Application Master 作成 [4-5s]
• コンテナ割当 [3-5s]
• クエリ実⾏
YARN and HDFS
HiveServer2
Server #1
Client
Running testing tool
N connections
N connections
Metastore Metastore DB
HiveServer2
Server #2
Tez
AM
Tez
Container
Tez
Container
…](https://image.slidesharecdn.com/sub-second-sql-on-hadoop-public-151030091141-lva1-app6891/75/Hive-sub-second-sql-on-hadoop-public-9-2048.jpg)