Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Cloudera Japan
5,591 views
CDH4.1オーバービュー
Cloudera World Tokyo 2012 で発表した、CDH4.1の概要説明に関する資料です。
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Downloaded 64 times
1
/ 58
2
/ 58
3
/ 58
4
/ 58
5
/ 58
6
/ 58
7
/ 58
8
/ 58
9
/ 58
10
/ 58
11
/ 58
12
/ 58
13
/ 58
14
/ 58
15
/ 58
16
/ 58
17
/ 58
18
/ 58
19
/ 58
20
/ 58
21
/ 58
22
/ 58
23
/ 58
24
/ 58
25
/ 58
26
/ 58
27
/ 58
28
/ 58
29
/ 58
30
/ 58
31
/ 58
32
/ 58
33
/ 58
34
/ 58
35
/ 58
36
/ 58
37
/ 58
38
/ 58
39
/ 58
40
/ 58
41
/ 58
42
/ 58
43
/ 58
44
/ 58
45
/ 58
46
/ 58
47
/ 58
48
/ 58
49
/ 58
50
/ 58
51
/ 58
52
/ 58
53
/ 58
54
/ 58
55
/ 58
56
/ 58
57
/ 58
58
/ 58
More Related Content
PDF
HDFS HA セミナー #hadoop
by
Cloudera Japan
PDF
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
5分でわかる Apache HBase 最新版 #hcj2014
by
Cloudera Japan
PDF
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
HDFS HA セミナー #hadoop
by
Cloudera Japan
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
5分でわかる Apache HBase 最新版 #hcj2014
by
Cloudera Japan
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
Cloudera大阪セミナー 20130219
by
Cloudera Japan
What's hot
PDF
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
PDF
Hadoopを用いた大規模ログ解析
by
shuichi iida
PDF
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
PDF
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
PDF
Hadoop入門
by
Preferred Networks
PPTX
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
PPTX
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
PDF
MapReduceプログラミング入門
by
Satoshi Noto
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
PDF
Hadoop概要説明
by
Satoshi Noto
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PDF
MapR M7 技術概要
by
MapR Technologies Japan
PDF
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
PDF
Evolution of Impala #hcj2014
by
Cloudera Japan
PDF
Apache Hadoop の現在と将来(Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
PPTX
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
PDF
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
PDF
MapR アーキテクチャ概要 - MapR CTO Meetup 2013/11/12
by
MapR Technologies Japan
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
Hadoopを用いた大規模ログ解析
by
shuichi iida
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
Hadoop入門
by
Preferred Networks
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
MapReduceプログラミング入門
by
Satoshi Noto
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
Hadoop概要説明
by
Satoshi Noto
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
MapR M7 技術概要
by
MapR Technologies Japan
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
Evolution of Impala #hcj2014
by
Cloudera Japan
Apache Hadoop の現在と将来(Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
MapR アーキテクチャ概要 - MapR CTO Meetup 2013/11/12
by
MapR Technologies Japan
Similar to CDH4.1オーバービュー
PDF
CDH4セミナー資料
by
Cloudera Japan
PDF
CDH5最新情報 #cwt2013
by
Cloudera Japan
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PPTX
Hadoop scr第7回 hw2011フィードバック
by
AdvancedTechNight
PDF
Cloudera Impala #pyfes 2012.11.24
by
Sho Shimauchi
PDF
Log analysis with Hadoop in livedoor 2013
by
SATOSHI TAGOMORI
PDF
20111130 10 aws-meister-emr_long-public
by
Amazon Web Services Japan
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
PDF
OSSで支えられるライブドアの巨大ログ集計 #nhntech
by
SATOSHI TAGOMORI
PDF
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
PDF
20100930 sig startups
by
Ichiro Fukuda
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PPTX
[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化
by
Takahiro Moteki
PDF
Hive Tools in NHN Japan #hadoopreading
by
SATOSHI TAGOMORI
PPTX
ビッグデータ活用支援フォーラム
by
Recruit Technologies
PDF
C5.2 (Cloudera Manager + CDH) アップデート #cwt2014
by
Cloudera Japan
PDF
WDD2012_SC-004
by
Kuninobu SaSaki
CDH4セミナー資料
by
Cloudera Japan
CDH5最新情報 #cwt2013
by
Cloudera Japan
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
Hadoop scr第7回 hw2011フィードバック
by
AdvancedTechNight
Cloudera Impala #pyfes 2012.11.24
by
Sho Shimauchi
Log analysis with Hadoop in livedoor 2013
by
SATOSHI TAGOMORI
20111130 10 aws-meister-emr_long-public
by
Amazon Web Services Japan
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
OSSで支えられるライブドアの巨大ログ集計 #nhntech
by
SATOSHI TAGOMORI
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
20100930 sig startups
by
Ichiro Fukuda
Osc2012 spring HBase Report
by
Seiichiro Ishida
[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化
by
Takahiro Moteki
Hive Tools in NHN Japan #hadoopreading
by
SATOSHI TAGOMORI
ビッグデータ活用支援フォーラム
by
Recruit Technologies
C5.2 (Cloudera Manager + CDH) アップデート #cwt2014
by
Cloudera Japan
WDD2012_SC-004
by
Kuninobu SaSaki
More from Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PDF
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
PDF
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
PDF
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
PDF
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PDF
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PPTX
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
PDF
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
PDF
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
HBase Across the World #LINE_DM
by
Cloudera Japan
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
CDH4.1オーバービュー
1.
CDH4.1オーバービュー
Cloudera カスタマーオペレーションズエンジニア 嶋内 翔 2012年11月7日 1
2.
アジェンダ
• CDH概要とその歴史 • CDH4での変更点 • HDFS HA • HDFS HA(QJMベース) • MapReduce v2 • Flume NG 2
3.
自己紹介
• 嶋内 翔(しまうち しょう) • 2011年4月にClouderaの最初の日本人社員として入 社 • カスタマーオペレーションズエンジニアとしてテクニ カルサポート業務を担当 • email: sho@cloudera.com • twiHer: @shiumachi 3
4.
CDH概要とその歴史 4
5.
CDHとは何か?
• Cloudera’s DistribuMon including Apache Hadoop • エンタープライズ向けに開発された100%オープン ソースのHadoopディストリビューション • Apache Hadoopを中心に、10以上のオープンソース コンポーネントを含む 5
6.
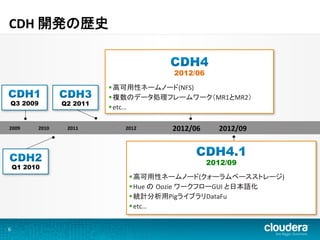
CDH 開発の歴史
2012/06 § 高可用性ネームノード(NFS) § 複数のデータ処理フレームワーク(MR1とMR2) Q3 2009 Q2 2011 § etc… 2009 2010 2011 2012 2012/06 2012/09 2012/09 Q1 2010 § 高可用性ネームノード(クォーラムベースストレージ) § Hue の Oozie ワークフローGUI と日本語化 § 統計分析用PigライブラリDataFu § etc… 6
7.
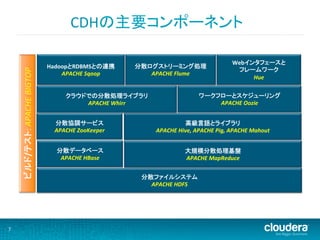
CDHの主要コンポーネント
Webインタフェースと HadoopとRDBMSとの連携 分散ログストリーミング処理 ビルド/テスト: APACHE BIGTOP フレームワーク APACHE Sqoop APACHE Flume Hue クラウドでの分散処理ライブラリ ワークフローとスケジューリング APACHE Whirr APACHE Oozie 分散協調サービス 高級言語とライブラリ APACHE ZooKeeper APACHE Hive, APACHE Pig, APACHE Mahout 分散データベース 大規模分散処理基盤 APACHE HBase APACHE MapReduce 分散ファイルシステム APACHE HDFS 7
8.
CDH4での変更点 8
9.
CDH4リリース番号
• リリース番号の表記が変わりました • CDH3 以前: CDH3u0, CDH3u1, CDH3u2 … • CDH4: CDH X.Y.Z • X: メジャーバージョン(大規模な変更を含む) • Y: マイナーバージョン(CDH3以前の update に相当) • Z: ポイントバージョン(重大なバグ修正のみ) • 最新版は CDH4.1.1 • 多分もうすぐCDH4.1.2が出ます 9
10.
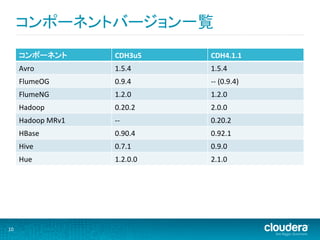
コンポーネントバージョン一覧
コンポーネント CDH3u5 CDH4.1.1 Avro 1.5.4 1.5.4 FlumeOG 0.9.4 -‐-‐ (0.9.4) FlumeNG 1.2.0 1.2.0 Hadoop 0.20.2 2.0.0 Hadoop MRv1 -‐-‐ 0.20.2 HBase 0.90.4 0.92.1 Hive 0.7.1 0.9.0 Hue 1.2.0.0 2.1.0 10
11.
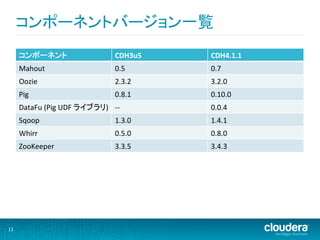
コンポーネントバージョン一覧
コンポーネント CDH3u5 CDH4.1.1 Mahout 0.5 0.7 Oozie 2.3.2 3.2.0 Pig 0.8.1 0.10.0 DataFu (Pig UDF ライブラリ) -‐-‐ 0.0.4 Sqoop 1.3.0 1.4.1 Whirr 0.5.0 0.8.0 ZooKeeper 3.3.5 3.4.3 11
12.
Hadoop
• 大きな変更 • MapReduce version 2 (YARN というフレームワークがベース) • HDFS HA(高可用 HDFS) • NFS共有ディレクトリ(CDH4.0) • クォーラムベースストレージ共有ディレクトリ(CDH4.1) • HDFS フェデレーション • パラメータ名が大きく変更 • 例: fs.default.name は fs.defaultFS に変更 • 古いパラメータ名を使っていても deprecated という WARN ログ が出るだけで実害なし • 既存のMapReduceアプリケーションはそのままCDH4で 使用可能 • ただしCDH4環境で再コンパイルが必要 12
13.
Hadoop (続き)
• REST over HTTPインタフェースの追加 • HHpFs • WebHDFS • MapReduceシャッフルフェーズでの暗号化(CDH4.1) • libhdfs でのダイレクト読み込み(HDFS-‐2834, HDFS-‐3110) (CDH4.1) • C++ クライアントからの読み込みが2-‐3倍高速になった • Impala が高速な理由の一つ 13
14.
HBase
• コプロセッサ(HBASE-‐2000) • HFile v2 (HBASE-‐3857) • 分散ログスプリッティング • その他さまざまな機能追加 • Web UI の表示情報量が増えた • ログからスロークエリを調べやすくなった 14
15.
Hive
• 新しいデータ型のサポート • BINARY (HIVE-‐2380) • TIMESTAMP (HIVE-‐2272) • JDBC日付文字列フォーマット準拠の形式 • ビットマップインデックス(HIVE-‐1803) • hHps://cwiki.apache.org/confluence/display/Hive/IndexDev+Bitmap • プラグイン・デベロッパ・キット(PDK)(HIVE-‐2244) • Hive拡張を作りやすくする • 現在UDFのみサポート • hHps://cwiki.apache.org/confluence/display/Hive/PluginDeveloperKit • JDBCドライバの改善 • Hiveserver2 (HIVE-‐2935) (CDH4.1) • 複数ユーザからの同時接続など、従来のHiveserverにはなかった機 能を追加 15
16.
Pig
• UDFでJavaScriptサポート(PIG-‐1794) • 組み込みPig(PIG-‐1479) • Python, Ruby でもUDFを記述可能 • hHp://archive.cloudera.com/cdh4/cdh/4/pig/udf.html • マクロ(PIG-‐1793) • define my_macro(A, sortkey) returns C { … } という形式でマクロを定義 可能 • project-‐range 記法(PIG-‐1693) • col0, col1 .. col3 と書くと、 col0, col1, col2, col3 に展開してくれる • hHp://archive.cloudera.com/cdh4/cdh/4/pig/basic.html#expressions • その他の機能・改善 • エラーメッセージの改善 • combinerの最適化 • ILLUSTRATE コマンドのバグ修正 16
17.
CDH4.1
DataFu • 統計分析用 Pig UDF(ユーザ定義関数)ライブラリ • LinkedIn が開発 • PageRank、セッション化といった高度なデータ解析に 役立つライブラリ集 ranks = FOREACH edges GENERATE group as topic, FLATTEN(PageRank(edges.(s,e))) as (source,rank); 17
18.
Flume
• Flume NG (1.x 系) • 従来のFlume (以下 Flume OG) を大きくリファクタリング • Flume NG = New GeneraMon (新世代) • Flume OG = Old GeneraMon (旧世代) • HBase シンクのサポート(CDH4.1) • Flume OG (0.9.x 系) • CDH4 でもアドオンとして利用可能 18
19.
Oozie
• DistCp アクションのサポート (OOZIE-‐11) • 「バンドル」を追加 • コーディネートジョブ(定期実行ジョブ)をグループ化できる • サポートするDBの追加 • MySQL, Oracle は以前から使える • PostgreSQL(OOZIE-‐22, CDH3u2以降でも使用可) 19
20.
Sqoop
• カスタムタイプマッピング(SQOOP-‐342) • hHp://archive.cloudera.com/cdh4/cdh/4/sqoop/ SqoopUserGuide.html#_controlling_type_mapping • 今までDBスキーマの型とJava/Hiveの型のマッピングは自動だったが、これにより任意のマッ ピングを行えるようになった • -‐-‐map-‐column-‐java, -‐-‐map-‐column-‐hive オプションで指定 • 境界クエリサポート(SQOOP-‐331) • hHp://archive.cloudera.com/cdh4/cdh/4/sqoop/ SqoopUserGuide.html#_selecMng_the_data_to_import • 今までは -‐-‐split-‐by で指定した列の最大と最小の値を元に、分割するときの境界線を決めて いた • -‐-‐boundary-‐query により、境界条件を決定するためのクエリを任意に指定できるようになった • Date/Time インクリメンタルアペンド(SQOOP-‐321) • hHp://archive.cloudera.com/cdh4/cdh/4/sqoop/ SqoopUserGuide.html#_incremental_imports • 今までは数値のみがインクリメンタルインポートの対象だったが、これにより日付型も対象に • IBM DB2 コネクタのサポート(SQOOP-‐329) • 将来のCDH4 では Sqoop2 を追加する予定 20
21.
Whirr
• サポート対象サービスの追加 • MapReduce v2 (YARN) • Chef (WHIRR-‐49) • Ganglia(WHIRR-‐258) • Mahout (WHIRR-‐384) • EC2クラスタコンピュートグループのサポート(WHIRR-‐63) (CDH4.1) • Chef はメインストリームのサービスには(まだ)使われていな い • 今後の設定管理の自動化に期待 • Mahout インストールが可能に • CDHバージョンではないことに注意 • CDH4 ではさらに追加設定パラメータあり • 詳細はドキュメント参照 21
22.
Hue
• Hue2 にメジャーアップデート • UIが大きく変更。Cloudera Manager に近くなった • 旧UIで問題となっていたメモリリークを解決 • HDFS ファイルブラウザのためにDN/NNへのプラグイン を導入する必要がなくなった • OpenLDAPやAcMveDirectory からユーザをインポートで きるようになった • OozieからMapReduceジョブを実行するようになった • Oozie ワークフロービルダー(CDH4.1) • アプリケーション単位のアクセスコントロール • 日本語対応! • Hue 1.x 系の SDK とは非互換なので注意 22
23.
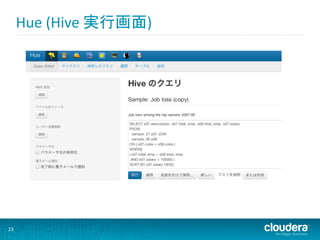
Hue (Hive 実行画面)
23
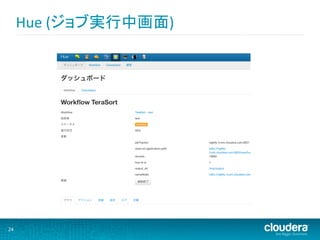
24.
Hue (ジョブ実行中画面) 24
25.
HDFS HA 25
26.
HDFS HA(高可用性 HDFS)
• 従来のHadoopではネームノードは単一障害点 (SPOF)だった • ネームノードのダウンタイム発生ケースは2種類 • 障害停止(低確率) • 計画停止(確実に発生) • 現在はHDFS HA機能があるためSPOFはなくなった • 上記のダウンタイムの問題は解決できる • 自動フェイルオーバ可能 • 特殊なサーバを必要とせず、Hadoopと同じスペック のノードで構築可能(CDH4.1) 26
27.
HDFS HA アーキテクチャ
• ネームノードのペアを使う • アクティブとスタンバイ • クライアントとデータノードはアクティブNNとのみ通信する • スタンバイNNは共有ストレージを参照してアクティブノード の状態を取得可能 • スタンバイネームノードはチェックポイントを行う • よってHAではセカンダリネームノードは不要 27
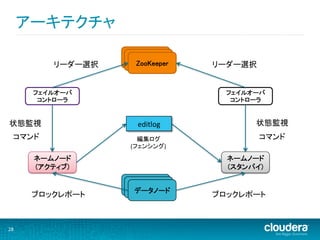
28.
アーキテクチャ
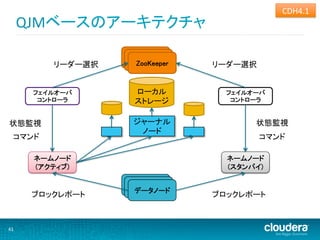
Daemon Daemon リーダー選択 ZooKeeper リーダー選択 フェイルオーバ フェイルオーバ コントローラ コントローラ 状態監視 editlog 状態監視 コマンド 編集ログ コマンド (フェンシング) ネームノード ネームノード (アクティブ) (スタンバイ) Daemon Daemon データノード ブロックレポート ブロックレポート 28
29.
フェイルオーバとフェンシング
• 起動時にアクティブなNNを選出 • 必ず1個のアクティブしか起動しないことを保証 • CDH4では手動・自動フェイルオーバをサポート • スプリットブレイン時のデータ破壊を防ぐ • 共有リソースのフェンシング • DN、及び共有ストレージ上のNNのメタデータ • NNのフェンシング • 共有リソースをフェンスできなかった場合 • クライアントフェイルオーバ • クライアントはフェイルオーバ後に新しいNNにアクセスで きる 29
30.
手動フェイルオーバの方法
• hdfs haadmin -‐failover nn01 nn02 • 手動フェイルオーバはこのコマンドで実行 • フェンシングとスタンバイNNへのフェイルオーバを実施 30
31.
自動フェイルオーバ
• 自動フェイルオーバはZooKeeperを使う • ZooKeeper はHBaseでも使われている協調サービス • 設定方法は以下のような流れ 1. NNで自動フェイルオーバ用の設定を行う 2. NNを起動する 3. ZooKeeper フェイルオーバコントローラ(ZKFC)デーモンを 起動する • ZKFCは全NNと同一ノードで起動しなければいけない • 運用監視ソフトからもZKFCを監視するのを忘れずに 31
32.
自動フェイルオーバの流れ
• 単純に kill -‐9 するだけ • フェイルオーバは5秒で開始される • デフォルト値。設定変更可能 • ha.zookeeper.session-‐Mmeout.ms (ミリ秒単位) 32
33.
CDH4.1
HDFS HA (QJMベース) 33
34.
HDFS HA での共有ストレージ
• スタンバイNNは、アクティブNNのトランザクションロ グ(edits)を読み込むことで名前空間を同期する • mkdir(/foo) などの操作はアクティブNNによってロギング される • スタンバイNNは定期的に新しいeditsを読み込み、自身の メタデータを最新に保つ • よって高信頼な共有ストレージはcorrectな(正しい) オペレーションに必須 34
35.
共有ストレージ(フェーズ1)
• 運用者は従来の共有ストレージデバイスを設定する (SAN, NAS) • アクティブ/スタンバイの両方のNNから共有ストレー ジをNFSマウントする • アクティブNNが書き込み、スタンバイNNが読み込む 35
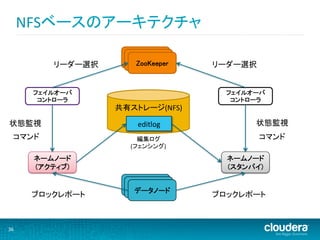
36.
NFSベースのアーキテクチャ
Daemon Daemon リーダー選択 ZooKeeper リーダー選択 フェイルオーバ フェイルオーバ コントローラ コントローラ 共有ストレージ(NFS) 状態監視 editlog 状態監視 コマンド 編集ログ コマンド (フェンシング) ネームノード ネームノード (アクティブ) (スタンバイ) Daemon Daemon データノード ブロックレポート ブロックレポート 36
37.
NFSベースの手法の欠点
• カスタムハードウェア • 多くのお客様はデータセンタにSAN/NASを持っていない • 多くのお金、時間がかかり、高い専門性が必要 • HDFS外から監視する別システムが必要 • SPOFを外に出しただけで、なくしたわけじゃない • 複雑 • ストレージのフェンシング、NFSマウントオプション、ボン ディング、etc. • NFS自身の問題 • クライアントの実装にバグが多い、タイムアウト時の挙動 のコントロールが大変、etc. 37
38.
ストレージの改善のための要件
• 特別なハードウェアを必要としないこと(PDU、NAS) • カスタムのフェンシング設定を必要としないこと • 設定が複雑=設定ミスしやすい • SPOFがないこと • ストレージにSPOFを丸投げするのはよくない • 完全な分散システムが必要 38
39.
ストレージ改善のための要件(続き)
• 耐障害性 • Nノードクラスタが(N-‐1)/2ノードまでの耐障害性を持つこと • スケーラビリティを持つこと • 書き込みは並列に行われる • 書き込みが遅いノードを待たない • 既存のハードウェアに共存可能であること(JT、NN、 SBNなどと共有) 39
40.
CDH4.1
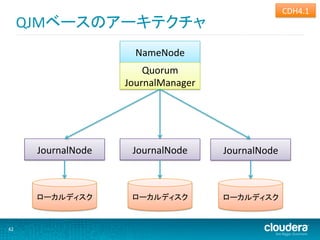
QuorumJournalManager • QuorumJournalManager(クライアント) • クォーラムジャーナルマネージャ • JournalManager インタフェースの実装 • FileJournalManager 実装の置き換え • JournalNode(サーバ) • ジャーナルノード • 奇数ノードで稼働するスタンドアロンデーモン • editsの書き込み先ストレージとして機能 • 将来的には他のデーモン内部で稼働できるようにする予 定 40
41.
CDH4.1
QJMベースのアーキテクチャ Daemon Daemon リーダー選択 ZooKeeper リーダー選択 フェイルオーバ ローカル フェイルオーバ コントローラ ストレージ コントローラ 状態監視 ジャーナル 状態監視 ノード コマンド コマンド ネームノード ネームノード (アクティブ) (スタンバイ) Daemon Daemon データノード ブロックレポート ブロックレポート 41
42.
CDH4.1
QJMベースのアーキテクチャ NameNode Quorum JournalManager JournalNode JournalNode JournalNode ローカルディスク ローカルディスク ローカルディスク 42
43.
CDH4.1
コミットプロトコル • NNはローカルのeditsに書き込む • FSEditLog.logSync()により全てのJNにHadoop RPC を 通じてeditsを送信する • CDH4からeditsは細かく分割されているためデータは小さ い • 過半数のノードから成功のACKが返るのを待つ • これにより遅いJNや障害の発生したJNがNNのレイテンシ に与える影響を最小限にとどめることが可能 • NNのレイテンシ ≒ JNのレイテンシの中間値 43
44.
CDH4.1
ジャーナルノードのフェンシング • QJMインスタンスにはユニークなエポック番号が割り 当てられる • クライアントNN間での強い順序付けを提供 • それぞれの IPC はクライアントのエポックを持つ • JNは今まで見たことのある最も高いエポックをディスク上 に保持する • その値よりも小さいエポックからのリクエストは全て拒否 する。その値よりも大きいエポックはディスクに記録される • Paxos 等でも使われている手法 44
45.
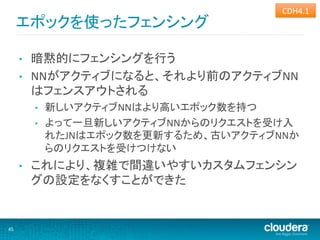
CDH4.1
エポックを使ったフェンシング • 暗黙的にフェンシングを行う • NNがアクティブになると、それより前のアクティブNN はフェンスアウトされる • 新しいアクティブNNはより高いエポック数を持つ • よって一旦新しいアクティブNNからのリクエストを受け入 れたJNはエポック数を更新するため、古いアクティブNNか らのリクエストを受けつけない • これにより、複雑で間違いやすいカスタムフェンシン グの設定をなくすことができた 45
46.
CDH4.1
セグメントリカバリ • 通常、過半数に満たないJNは同期されない • 障害発生後、全てのJNは異なる数のトランザクションを 持ちうる • 例: JN1 がダウンし、JN2はトランザクションID150が書き込まれ る前にクラッシュした • JN1: edits なし • JN2: edits 101-‐149 を持つ • JN3: edits 101-‐150 を持つ • アクティブになる前、最後のバッチについてコンセンサス をとる必要がある • コンセンサスの解決には Paxos アルゴリズムを使ってい る 46
47.
MapReduce v2 47
48.
MapReduce v2 (MRv2)
• Apache Hadoop 0.23 系(現 2.0 系) で開発された • CDH4より導入 • 汎用分散処理フレームワークYARNの上で実装 • MapReduce以外の分散処理にも対応 • Hamster: MPI • Hama: バルクシンクロナスプロセッシング BSP • Giraph: グラフ処理 • 超大規模クラスタを構築可能(最大10000ノード) • MRv1 では最大4000ノード • アーキテクチャが大きく変更された • APIは変更なし。よってMRプログラムは再コンパイルするだけで動作する • コミュニティ版では MRv2 のみ使用可能だがCDH4では MRv1、MRv2 両 方使用可能 • CDH4.1では商用環境でMRv1の利用を推奨 • MRv2はまだ開発用途としての利用を推奨 48
49.
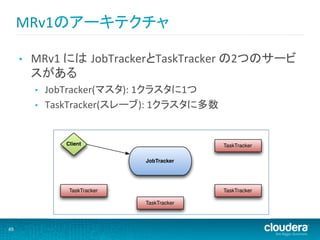
MRv1のアーキテクチャ
MapReduce Job Submission • MRv1 には JobTrackerとTaskTracker の2つのサービ スがある A client submits a job to the JobTracker • – JobTracker assigns a job ID JobTracker(マスタ): 1クラスタに1つ – Client calculates the input splits for the job • TaskTracker(スレーブ): 1クラスタに多数 – Client adds job code and configuration to HDFS Client TaskTracker JobTracker TaskTracker TaskTracker TaskTracker 49
50.
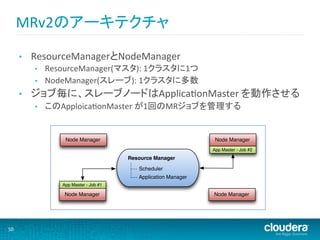
MRv2のアーキテクチャ (cont’d)
MRv2 System Architecture Slave nodes run individual tasks similar to MRv1 • ResourceManagerとNodeManager ResourceManager(マスタ): 1クラスタに1つ • For each job, one slave node is Application Master • NodeManager(スレーブ): 1クラスタに多数 – Manages application lifecycle • ジョブ毎に、スレーブノードはApplicaMonMaster を動作させる – Negotiates resource “containers” from Resource Manager • このApploicaMonMaster が1回のMRジョブを管理する – Monitors tasks running on the other slave nodes Node Manager Node Manager App Master - Job #2 Resource Manager Scheduler Application Manager App Master - Job #1 Node Manager Node Manager Copyright © 2010-2012 Cloudera. All rights reserved. Not to be reproduced without prior written consent. 04-27 50
51.
Flume NG 51
52.
Flume オーバービュー
• Flume は生成される大量のデータを効率よく移動させる ための分散サービス • ログデータを直接HDFSに投入するのに理想的 • 従来は Flume OG がメインだった • CDH3 から追加 • CDH4 ではアドオンとして利用可能だが、フェードアウトする予 定 • Flume NG は CDH4 の一部として存在 • Flume NG の API は Flume OG と非互換 • しかし大半のコンセプトは Flume NG でもそのまま使われている • よりわかりやすくシンプルなアーキテクチャ • メモリ消費量が少なくなった 52
53.
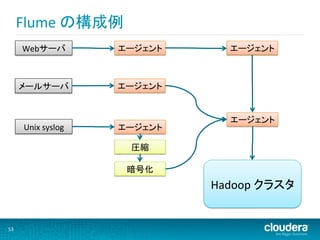
Flume の構成例
Webサーバ エージェント エージェント メールサーバ エージェント エージェント Unix syslog エージェント 圧縮 暗号化 Hadoop クラスタ 53
54.
Flume NG アーキテクチャ概要
• プロデューサ・コンシューマモデル • 多くのコンポーネントがプラガブル コンポーネント 機能 Agent(エージェント) Flumeが動作するJVM。複数のソースとシンクを持つ Source(ソース) データをイベントの形式で生成する。個別のスレッドで動作 Sink(シンク) チャネルからイベントを受け取る。個別のスレッドで動作 Channel(チャネル) ソースとシンクを接続する(キューのように) Event(イベント) 単一のデータ。例: ログ1行、AVROオブジェクト、etc 54
55.
まとめ 55
56.
まとめ
• CDHはHadoopをエンタープライズでも使えるようにし たオープンソースのディストリビューションです • CDH4ではHDFS HAを始め、プロダクションで運用す るための便利な機能が追加されています Hadoop を使うなら まずCDH4を選びましょう ダウンロードはこちら hHp://www.cloudera.com/downloads/ 56
57.
CDHコミュニティ・MLの紹介
CDH ユーザ メーリングリスト(日本語) cdh-‐user-‐jp@cloudera.org CDH の質問についてはこちら Cloudera ニュースレター hHp://www.cloudera.co.jp/newsleHer Cloudera に関するニュースをお届けします CDHの最新情報・使い方なども紹介します 57
58.
58
Download

























































































![[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化](https://cdn.slidesharecdn.com/ss_thumbnails/dlcwt2017infrastructureascodef-171108044056-thumbnail.jpg?width=640&height=640&fit=bounds)























