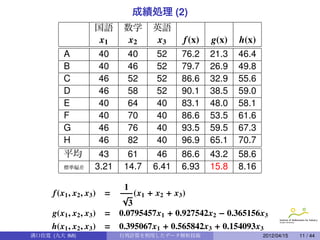
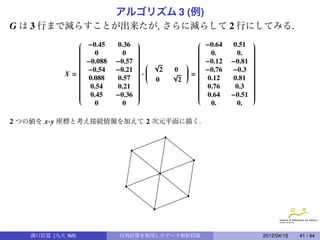
成績処理 (3)
A, B,· · · , H を座標 (g(x), h(x)) でプロットしたもの.
85
C D
80
G H
hx
75
A B
E F
70
65
20 30 40 50 60 70
gx
※ 3 科目の成績の特徴を 2 次元平面に上手にプロットする方法は?
3 次元データの特徴を維持しつつ, 2 次元データに圧縮する方法は?
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 12 / 44
13.
記号と基礎統計量の復習
x = (x1, x2 , · · · , x n), y = (y1 , y2 , · · · , y n), 1 = (1, 1, · · · , 1) とする.
y1
∑
n ( )
y2
内積 s= xi yi = x, y = x · y t = x1 x2 ··· xn ·
.
.
.
i=1
yn
∑
n
ノルム ||x|| = x, x = (xi )2
i=1
∑
n
合計 s= xi = 1, x
i=1
1
平均 x=
¯ 1, x
nn
∑
分散 σ2 = (xi − x)2 = x − x1, x − x1
¯ ¯ ¯
√i=1
標準偏差 σ= x − x1, x − x1
¯ ¯
データの分析, 数列 (Σ), 行列, ベクトル, · · · の勉強が必要.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 13 / 44
14.
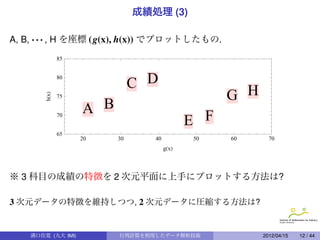
データ行列 · 距離行列· 内積行列
n 個のデータ oi = (xi1 , xi2 , · · · , xip) (i = 1, · · · , n) を考える. ここで
は, p ≤ n としておく. n × p 行列, X = (xi j ) (i = 1, · · · , n,
j = 1, · · · , p) に対して, n × n 行列 M と B を
M = (||oi − o j ||),
B = ( oi , o j ) = (oi · (o j ) t ) = X · X t
とする.
M を距離行列, B を内積行列, X をデータ行列と呼ぶことにする.
n × 1 の列ベクトルを xi = (x1i , x2i , · · · , x ni ) (i = 1, · · · , p) と書き,
X = (x1 , x2 , · · · , x p) と書くこともある.
X が n × p 行列のとき, B = X · X t は n × n 行列, X t · X は p × p 行列.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 14 / 44
15.
B と Xの関係
問題
n × n 行列 B = (bi j ) が与えられ, X がわからないときに, 適当な次元 p を
.
定め, bi j = oi , o j (i = 1, · · · , n, j = 1, · · · , n), すなわち, B = X · X t とな
るような, n 個のベクトル oi = (xi1 , xi2 , · · · , xip) を求めよ.
B を直交対角化して UBU t = Λ と対角行列に出来たとする. このとき, B
.
は半正定値行列であり固有値は 0 または正であることが知られていて,
√
Λ (行列 Λ の対角成分に全て平方根を施した行列) を作ることが出来る.
√ √ √ √
そして, B = U t ( Λ)2 U = (U t Λ)(U t Λ) t であり, X c = U t Λ とすると
B = X c X c となる. このときの X c は n × n 行列である.
t
b ··· u ··· λ ··· u ···
11
b12 b1n 11
u21 u n1 11
0 0 11
u12 u1n
b21
b22 b2n u12
u22 u n2
0
λ22 0
u21
u22 u2n
.
.
. = .
. .
. .
.
. . .
. .
. .
.
. .
. .
. .
.
b n1 b n2 ··· b nn u1n u2n ··· u nn 0 0 ··· λ nn u n1 u n2 ··· u nn
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 15 / 44
16.
アルゴリズム 1
B を作ったもとのデータ行列X を探す:
X = (xi j ) のランクが p であるとき, rank(B) は p であることが知られてお
り, Λ の対角成分は λ1 ≥ λ2 ≥ · · · ≥ λ p で, λ p+1 = · · · = λn = 0 と考えて
良い. Λ = (λi j ), u = (ui j ) とし, r ≤ p とするとき, r × r 行列 Λ r = (λi j )
(i, j = 1, · · · , r), n × r 行列 U r = (ui j ) (i = 1, · · · , n, j = 1, · · · , p) とする
√
と B = U pΛ pU p となる. X c = U p Λ p とすると X c は n × p 行列で,
t
B = X c X c となる.
t
b ··· u ··· λ ··· u ···
11
b12 b1n 11
u21 u p1 11
0 0 11
u12 u1n
b21
b22 b2n u12
u22 u p2 0
λ22 0 u21
u22 u2n
.
.
. = .
. .
. .
.
. . .
. .
. .
.
. .
. .
. .
.
b n1 b n2 ··· b nn u1n u p2 ··· u pn 0 0 ··· λ pp u p1 u2 p ··· u pn
√
u
11
u21 ··· u p1
λ11
√
0 ··· 0
u
12
u22 u p2
0 λ22 0
XC = .
.
. .
.
.
. .
.
.
. .
√
u n1 u n2 ··· u pn 0 0 ··· λ pp
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 16 / 44
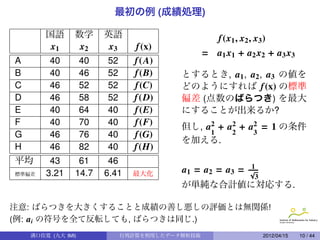
17.
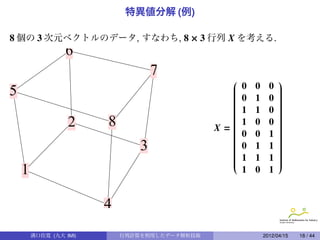
特異値分解
定理 (Singular ValueDecomposition[1])
n × p 行列 X に対して, n × n 直交行列 U, p × p 直交行列 V が存在し,
X = U · L · V t とすることが出来る. 但し, n × p 行列 L = (li j ) は対角行列
li j = 0 (i j, i = 1, · · · , n, j = 1, · · · , p) である.
そして, このとき次の条件が満たされる.
X · X t は, U で直交対角化され 0 でない固有値の集合は
{l2 | lii 0, i = 1, · · · , p}.
ii
UU t = E n で, U(XX t )U t が対角行列になる.
X t · X は, V で直交対角化され 0 でない固有値の集合は
{l2 | lii 0, i = 1, · · · , p}.
ii
VV t = E n で, V(X t X)V が対角行列になる.
rank(X) = #{lii | lii
0, i = 1, · · · , p}. (0 でない特異値の数)
.
∑ p
Tr(X · X ) = Tr(X · X) =
t t 2
lii
i=1
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 17 / 44
中心化行列
定義 (中心化行列)
自然数 nに対して, E n を n × n 単位行列, 1 n を全成分が 1 の n 次元列ベク
トル, 1 n×n を全成分が 1 の n × n 行列とする. このとき, n × n 行列
J n = E n − 1 1 n×n を中心化行列という.
n .
1∑
n
1
n × p 行列 X に対して, J n X = (E n X − 1 n×n X) = (xi j − x k j ) であ
n n
k=1
∑
n .
り, J n X = (x ) とすると xi j = 0 となる. すなわち, J n X はデータ列 X
ij
i=1
の重心を原点に平行移動したデータ列になる.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 22 / 44
23.
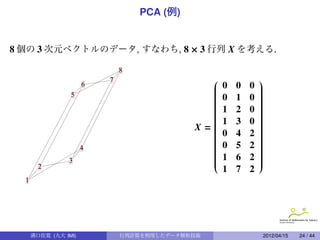
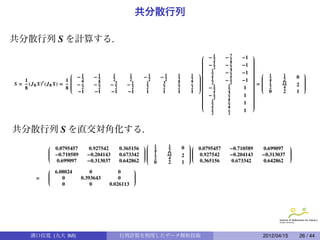
主成分分析 (PCA)
定理 (PrincipalComponent Analysis)
1
n × p 行列 X の共分散行列を p × p 行列 S = (J n X) t (J n X) とする. S を直
n
交対角化して VSV t = Λ となり, Λ = (λi j ) は, λi j = 0 (i j),
λ11 ≥ λ22 ≥ · · · ≥ λ pp ≥ 0 とする. n × p 行列 Y を Y = (J n X) · V t とする
と Y = (y1 , y2 , · · · , y p) = (yi j ) に対して, 次の性質が成り立つ.
∑n
1 yi j = 0 ( j = 1, · · · , p), (yi の平均は 0)
i=1
1 t
2 Y Y = Λ (Y の共分散行列は対角行列で対角成分 (yi の分散) は固有値),
n .
3 Tr(Y t Y) = Tr(S),
4 |Y t Y| = |S|.
変換されたデータ列 Y について, 次のことがわかる. (1) より各成分の平均は全て
0 である. (2) より各成分の分散は第 1 成分から順番に小さくなっている.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 23 / 44
M と Bの関係
問題
n 個のデータ oi = (xi1 , xi2 , · · · , xip) からなる n × p 行列 X = (xi j ) により
.
作られた n × n の内積行列 B = X · X t = ( oi , o j ) と n × n の距離行列
M = (||oi − o j ||) を考える. データ行列 X がわからなくても, 内積行列 B
から距離行列 M を直接計算することが出来るか?
距離行列 M = (mi j ) に対して, 全成分を 2 乗した行列 M(2) = (m2 ) を考え
ij
.
る. (注. M(2) は各成分が 2 乗であり, 行列の 2 乗 M2 とは異なる!)
m2j = ||oi − o j ||2 = oi − o j , oi − o j = oi , oi − 2 oi , o j + o j , o j
i
であるので, B = ( oi , o j ) がわかっていれば, M(2) を計算することが出来
る. 従って, B から M も直接計算することが出来る.
問題
M から B は直接計算出来るか?
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 28 / 44
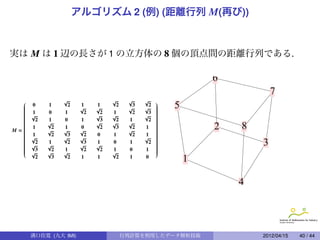
29.
多次元尺度構成法 (MDS)
n 個のデータoi = (xi1 , xi2 , · · · , xip) からなる n × p 行列 X = (xi j ) により
作られた n × n の距離行列 M = (||oi − o j ||) を考える.
問題 (Multidimensional Scaling)
n × n 行列 M = (mi j ) が与えられ, X がわからないときに, 適当な次元 p を
定め, mi j = ||oi − o j || (i = 1, · · · , n, j = 1, · · · , n) となるような, n 個のベ
クトル oi = (xi1 , xi2 , · · · , xip) を求めよ.
.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 29 / 44
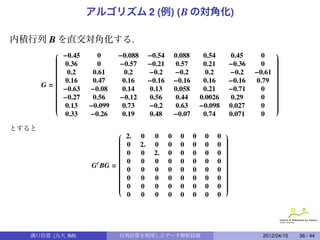
30.
アルゴリズム 2
M を作ったもとのデータ行列X を探す:
1
B c = − J n M(2) J n
t
2
とすると
B c = (J n X)(J n X) t
であることが計算出来る [4].
距離行列 M から内積行列 B c を得る変換 − 1 J n M(2) J n を
2
t
Young-Householder 変換と呼ぶ.
この B c にアルゴリズム 1 を使えばもとのデータ X(を中心化したもの) を見つけ
ることが出来る.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 30 / 44
31.
次元縮小
アルゴリズム 1 は,n × p のデータ行列から作られた内積行列 B = X · X t
が与えられたときに, B を実現する X を求めるアルゴリズムであった.
丁度 B = X · X t である必要はないので, より小さな次元 r(< p) のデータ
行列 X で B を近似出来ないだろうか?
問題
準備で述べた n × n 行列 B = (bi j ) が与えられ, X がわからないとする. 自
然数 r ≤ rank(B) が与えられたとき, Tr((B − X c X c )2 ) を最小にする n × r
t
行列 X c を求めよ.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 . 2012/04/15 31 / 44
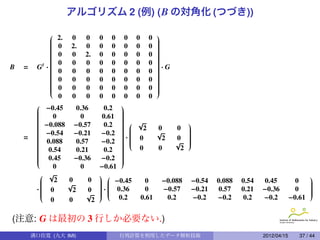
32.
アルゴリズム 3
B を作ったもとのデータ行列X を近似する:
アルゴリズム 1 で, p を r < p に置き換えて,
√
Xc = Ur Λr
とすると X c は n × r 行列となりもとの X よりは次元が小さなデータにな
る. 但し, B = X c X c とは限らない.
t
b ··· u ··· λ ··· u ··· u1n
11
b12 b1n 11
u r1 u p1 11
0 0 11
u12
b
21
b22 b2n u
12
u r2 u p2
.
.
. .
.
. . . . . .
. . = .
. . .
. .
.
.
. . .
.
.
. .
.
. 0
··· λ rr 0 u
r1
u r2 ··· u rn
b n1 b n2 ··· b nn u1n ··· u rn u pn 0 ··· 0 λ pp u p1 u p1 ··· u pn
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 32 / 44
33.
理論背景
定理
n × p行列 X から作られた距離行列 M に対して, n × r 行列 X c の中で Φ
を最小にするのは, アルゴリズム 3 で得られる X c である. そして, Φ の最
∑
n
小値は 2n(λ r+1 + · · · + λ p) となる. 但し, Φ = (d2j − di 2 ) で, di j は X を
i j
i, j=1
.
構成するデータ間の距離 di j = ||oi − o j || であり, d は X c を構成するデー
ij
タ間の距離とする.
定理
n × p 行列 X から作られた内積行列 B に対して, n × r 行列 X c の中で Ψ
を最小にするのは, アルゴリズム 3 で得られる X c である. そして, Ψ の最
小値は (λ2 + · · · + λ2 ) となる. 但し, Ψ = Tr((B − X c X c )2 ) とする.
p
t
r+1 .
定理の証明等は, 文献 [2] を参照のこと.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 33 / 44
PCA と MDSの関係
n × p 行列 J n X を特異値分解して,
J nX = U · L · V t
となったとする. n × n 行列 U は (J n X)(J n X) t を対角化し,
U(J n X)(J n X) t U t = Λ n
となり, p × p 行列 V は (J n X) t (J n X) を対角化し,
V(J n X) t (J n X)V t = Λ p
となる. V は,
1
S=
(J n X) t (J n X)
n
も直交対角化するので, Y = (J n X)V は, 主成分 (PCA) である.
このとき,
Y = (J n X)V = (U · LV t )V = U · L
となる. √
ここで, U · L = U p Λ p なので, Y はアルゴリズム 1 の X c と一致する.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 42 / 44
参考文献
[1] C. Eckartand G. Young.
The approximation of one matrix by another of lower rank.
Psychometrika, 1(3):211–218, 1936.
[2] K.V. Mardia, J.T. Kent, and J.M. Bibby.
Multivariate Analysis.
Academic Press, 1994.
[3] W.S. Torgerson.
Multidimensional scaling: I. theory and method.
Psychometrika, 17(4):401–419, 1952.
[4] G. Young and A.S. Householder.
Discussion of a set of points in terms of their mutual distances.
Psychometrika, 3(1):19–22, 1938.
[5] 小西貞則.
多変量解析入門.
岩波書店, 2010.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 44 / 44





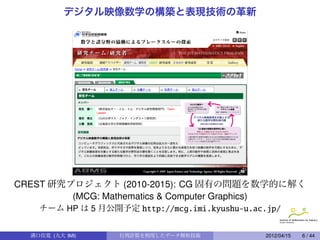


![大量データの話題
「ビッグデータ」と呼ばれる大量データ処理で利用されている技術.
(cf. ギガ (106 ) バイト (G), テラ (1012 ) バイト (T), ペタ (1015 ) バ イト (P))
PCA (主成分分析)
K.Pearson (1901).
高次元データをデータ間の特徴を表す低次元データに圧縮する方法
MDS (多次元尺度構成法)
W.S.Torgerson (1952)[3]
距離の関係がわかっているデータたちを表現する多次元データ座標
を構成する.
SVD (特異値分解)
PCA や MDS の基礎となる線形代数の定理 (行列の対角化の一般化).
C.Eckard and G.Young (1936)[1].
The approximation of one matrix by another of lower rank,
Psychometrika, 1(3). ⇐ 心理学の雑誌
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 9 / 44](https://image.slidesharecdn.com/pcamds-120413052506-phpapp02/85/slide-9-320.jpg)




![特異値分解
定理 (Singular Value Decomposition[1])
n × p 行列 X に対して, n × n 直交行列 U, p × p 直交行列 V が存在し,
X = U · L · V t とすることが出来る. 但し, n × p 行列 L = (li j ) は対角行列
li j = 0 (i j, i = 1, · · · , n, j = 1, · · · , p) である.
そして, このとき次の条件が満たされる.
X · X t は, U で直交対角化され 0 でない固有値の集合は
{l2 | lii 0, i = 1, · · · , p}.
ii
UU t = E n で, U(XX t )U t が対角行列になる.
X t · X は, V で直交対角化され 0 でない固有値の集合は
{l2 | lii 0, i = 1, · · · , p}.
ii
VV t = E n で, V(X t X)V が対角行列になる.
rank(X) = #{lii | lii
0, i = 1, · · · , p}. (0 でない特異値の数)
.
∑ p
Tr(X · X ) = Tr(X · X) =
t t 2
lii
i=1
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 17 / 44](https://image.slidesharecdn.com/pcamds-120413052506-phpapp02/85/slide-17-320.jpg)









![アルゴリズム 2
M を作ったもとのデータ行列 X を探す:
1
B c = − J n M(2) J n
t
2
とすると
B c = (J n X)(J n X) t
であることが計算出来る [4].
距離行列 M から内積行列 B c を得る変換 − 1 J n M(2) J n を
2
t
Young-Householder 変換と呼ぶ.
この B c にアルゴリズム 1 を使えばもとのデータ X(を中心化したもの) を見つけ
ることが出来る.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 30 / 44](https://image.slidesharecdn.com/pcamds-120413052506-phpapp02/85/slide-30-320.jpg)


![理論背景
定理
n × p 行列 X から作られた距離行列 M に対して, n × r 行列 X c の中で Φ
を最小にするのは, アルゴリズム 3 で得られる X c である. そして, Φ の最
∑
n
小値は 2n(λ r+1 + · · · + λ p) となる. 但し, Φ = (d2j − di 2 ) で, di j は X を
i j
i, j=1
.
構成するデータ間の距離 di j = ||oi − o j || であり, d は X c を構成するデー
ij
タ間の距離とする.
定理
n × p 行列 X から作られた内積行列 B に対して, n × r 行列 X c の中で Ψ
を最小にするのは, アルゴリズム 3 で得られる X c である. そして, Ψ の最
小値は (λ2 + · · · + λ2 ) となる. 但し, Ψ = Tr((B − X c X c )2 ) とする.
p
t
r+1 .
定理の証明等は, 文献 [2] を参照のこと.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 33 / 44](https://image.slidesharecdn.com/pcamds-120413052506-phpapp02/85/slide-33-320.jpg)






![参考文献
[1] C. Eckart and G. Young.
The approximation of one matrix by another of lower rank.
Psychometrika, 1(3):211–218, 1936.
[2] K.V. Mardia, J.T. Kent, and J.M. Bibby.
Multivariate Analysis.
Academic Press, 1994.
[3] W.S. Torgerson.
Multidimensional scaling: I. theory and method.
Psychometrika, 17(4):401–419, 1952.
[4] G. Young and A.S. Householder.
Discussion of a set of points in terms of their mutual distances.
Psychometrika, 3(1):19–22, 1938.
[5] 小西貞則.
多変量解析入門.
岩波書店, 2010.
溝口佳寛 (九大 IMI) 行列計算を利用したデータ解析技術 2012/04/15 44 / 44](https://image.slidesharecdn.com/pcamds-120413052506-phpapp02/85/slide-44-320.jpg)















![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)











![[CE94] 高等学校での「プログラミング」教育の導入– PEN を用いて (発表資料)](https://cdn.slidesharecdn.com/ss_thumbnails/ce94-130128015048-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































