Download as PDF, PPTX










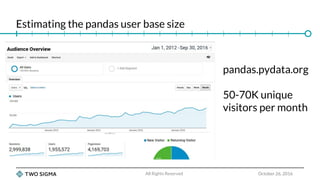




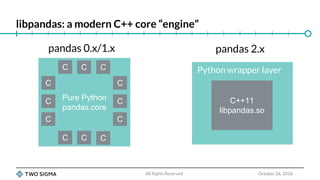


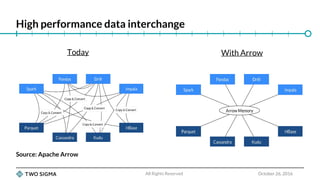





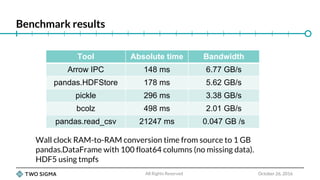


The document is a slide deck for a presentation on Python data wrangling and the future of the pandas project. It discusses the growth of the Python data science community and key projects like NumPy, pandas, and scikit-learn that have contributed to pandas' popularity. It outlines some issues with the current pandas codebase and proposes a new C++-based core called libpandas for pandas 2.0 to improve performance and interoperability. Benchmark results show serialization formats like Arrow and Feather outperforming pickle and CSV for transferring data.























































































