Download as PDF, PPTX









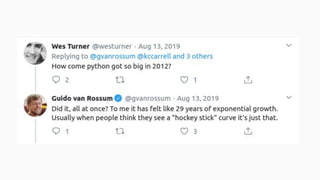
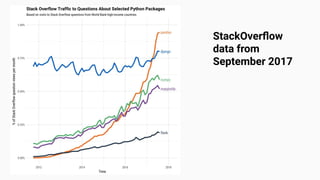
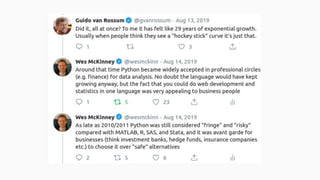










![July 2011- Concerns
"... the current state of affairs has me rather
anxious … these tools [e.g. pandas] have
largely not been integrated with any other tools
because of the community's collective
commitment anxiety"
http://wesmckinney.com/blog/a-roadmap-for-rich-scientific-data-structures-in-python/](https://image.slidesharecdn.com/20200208-pyconcokeynote-200208161648/85/PyCon-Colombia-2020-Python-for-Data-Analysis-Past-Present-and-Future-26-320.jpg)












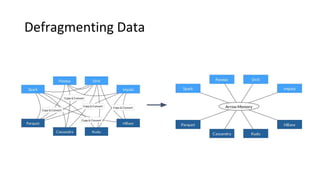


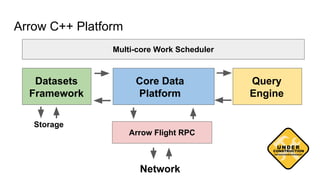









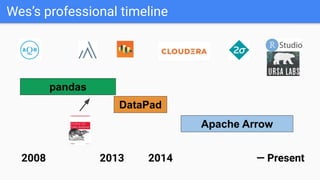
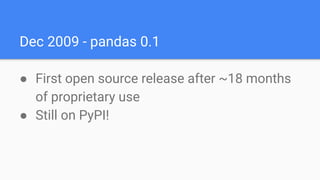
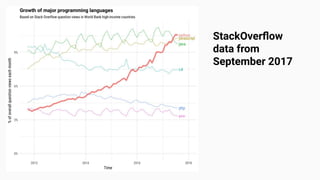
Wes McKinney gave a presentation on the past, present, and future of Python for data analysis. He discussed the origins and development of pandas over the past 12 years from the first open source release in 2009 to the current state. Key points included pandas receiving its first formal funding in 2019, its large community of contributors, and factors driving Python's growth for data science like its package ecosystem and education. McKinney also addressed early concerns about Python and looked to the future, highlighting projects like Apache Arrow that aim to improve performance and interoperability.

![[CB16] Invoke-Obfuscation: PowerShell obFUsk8tion Techniques & How To (Try To...](https://cdn.slidesharecdn.com/ss_thumbnails/cb16bohannonen-161109042710-thumbnail.jpg?width=640&height=640&fit=bounds)














































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















