Downloaded 65 times




![Review: Best Practices
• Tune entire pipeline, not individual models
• How you phrase parameters matters!
– Categoricals really categorical?
• [2,4,8,16,32] à {1,5,1} and 2(param)
– Use transformations to your advantage
• For learning_rate, instead of {0,1} à {-10,0} and 10(param)
• Don’t restrict to traditional hyperparameters
– SGD Flavor
– Architecture
4#UnifiedAnalytics #SparkAISummit](https://image.slidesharecdn.com/043014maneeshbhide-190509215420/85/Advanced-Hyperparameter-Optimization-for-Deep-Learning-with-MLflow-4-320.jpg)



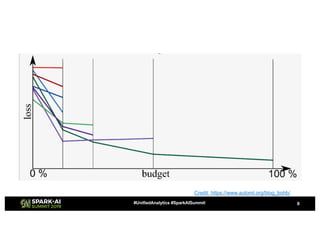

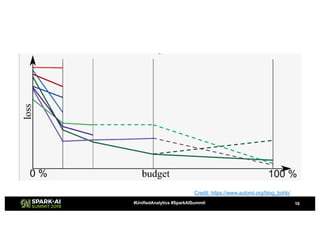


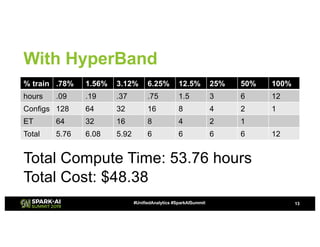


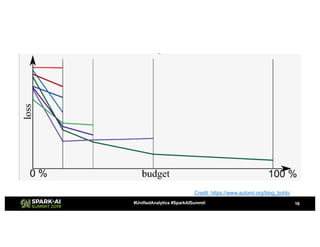










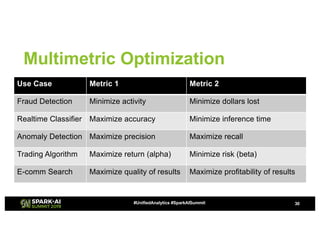


![Fourth Approach
True multimetric optimization
return [{'name': 'f1', 'value': f1_val}, {'name': 'f2', 'value': f2_val}]
• Optimize for competing objectives independently
• Use Surrogates and Acquisition Functions to model
relationship/tradeoff between objectives
35#UnifiedAnalytics #SparkAISummit](https://image.slidesharecdn.com/043014maneeshbhide-190509215420/85/Advanced-Hyperparameter-Optimization-for-Deep-Learning-with-MLflow-35-320.jpg)



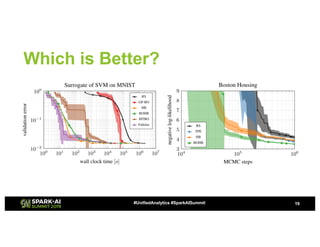
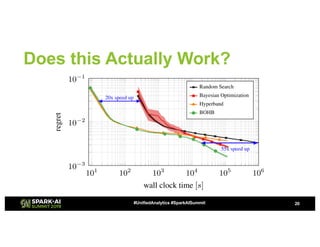
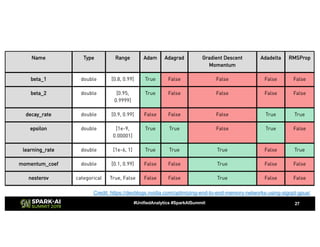
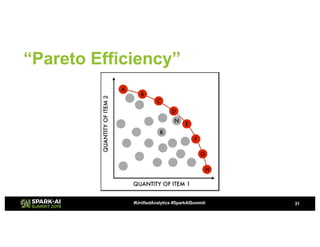
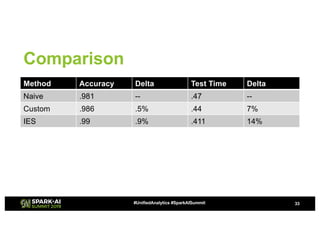
The document discusses advanced hyperparameter optimization (HPO) techniques for deep learning, highlighting various methods like grid search, random search, population-based methods, and Bayesian optimization, along with their respective pros and cons. It emphasizes the need for tuning the entire pipeline rather than individual models and optimizing resource allocation for significant reductions in compute and costs. Additionally, it explores challenges in sequential training, trading off objectives, and the application of multimetric optimization.





![[Phd Thesis Defense] CHAMELEON: A Deep Learning Meta-Architecture for News Re...](https://cdn.slidesharecdn.com/ss_thumbnails/chameleondefesadoutorado1-191209202516-thumbnail.jpg?width=640&height=640&fit=bounds)

















































































