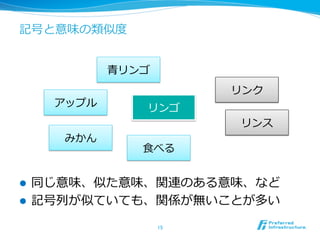
分布仮説 (Distributional Hypothesis)
l 同じ⽂文脈で出現する単語は同じ意味を持つとい
うこと
l データから単語の意味を学習する話は、少なか
らずこの仮説が元になっている
16
The Distributional Hypothesis is that words
that occur in the same contexts tend to have
similar meanings (Harris, 1954). (ACL wikiより)
参考⽂文献
l [Evert10] StefanEvert.
Distributional Semantic Models. NAACL 2010 Tutorial.
l [Mikolov+13a] Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey
Dean.
Efficient Estimation of Word Representations in Vector Space.
CoRR, 2013.
l [Morin+05] Frederic Morin, Yoshua Bengio.
Hierarchical Probabilistic Neural Network Language Model.
AISTATS, 2005.
l [Mikolov+13c] Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory
S. Corrado, Jeffrey Dean.
Distributed Representations of Words and Phrases and their
Compositionality. NIPS, 2013.
97
98.
参考⽂文献
l [Kim+13] Joo-KyungKim, Marie-Catherine de Marneffe.
Deriving adjectival scales from continuous space word
representations. EMNLP, 2013.
l [Mikolov+13d] Tomas Mikolov, Quoc V. Le, Ilya Sutskever.
Exploiting Similarities among Languages for Machine
Translation. CoRR, 2013.
l [Neelakantan+14] Arvind Neelakantan, Jeevan Shankar,
Alexandre Passos, Andrew McCallum.
Efficient Non-parametric Estimation of Multiple Embeddings
per Word in Vector Space. EMNLP, 2014.
l [Le+14] Quoc Le, Tomas Mikolov.
Distributed Representations of Sentences and Documents.
ICML, 2014.
98
99.
参考⽂文献
l [Hochreiter+97] SeppHochreiter, Jurgen Schmidhunber.
Long Short-Term Memory. Neural Computation 9(8), 1997.
l [Mikolov+10] Tomas Mikolov, Martin Karafiat, Lukas Burget, Jan
Honza Cernocky, Sanjeev Khudanpur.
Recurrent neural network based language model.
Interspeech, 2010.
l [Graves13] Alex Graves.
Generating Sequences With Recurrent Neural Networks. arXiv:
1308.0850, 2013.
l [Vinyal+15a] Oriol Vinyals, Alexander Toshev, Samy Bengio,
Dumitru Erhan.
Show and tell: A neural image caption generator. CVPR, 2015.
99
100.
参考⽂文献
l [Sutskever+14] IlyaSutskever, Oriol Vinyals, Quoc V. Le.
Sequence to Sequence Learning with Neural Networks.
NIPS 2014.
l [Vinyals+15b] Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav
Petrov, Ilya Sutskever, Geoffrey Hinton.
Grammar as a foreign language.
ICLR 2015.
l [Vinyals+15c] Oriol Vinyals, Quoc Le.
A Neural Conversational Model. ICML 2015.
100
101.
参考⽂文献
l [Socher+11] RichardSocher, Cliff Lin, Andrew Y. Ng, Christopher D.
Manning.
Parsing Natural Scenes and Natural Language with Recursive Neural
Networks. ICML 2011
l [Socher+12] Richard Socher, Brody Huval, Christopher D. Manning,
Andrew Y. Ng.
Semantic Compositionality through Recursive Matrix-Vector Spaces.
EMNLP2012.
l [Socher+13] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang,
Chris Manning, Andrew Ng, Chris Potts.
Recursive Deep Models for Semantic Compositionality Over a
Sentiment Treebank. EMNLP 2013.
l [Tai+15] Kai Sheng Tai, Richard Socher, Christopher D. Manning.
Improved Semantic Representations From Tree-Structured Long
Short-Term Memory Networks. ACL 2015.
101
102.
参考⽂文献
l [Bordes+11] A.Bordes, J. Weston, R. Collobert, Y. Bengio.
Learning structured embeddings of knowledge bases. AAAI2011.
l [Bordes+13] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, O.
Yakhnenko.
Translating Embeddings for Modeling Multi-relational Data. NIPS
2013.
l [Fan+14] M. Fan, Q. Shou, E. Chang, T. F. Zheng.
Transition-based Knowledge Graph Embedding with Relational
Mapping Properties. PACLIC 2014.
l [Wang+14] Z. Wang, J. Zhang, J. Feng, Z. Chen.
Knowledge Graph Embedding by Translating on Hyperplanes. AAAI
2014.
l [Bordes&Weston14] A. Bordes, J. Weston.
Embedding Methods for Natural Language Processing. EMNLP2014
tutorial.
102
103.
参考⽂文献
l [Peng+15a] BaolinPeng, Kaisheng Yao.
Recurrent Neural Networks with External Memory for Language
Understanding. arXiv:1506.00195, 2015.
l [Weston+15] J. Weston, S. Chopra, A. Bordes.
Memory Networks. ICLR 2015.
l [Sukhbaatar+15] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob
Fergus.
End-To-End Memory Networks. arXiv:1503.08895, 2015.
l [Kumar+15] Ankit Kumar, Ozan Irsoy, Jonathan Su, James Bradbury, Robert
English, Brian Pierce, Peter Ondruska, Ishaan Gulrajani, Richard Socher.
Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing. arXiv:1506.07285, 2015.
l [Peng+15b] Baolin Peng, Zhengdong Lu, Hang Li, Kam-Fai Wong.
Towards Neural Network-based Reasoning. arXiv:1508.05508, 2015.
l [Kiros+15] Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel,
Antonio Torralba, Raquel Urtasun, Sanja Fidler.
Skip-Thought Vectors. arXiv:1506.06726, 2015.
103

















![問題:???の単語は何でしょう?
17
[Evert10]より抜粋
ヒント:この表は各単語同士の共起頻度を表している](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-17-320.jpg)
![問題:???の単語は何でしょう?
18
[Evert10]より抜粋
ヒント2:catやpigと共起語が似ていて、knifeと似てない](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-18-320.jpg)
![正解:dog
19
[Evert10]より抜粋](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-19-320.jpg)
![word2vec [Mikolov+13]
l 各単語の「意味」を表現するベクトルを作るはなし
l vec(Berlin) – vec(German) + vec(France) と⼀一番近い単
語を探したら、vec(Paris)だった
l ベクトルの作り⽅方は次のスライドで説明
20
Berlin
German
France
Paris!!](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-20-320.jpg)
![Skip-gramモデル (word2vec) [Mikolov+13a]
l 周辺単語を予測するモデル
l 周辺単語から予測するモデル
(CBOW)も提案している
l Analogical reasoningの精
度度が劇的に向上
l ⾼高性能な実装が公開された
ため、⼤大流流⾏行行した
21
[Mikolov+13a]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-21-320.jpg)
![Skip-gramモデル[Mikolov+13a]の⽬目的関数
l ⼊入⼒力力コーパス: w1, w2, …, wT (wiは単語)
22
これを最
⼤大化
vwは単語wを表現するようなベクトル(適当な
次元)で、これらを推定したい
cは文脈サイズで5くらい](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-22-320.jpg)

![⼯工夫1: Hierarchical Softmax (HSM) [Morin+05]
l 単語で⽊木を作り、ルートからその単語までの各ノードの
ベクトルと内積をとり、そのシグモイドの積にする
l 計算量量が語彙数の対数時間になる
l 学習時間が数⽇日から数分に24
りんご みかん カレー ラーメン
n1 n2
n3
各ノードのベ
クトル
ルートからw
までの全ノー
ドで積をとる
σ(x)=1/(1 + exp(-x))](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-24-320.jpg)
![⼯工夫2: Negative Sampling [Mikolov+13b]
l ∑の中の期待値計算は、k個のサンプルを取って
近似する
l データが少ない時は5~20個、多ければ2~5個で充分
l P(w)として、1-gram頻度度の3/4乗に⽐比例例させた
ときが⼀一番良良かった
25
log P(wo|wI) =](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-25-320.jpg)


![意味の「程度度」がベクトル空間中に埋め込まれる
[Kim+13]
l “good”と”best”の真ん中に、”better”が存在
28
[Kim+13]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-28-320.jpg)
![⾔言語間の翻訳辞書ができる [Mikolov+13c]
l 単⾔言語のコーパスで作られた表現ベクトルは似ている
l 少ない対訳辞書で作った、表現ベクトル空間の線形変換
を作る
29
英語
スペイン語
[Mikolov+13c]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-29-320.jpg)
![複数の意味を持たせて、⽂文脈に応じて選択
[Neelakantan+14]
30
文脈を認識
一番類似した意味を選択
Skip-gramと同じ
[Neelakantan+14]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-30-320.jpg)
![⽂文書のベクトル表現(Paragraph vector) [Le+14]
l 周囲の単語に加えて、⽂文書固有のベクトル
(Paragraph vector)も単語の予測に使う
l このベクトルで⽂文書分類すると性能が向上する
31
Continuous BoW
Paragraph vector
[Le+14]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-31-320.jpg)




![Long Short-Term Memory [Hochreiter+97]
l 勾配が消えないようにエラーを内部に貯めこむ構造に
なっている
l ⼊入出⼒力力のゲートを作って、情報を選択的に流流すようにす
る(流流すタイミングを学習するイメージ)
41
情報が貯まる
出⼒力力タイ
ミング
⼊入⼒力力タイ
ミング
gateの出⼒力力が1に近い時だけ影響する](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-41-320.jpg)
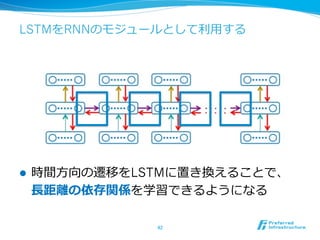

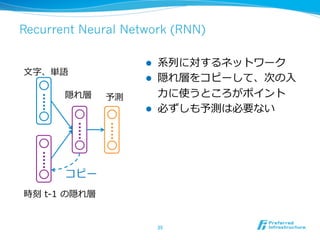
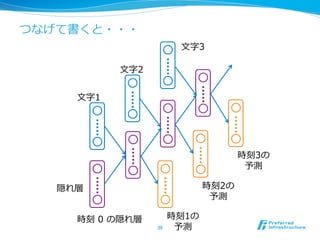
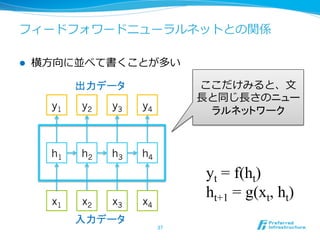
![RNNの⾔言語モデルへの利利⽤用 [Mikolov+10]
l ⼊入⼒力力は単語列列、出⼒力力は次の単語
l 副次的に単語毎にベクトルが学習される
44
今日
は
天気
だ
は
天気
だ
<eos>
単語毎に確率率率が出る](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-44-320.jpg)


![LSTM⾔言語モデルの強⼒力力さ [Graves13]
47
閉じタグが正確に復復元タグの出現順も正しい
⽂文の構造も復復元
[Graves13]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-47-320.jpg)


![Show and Tell [Vinyals+15a]
l 画像を畳み込みニューラルネットワーク
(CNN)でエンコードして、そこからRNNで⽂文
を⽣生成する
l 画像を説明するような⽂文の⽣生成に成功
50
[Vinyals+15a]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-50-320.jpg)
![Sequence-to-sequence learning (seq2seq)
l ⼊入⼒力力⽂文をRNNでエンコードして、そこからRNN
で出⼒力力⽂文を⽣生成する
l ⽂文から⽂文の変換を学習できる
51
入力文
出力文
[Sutskever+14]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-51-320.jpg)
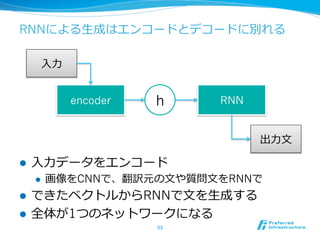
![seq2seqが複数のタスクで成果を上げる
l 機械翻訳 [Sutskever+14]
l 原⽂文から翻訳⽂文へ
l 構⽂文解析 [Vinyals+15b]
l ⽂文から構⽂文⽊木(のS式表現)へ
l 対話 [Vinyals+15c]
l 相⼿手の発話から⾃自分の発話へ
52
WSJの記事になった](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-52-320.jpg)

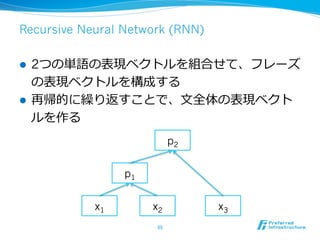
![RNNによる構⽂文解析 [Socher+11]
l 隣隣接単語からフレーズを
構成する
l 構成を繰り返すことで、
⽊木ができる
l 画像の構造推定にも使え
る
56
[Socher+13]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-56-320.jpg)
![Matrix-Vector RNN (MV-RNN) [Socher+12]
l 各フレーズは⾏行行列列とベクトルのペアで表現する
l ⼀一⽅方のベクトルを、もう⼀一⽅方の⾏行行列列との積を
取ってから、ベクトルを合成する
57
[Socher+12]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-57-320.jpg)
![Neural Tensor Network (NTN) [Socher+13]
l 3階のテンソルを使って、2つのベクトルから、
1つのベクトルを⽣生成する
58
[Socher+13]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-58-320.jpg)
![RNNによる評判分析 [Socher+13]
l 構⽂文⽊木に沿って句句のベクトルを再帰的に構築し
て、ポジ・ネガ分類をする
l 各フレーズ単位でも判定ができる
59
[Socher+13]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-59-320.jpg)
![Tree-LSTM [Tai+15]
l ベクトルの合成にLSTMを利利⽤用する
l 実験結果を⾒見見ると、受け⾝身になった⽂文でも⽂文意
が変わらないことを学習できている
60
c: メモリセル
h:隠れ状態
[Tai+15]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-60-320.jpg)









![Distance model (Structured Embedding) [Bordes
+11]
l e は、単語からベクトルへの関数
l Rleft, Rright は、関係から⾏行行列列への関数
l それぞれ別々の変換を⾏行行う
l 学習データに対する f が⼩小さくなるように学習
74
f(x, r, y) = || Rleft(r) e(x) – Rright(r) e(y) ||1](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-74-320.jpg)
![TransE model [Brodes+13]
l 関係 r は、ベクトル r を⾜足すだけというシンプ
ルなモデル
l 良良好な結果で、ベースライン的扱い
75
f(x, r, y) = || e(x) + r – e(y) ||2
2](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-75-320.jpg)

![TransM model [Fan+14]
l r に応じて、重みをつける
l wr は、r の関係をもつ x, y の個数から決まる定数
77
f(x, r, y) = wr|| e(x) + r – e(y) ||2
2
[Fan+14]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-77-320.jpg)
![TransH model [Wang+14]
l 関係毎に超平⾯面上に射影して、その上でTransE
と同じモデル化をする
78
[Wang+14]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-78-320.jpg)

![⽐比較すると新しい⼿手法のほうが性能は良良い
80
TransH
TransE
⾏行行列列分解
図は[Bordes&Weston14]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-80-320.jpg)



![RNN-EM [Peng+15a]
l RNNに外部メモリ(External Memory)を追加
してより⻑⾧長い依存関係を学習
l 書き込み、読み込み操作も学習84
⼊入⼒力力単語
出⼒力力単語
隠れ状態
外部メモリ
書き込み
読み込み
[Peng+15a]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-84-320.jpg)
![Memory networks [Weston+15][Sukhbaatar+15]
l ⾃自然⽂文の知識識をエンコードして、質問⽂文から答
えを探し答えるまでを1つのネットワークに
85
外部の⽂文献
知識識表現 質問⽂文
知識識の探索索
回答の⽣生成
[Sukhbaatar+15]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-85-320.jpg)
![Neural Reasoner [Peng+15b]
l 質問(q)と事実(fi)から、推論論を⾏行行うイメージ
l この推論論を何回も⾏行行うと、結論論が得られる
86
質問と事実をRNNでエンコード
1段の推論論
最後に回答
推論論を何度度も [Peng+15b]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-86-320.jpg)




![Skip-thought vectors [Kiros+15]
l RNNで⽂文をエンコードし、周囲の⽂文を推定する
l Skip-gramモデルを⽂文に適⽤用したイメージ
91
前の⽂文を予測
次の⽂文を予測
⽂文をエンコード
[Kiros+15]より](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-91-320.jpg)




![参考⽂文献
l [Evert10] Stefan Evert.
Distributional Semantic Models. NAACL 2010 Tutorial.
l [Mikolov+13a] Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey
Dean.
Efficient Estimation of Word Representations in Vector Space.
CoRR, 2013.
l [Morin+05] Frederic Morin, Yoshua Bengio.
Hierarchical Probabilistic Neural Network Language Model.
AISTATS, 2005.
l [Mikolov+13c] Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory
S. Corrado, Jeffrey Dean.
Distributed Representations of Words and Phrases and their
Compositionality. NIPS, 2013.
97](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-97-320.jpg)
![参考⽂文献
l [Kim+13] Joo-Kyung Kim, Marie-Catherine de Marneffe.
Deriving adjectival scales from continuous space word
representations. EMNLP, 2013.
l [Mikolov+13d] Tomas Mikolov, Quoc V. Le, Ilya Sutskever.
Exploiting Similarities among Languages for Machine
Translation. CoRR, 2013.
l [Neelakantan+14] Arvind Neelakantan, Jeevan Shankar,
Alexandre Passos, Andrew McCallum.
Efficient Non-parametric Estimation of Multiple Embeddings
per Word in Vector Space. EMNLP, 2014.
l [Le+14] Quoc Le, Tomas Mikolov.
Distributed Representations of Sentences and Documents.
ICML, 2014.
98](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-98-320.jpg)
![参考⽂文献
l [Hochreiter+97] Sepp Hochreiter, Jurgen Schmidhunber.
Long Short-Term Memory. Neural Computation 9(8), 1997.
l [Mikolov+10] Tomas Mikolov, Martin Karafiat, Lukas Burget, Jan
Honza Cernocky, Sanjeev Khudanpur.
Recurrent neural network based language model.
Interspeech, 2010.
l [Graves13] Alex Graves.
Generating Sequences With Recurrent Neural Networks. arXiv:
1308.0850, 2013.
l [Vinyal+15a] Oriol Vinyals, Alexander Toshev, Samy Bengio,
Dumitru Erhan.
Show and tell: A neural image caption generator. CVPR, 2015.
99](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-99-320.jpg)
![参考⽂文献
l [Sutskever+14] Ilya Sutskever, Oriol Vinyals, Quoc V. Le.
Sequence to Sequence Learning with Neural Networks.
NIPS 2014.
l [Vinyals+15b] Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav
Petrov, Ilya Sutskever, Geoffrey Hinton.
Grammar as a foreign language.
ICLR 2015.
l [Vinyals+15c] Oriol Vinyals, Quoc Le.
A Neural Conversational Model. ICML 2015.
100](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-100-320.jpg)
![参考⽂文献
l [Socher+11] Richard Socher, Cliff Lin, Andrew Y. Ng, Christopher D.
Manning.
Parsing Natural Scenes and Natural Language with Recursive Neural
Networks. ICML 2011
l [Socher+12] Richard Socher, Brody Huval, Christopher D. Manning,
Andrew Y. Ng.
Semantic Compositionality through Recursive Matrix-Vector Spaces.
EMNLP2012.
l [Socher+13] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang,
Chris Manning, Andrew Ng, Chris Potts.
Recursive Deep Models for Semantic Compositionality Over a
Sentiment Treebank. EMNLP 2013.
l [Tai+15] Kai Sheng Tai, Richard Socher, Christopher D. Manning.
Improved Semantic Representations From Tree-Structured Long
Short-Term Memory Networks. ACL 2015.
101](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-101-320.jpg)
![参考⽂文献
l [Bordes+11] A. Bordes, J. Weston, R. Collobert, Y. Bengio.
Learning structured embeddings of knowledge bases. AAAI2011.
l [Bordes+13] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, O.
Yakhnenko.
Translating Embeddings for Modeling Multi-relational Data. NIPS
2013.
l [Fan+14] M. Fan, Q. Shou, E. Chang, T. F. Zheng.
Transition-based Knowledge Graph Embedding with Relational
Mapping Properties. PACLIC 2014.
l [Wang+14] Z. Wang, J. Zhang, J. Feng, Z. Chen.
Knowledge Graph Embedding by Translating on Hyperplanes. AAAI
2014.
l [Bordes&Weston14] A. Bordes, J. Weston.
Embedding Methods for Natural Language Processing. EMNLP2014
tutorial.
102](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-102-320.jpg)
![参考⽂文献
l [Peng+15a] Baolin Peng, Kaisheng Yao.
Recurrent Neural Networks with External Memory for Language
Understanding. arXiv:1506.00195, 2015.
l [Weston+15] J. Weston, S. Chopra, A. Bordes.
Memory Networks. ICLR 2015.
l [Sukhbaatar+15] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob
Fergus.
End-To-End Memory Networks. arXiv:1503.08895, 2015.
l [Kumar+15] Ankit Kumar, Ozan Irsoy, Jonathan Su, James Bradbury, Robert
English, Brian Pierce, Peter Ondruska, Ishaan Gulrajani, Richard Socher.
Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing. arXiv:1506.07285, 2015.
l [Peng+15b] Baolin Peng, Zhengdong Lu, Hang Li, Kam-Fai Wong.
Towards Neural Network-based Reasoning. arXiv:1508.05508, 2015.
l [Kiros+15] Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel,
Antonio Torralba, Raquel Urtasun, Sanja Fidler.
Skip-Thought Vectors. arXiv:1506.06726, 2015.
103](https://image.slidesharecdn.com/20150831jcsssummer-150901075627-lva1-app6892/85/slide-103-320.jpg)






























![[DL輪読会] Hybrid computing using a neural network with dynamic external memory](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawadnc-161220014044-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)




![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)





















