Download as PDF, PPTX






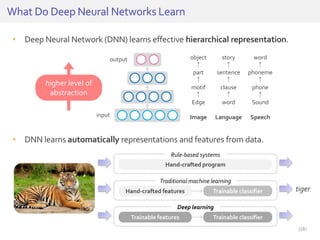
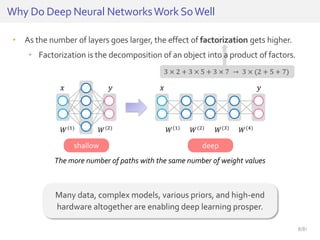
![History ofArtificial Neural Networks
Minsky and Papert, 1969
“Perceptrons”
(Limits of Perceptrons) [M69]
Rosenblatt, 1958
Perceptron [R58]
Fukushima, 1980
NeoCognitron
(Convolutional NN) [F80]
Hinton, 1983
Boltzmann
machine [H83]
Fukushima, 1975
Cognitron (Autoencoder) [F75]
Hinton, 1986
RBM, Restricted
Boltzmann machine [H86]
Hinton, 2006
Deep Belief
Networks [H06]
(mid 1980s)
Back-propagation
Early Models
Basic Models
Break
through
Le, 2012
Training of 1 billion
parameters [L12]
Lee, 2009
Convolutional
RBM [L09]
LeCun, 1998
Revisit of CNN [L98]
http://www.technologyrevi
ew.com/featuredstory/5136
96/deep-learning/
9/81](https://image.slidesharecdn.com/seminar20160104taehoonlee-170514123810/85/PhD-Defense-9-320.jpg)
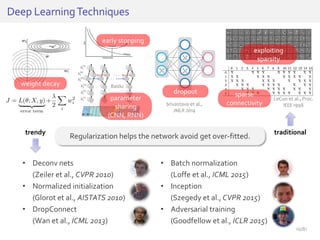








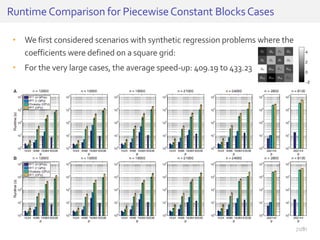
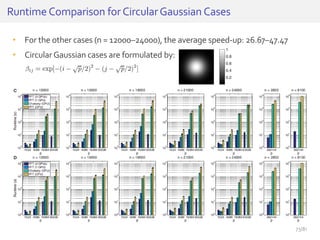
![• Consider the dot product between a weight vector w and an adversarial
example 𝑥 𝑎𝑑𝑣:
• The adversarial perturbation causes the activation to grow by 𝑤 𝑇∆𝑥.
• We can maximize this increase subject to max norm constraint on ∆𝑥 by
assigning ∆𝑥 = sign(𝑤).
HowCanWe Fool Neural Networks?
𝑤 𝑇 𝑥 𝑎𝑑𝑣 = 𝑤 𝑇 𝑥 + 𝑤 𝑇∆𝑥
𝑥 𝑎𝑑𝑣 = 𝑥 − 𝜀𝑤 if 𝑥 is positive
𝑥 𝑎𝑑𝑣 = 𝑥 + 𝜀𝑤 if 𝑥 is negative
𝑤 = [8.28, 10.03]𝑥
24/81](https://image.slidesharecdn.com/seminar20160104taehoonlee-170514123810/85/PhD-Defense-24-320.jpg)













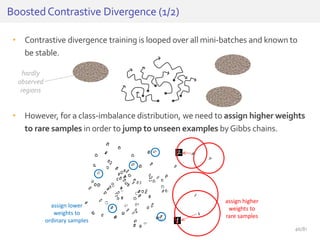

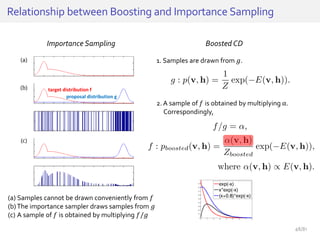




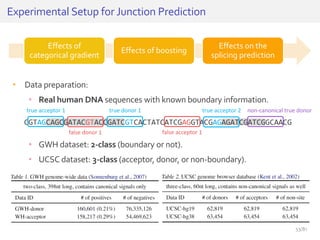
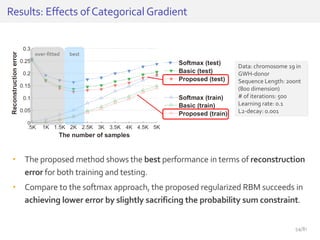
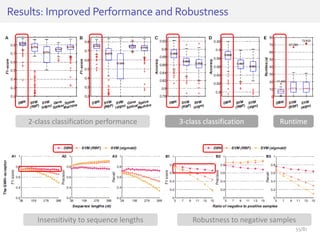
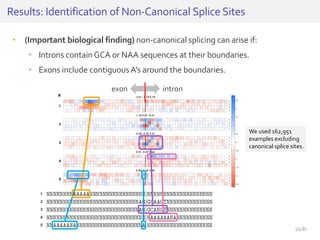
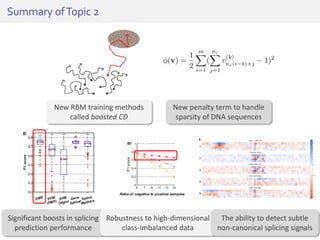








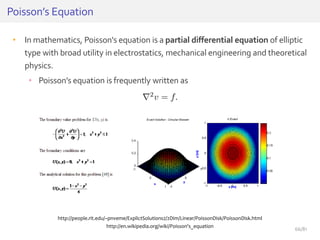














The document discusses deep neural networks (DNNs) and their applications, focusing on issues such as adversarial examples, class imbalance, and spatial dependency handling. It outlines various methodological advancements and research contributions from Taehoon Lee, including manifold regularized DNNs and enhancements in data representation. The implications of DNNs for areas like bioinformatics, image recognition, and natural language processing are highlighted, alongside providing a comprehensive overview of the author's research achievements and ongoing work.


















































![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)