


![6
Recurrent Neural Networks
Long History!
RTRL
TDNN
BPTT
NARX
[Robinson and Fallside 1987]
[Waibel 1987]
[Werbos 1988]
[Lin et al. 1996]](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-6-2048.jpg)
![St: hidden state
“The LSTM’s main idea is that, instead of compuEng St from St-1
directly with a matrix-vector product followed by a nonlinearity,
the LSTM directly computes St, which is then added to St-1 to
obtain St.” [Jozefowicz et al. 2015]
7
RNN: Long Short-Term Memory
Over 20 yrs!
Neural Computation, 1997
*
* Figure borrowed from http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Resistant to vanishing gradient problem
Achieve better results when dropout is used
Adding bias of 1 to LSTM’s forget gate(a) Forget gate (b) Input gate
(c) Output gate](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-7-2048.jpg)
![9
Forecasting
Financial
Translation
Machine
Synthesis
Speech
Modeling
NLP
Sequence Modeling
!
!
!
!
[1] “A Critical Review of Recurrent Neural Networks for Sequence Learning”, by Lipton et al., 2015. (https://arxiv.org/abs/1506.00019)
[2] “Sequence to sequence learning with Neural Networks”, by Sutskever et al., 2014. (https://arxiv.org/abs/1409.3215)](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-9-2048.jpg)
![10
Alternatives
To RNNs
TCN*
Temporal Convolutional Network
=
1D Fully-Convolueonal Network
+
Causal convolueons
Assumptions and Optimizations
“Stability”
Dilation
Residual Connections
Advantages
Inference Speed
Parallelizability
Trainability
Feed Forward Models#
Gated-Convolutional Language Model
Universal Transformer
WaveNet
ù
ù
* "An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling", by Bai et al. 2018. (https://arxiv.org/pdf/1803.01271.pdf)
# “When Recurrent Models Don't Need to be Recurrent”, by Miller and Hardt, 2018. (https://arxiv.org/pdf/1805.10369.pdf)
“… the “infinite memory” advantage of RNNs is largely absent in practice.”
“The preeminence enjoyed by recurrent networks in sequence modeling may be largely a vestige of history.”
[Bai et al. 2018]
{](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-10-2048.jpg)


![18
Pearson
[Pearson 1900]
Goodman and Kruskal 𝛾
[Goodman and Kruskal ’54]
Kandal 𝜏
[Kendall ‘38]
Spearman 𝜌
[Spearman 1904, 1906]
Somer’s D
[Somer ’62]
Cohen’s 𝜅
[Cohen ‘60]
Cramer’s V
[Cramer '46]
Correlation Coefficients
Different Flavors](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-18-2048.jpg)


![22
Feature Extraction
[Fu et al. 2008]
Correlation
Embedding Analysis
Feature Extraction
[Fu et al. 2008]
Correlational PCA
Common Representation Learning
[Chandar et al. 2017]
Correlational NN
Face Detection
[Deng et al. 2017]
Correlation Loss
Object Tracking
[Valmadre et al. 2017]
CFNet
LEVERAGING CORRELATION
Deep Learning Context](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-22-2048.jpg)
![23
Loss Functions
Different Flavors
Class separability of features (minimize interclass correlation)
Softmax Loss
Improved Triplet Loss [Cheng et al. 2016]
Triplet Loss [Schroff et al. 2015]
Center Invariant Loss [Wu et al. 2017]
Center Loss [Wen et al. 2016]
Larger inter-class variaeon and a smaller intra-class variaeon
Quadruplet Loss [Chen et al. 2017]
Separability and discriminatory ability of features
(maximize intraclass correlation)
Correlation Loss [Deng et al. 2017]](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-23-2048.jpg)
![Correlation Loss
Deep Dive
Normalization
Non-linearly changes the distribution
Yields non-Gaussian distribution
Uncentered Pearson Correlation
Angle similarity
Insensitive to anomalies
Enlarge margins amongst different classes
Softmaxloss
Correlationloss
Distribution of Deeply Learned Features*
* Figure borrowed from [Deng et al. 2017].](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-24-2048.jpg)
![25
CANONICAL CORRELATION ANALYSIS
Common Representation Learning
Deep Generalized
[Benton et al. 2017]
Deep Discriminative
[Dorfer and Widmer 2016]
Deep Variational
[Wang et al. 2016]
Soft Decorrelation
[Chang et al. 2017]
Maximize correlation of the views when projected to a common subspace
Minimize self and cross-reconstruction error and maximize correlation
Leverage CRL for transfer learning - high commercial potential](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-25-2048.jpg)



![34
[Werbos ’74]
Beyond Regression: New Tools for Prediction
and Analysis in the Behavioral Sciences
[Parker ’82]
Learning Logic
[Rumelhart, Hinton and Williams ‘86]
Learning internal representations by error
propagation
[Lippmann ’87]
An introduction to computing with neural
networks](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-34-2048.jpg)
![35
[Widrow and Lehr ’90]
30 Years of Adaptive Neural Networks:
Perceptron, Madaline, and Backpropagation
[Wang and Raj ’17]
On the Origin of Deep Learning
[Arulkumaran et al. ’17]
A Brief Survey of Deep Reinforcement Learning
[Alom et al. ’18]
The History Began from AlexNet: A
Comprehensive Survey on Deep
Learning Approaches](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-35-2048.jpg)
![36
[Higham and Higham ’18]
Deep Learning: An Introduceon
for Applied Mathemaecians
[Marcus ’18]
Deep Learning: A Criecal Appraisal](https://image.slidesharecdn.com/oreillyaisf2018-180911000919/75/Deep-Learning-for-Time-Series-Data-36-2048.jpg)







The document discusses deep learning techniques for time series data, focusing on applications such as anomaly detection and forecasting. It covers various neural network architectures like LSTMs and alternatives like temporal convolutional networks, as well as challenges in modeling high-dimensional time series data. Additionally, it addresses methodologies for feature extraction, correlation analysis, and loss functions relevant to deep learning in time series contexts.
Overview of deep learning application in time series data presented by Arun Kejariwal at The AIconf, September 2018.
Introduction to the presenter, focusing on building and scaling teams, performance, and advancing technology.
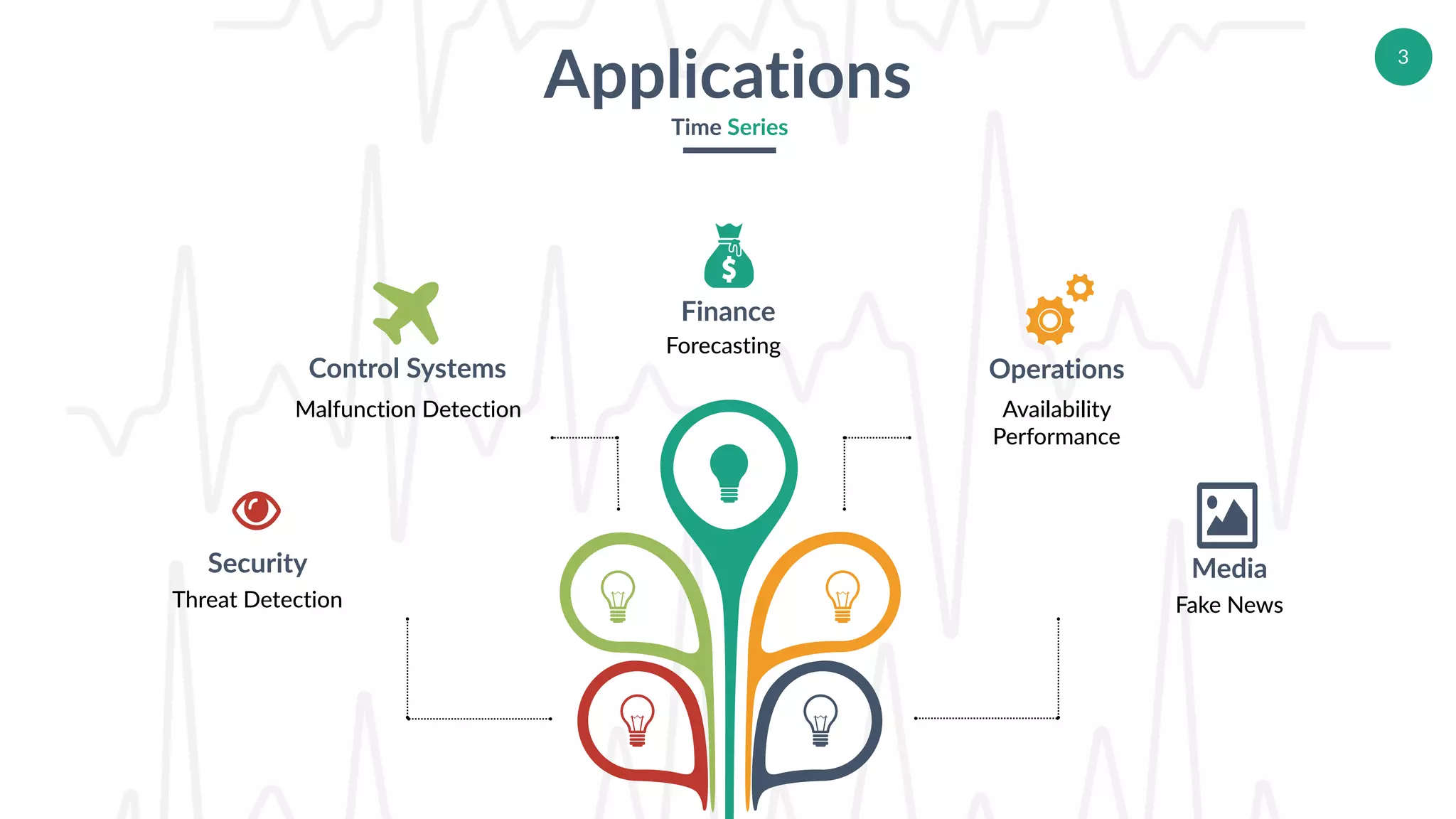
Discussion on various applications of time series including media, finance, and operational performance.
Overview of traditional techniques including ARIMA, Kalman filters, and clustering methods for time series analysis.
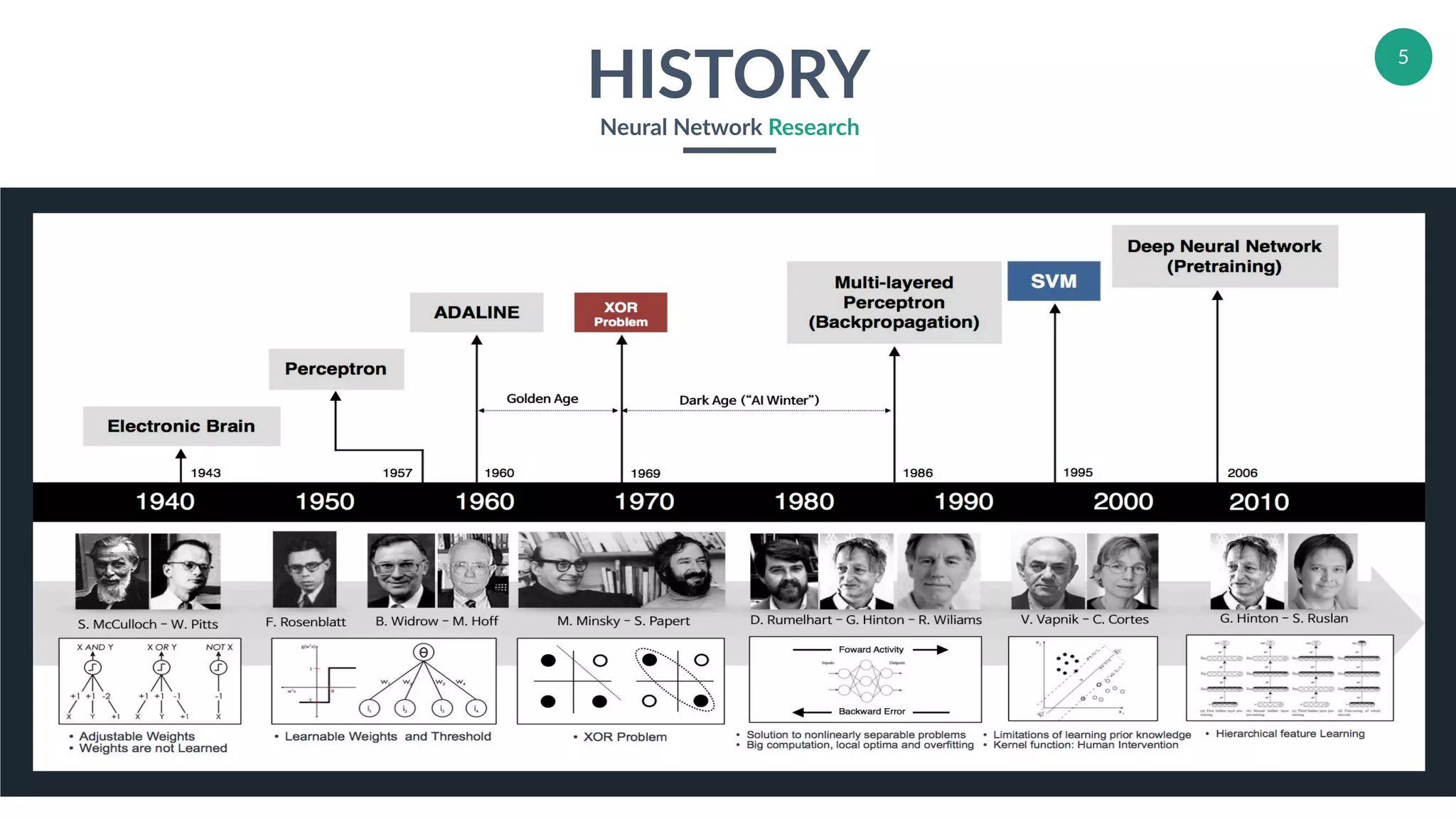
Brief history emphasizing developments within neural network research.
Discussion of early recurrent neural networks and their foundational contributions to the field.
Detailed explanation of the LSTM architecture focusing on its resilience to the vanishing gradient problem.
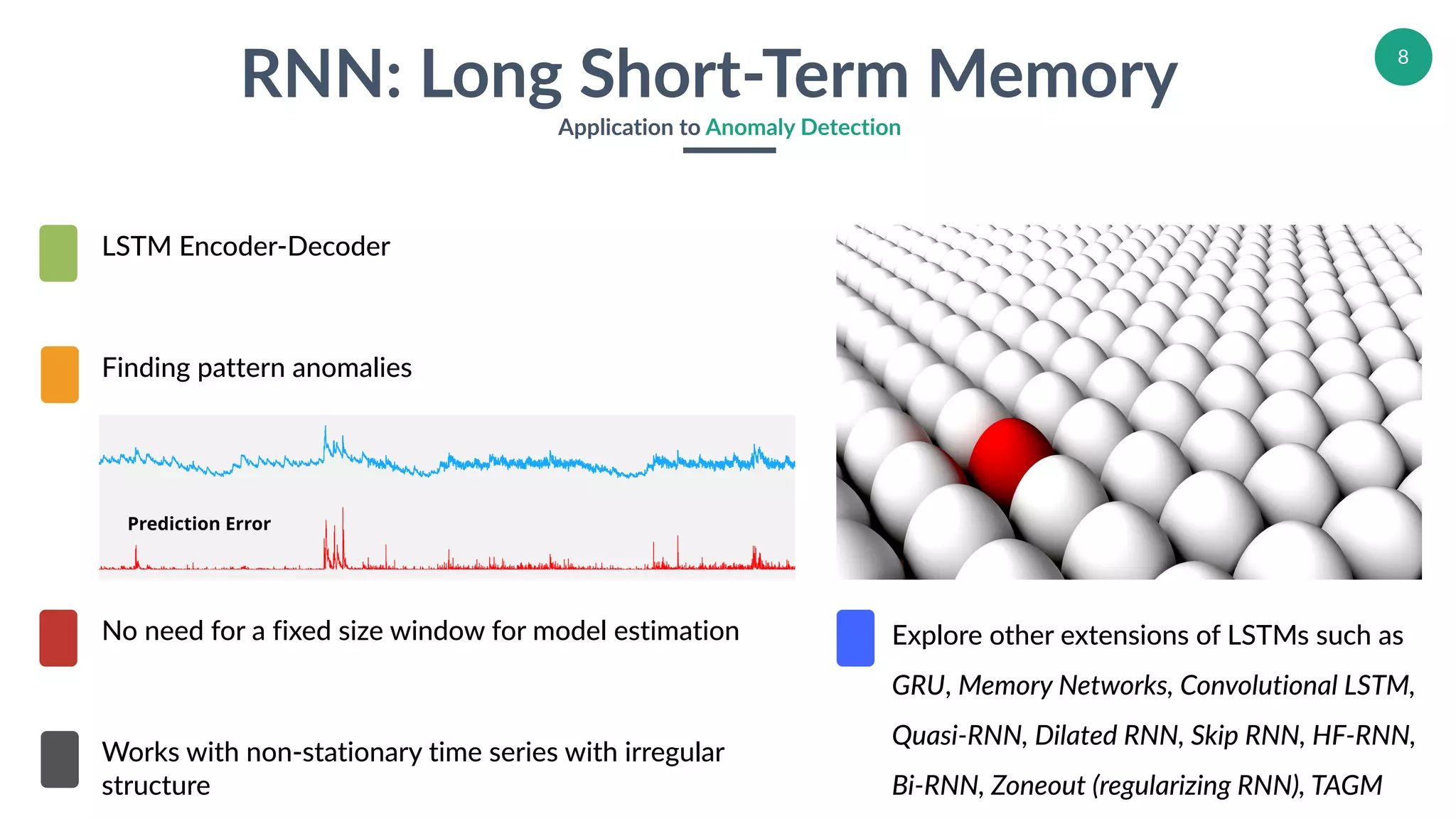
Application of LSTMs in anomaly detection within time series data, highlighting various extensions.
LSTM applications in forecasting for various domains including finance, translation, and NLP.
Introduction to temporal convolutional networks (TCN) and other alternatives for sequence modeling.
Challenges faced in handling large volumes of time series data including anomaly fatigue and analysis difficulties.
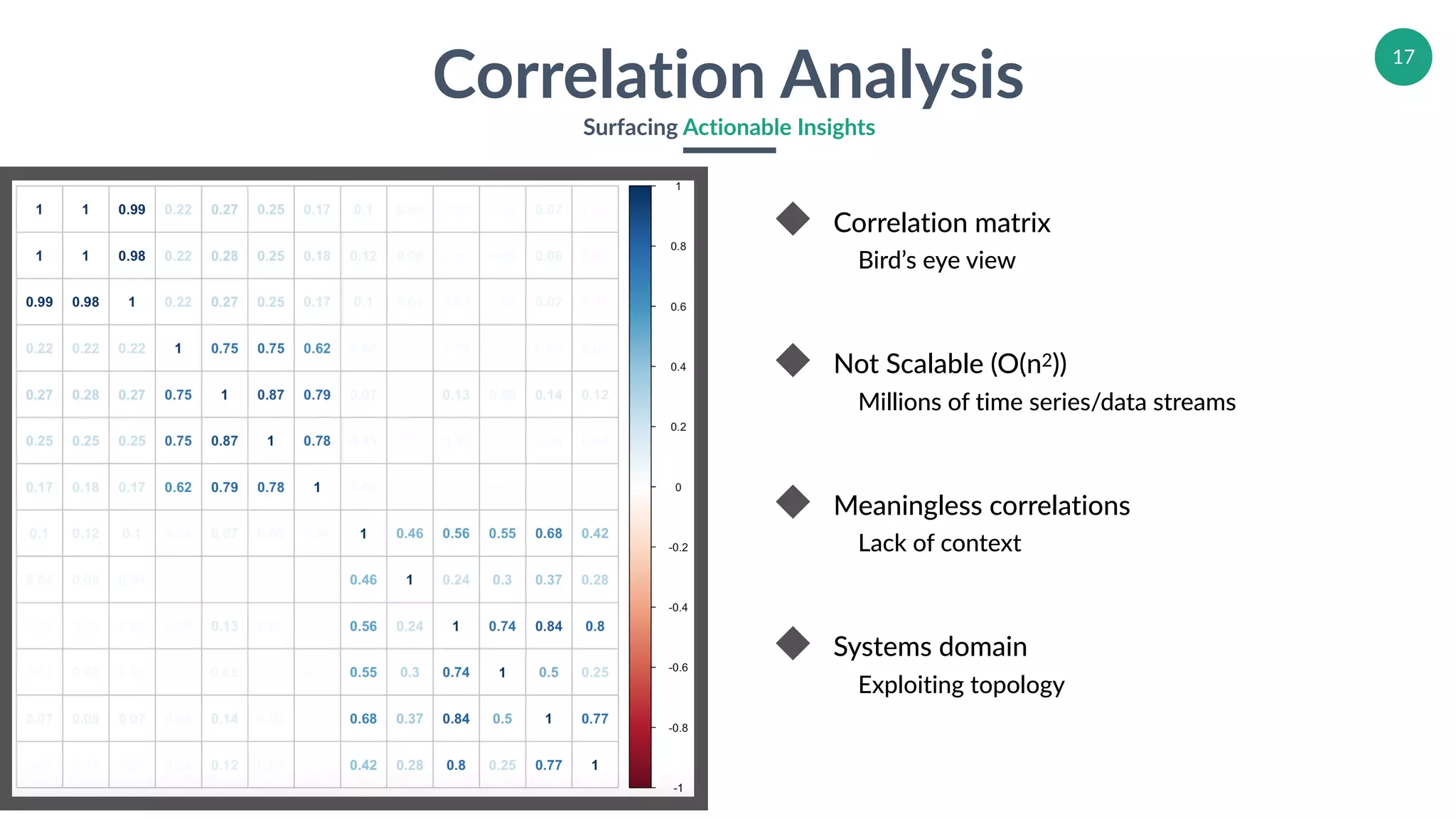
Explores dimensionality issues in multivariate time series analysis, including computational expenses.
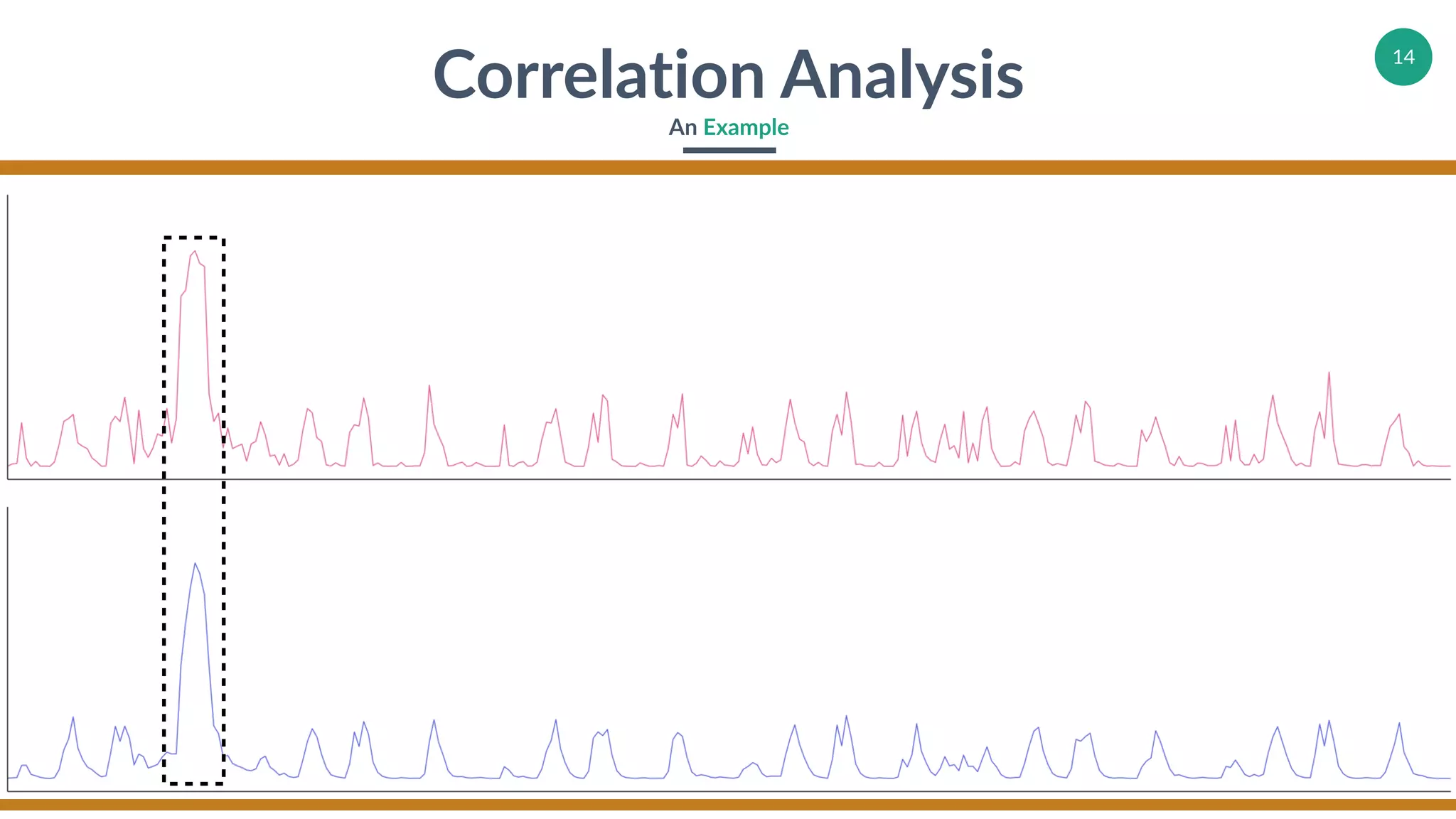
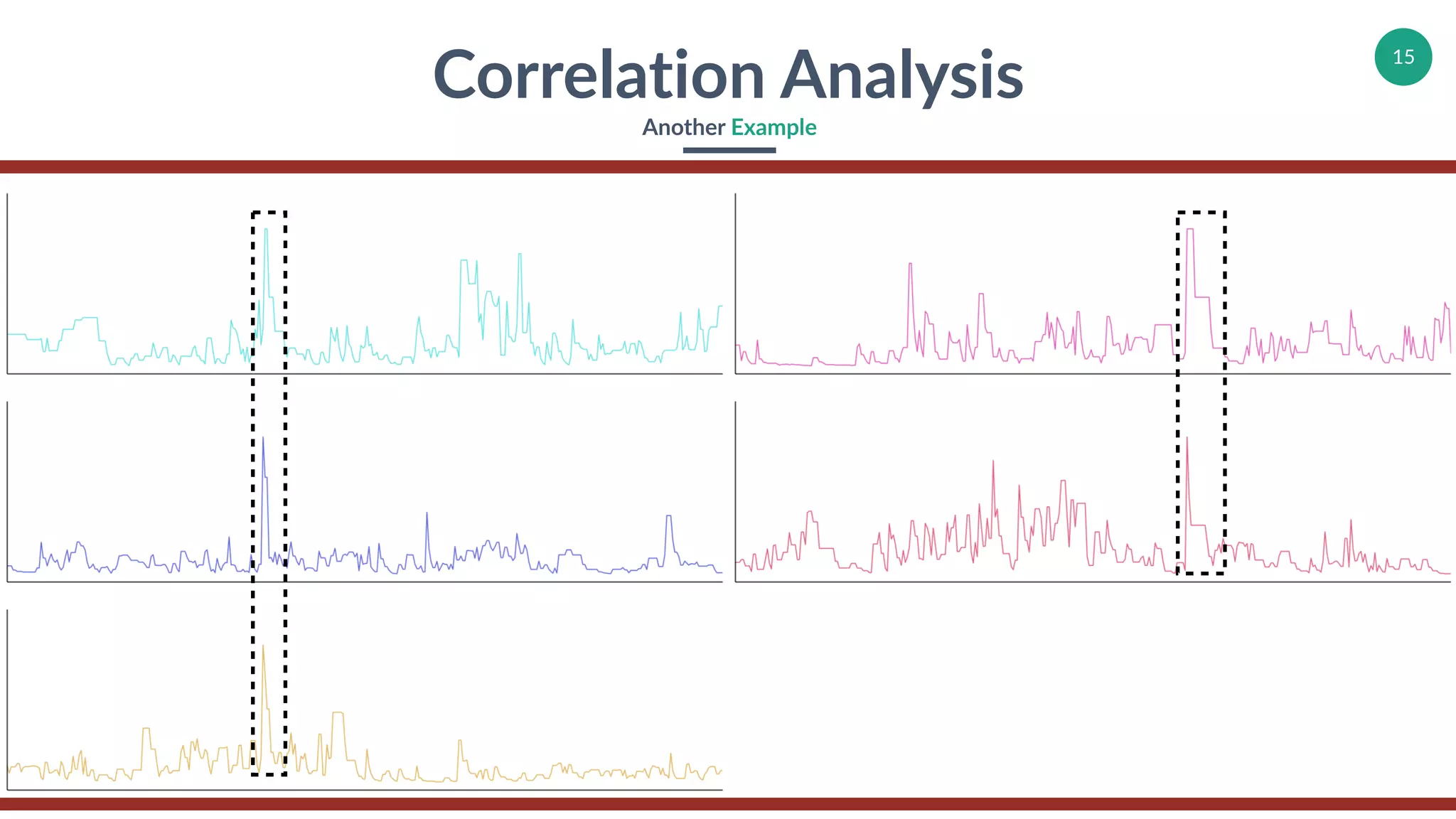
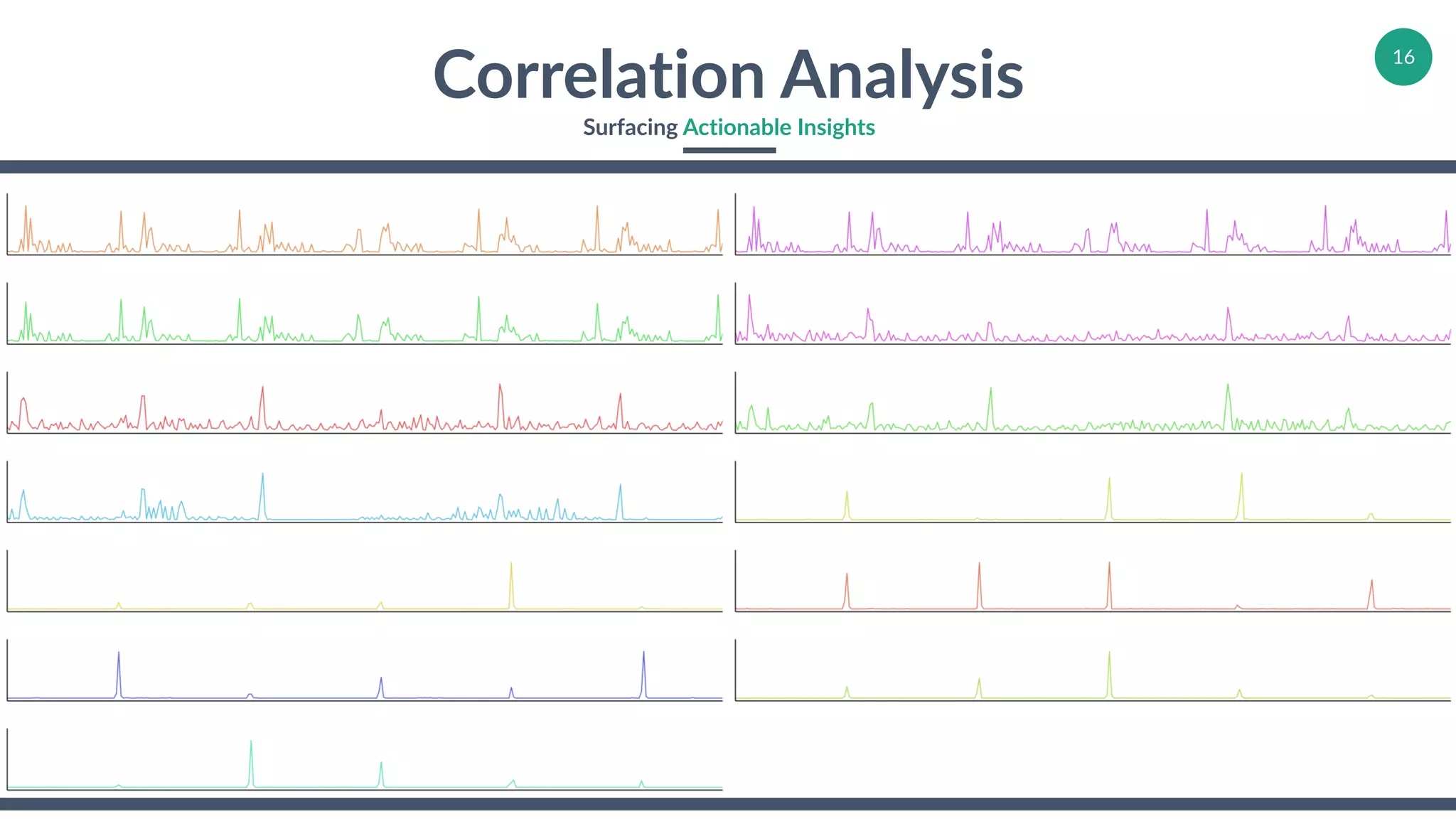
Demonstrations of correlation analysis with examples focusing on actionable insights.
Highlights limitations and scalability of correlation analysis within large datasets.
Overview of various correlation coefficients and their historical significance.
An in-depth analysis of Pearson correlation's strengths and weaknesses in context of time series.
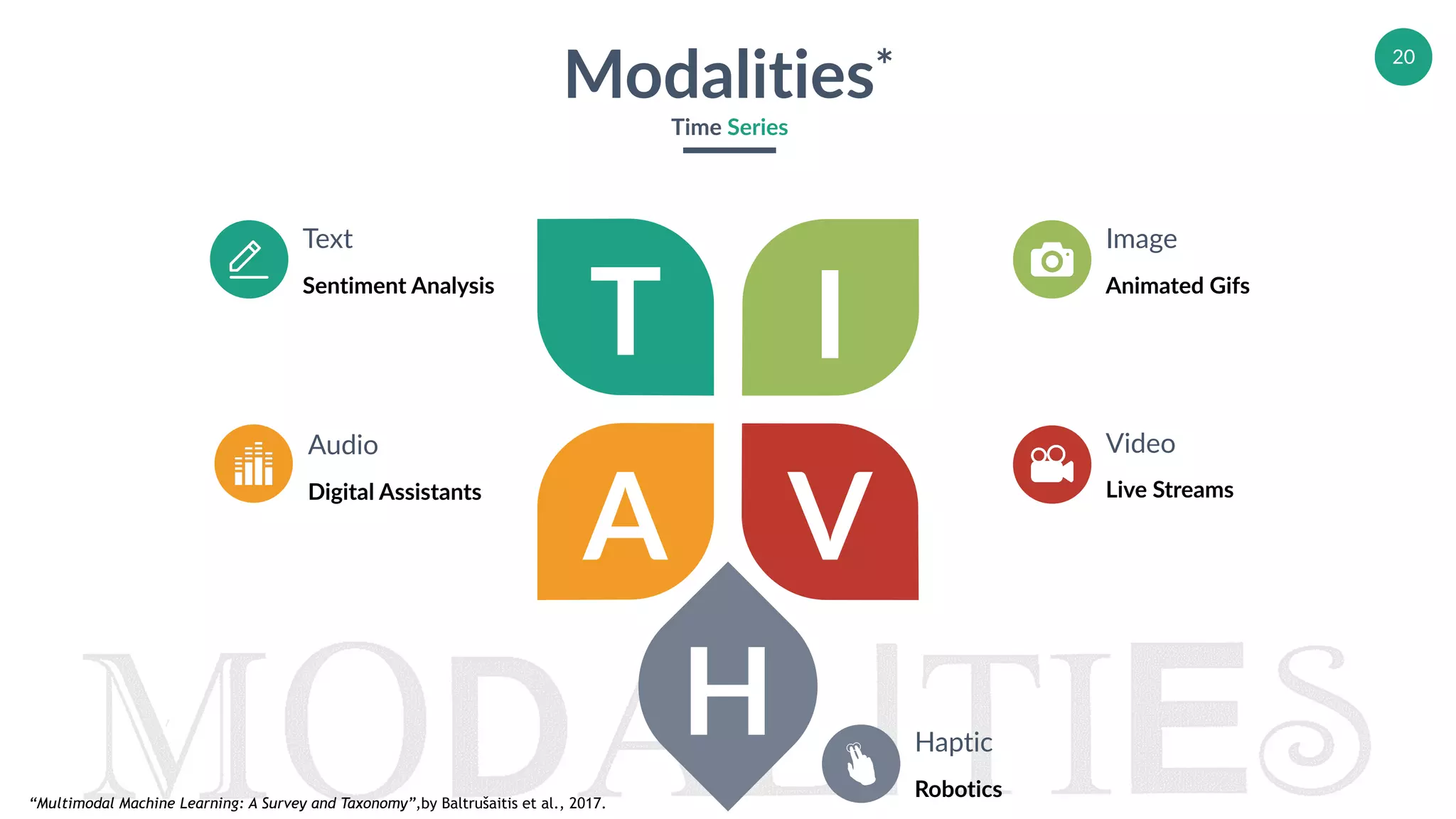
Introduction to various modalities used in machine learning including time series, text, and video.
Discussion of research opportunities in less commonly explored modalities like smell and taste.
Approaches for feature extraction in deep learning contexts focused on correlation.
Overview of different loss functions in machine learning highlighting their implications on model performance.
Detailed dive into correlation loss and its applications in deep learning contexts.
Explains canonical correlation analysis and its relevance in transfer learning.
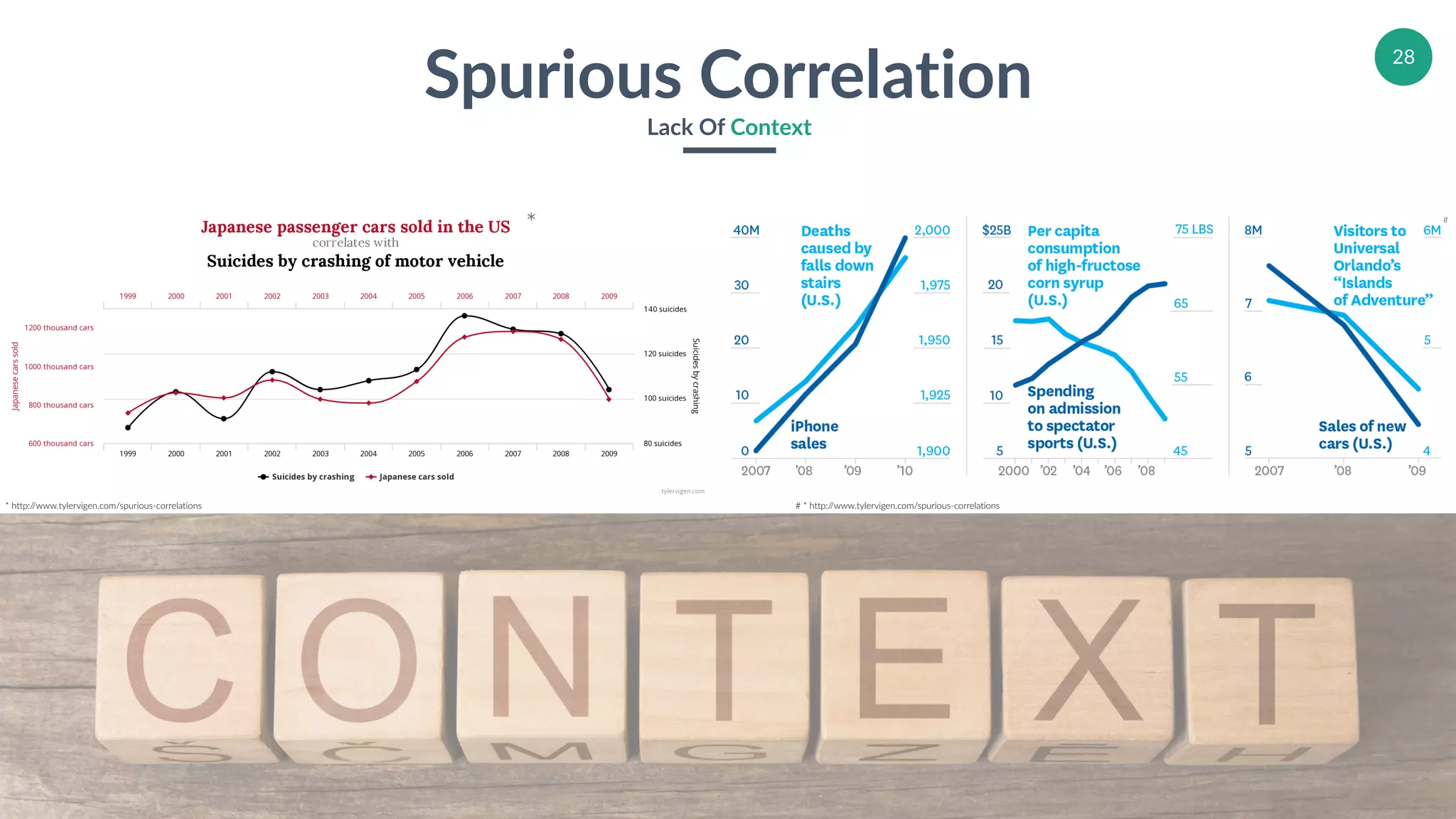
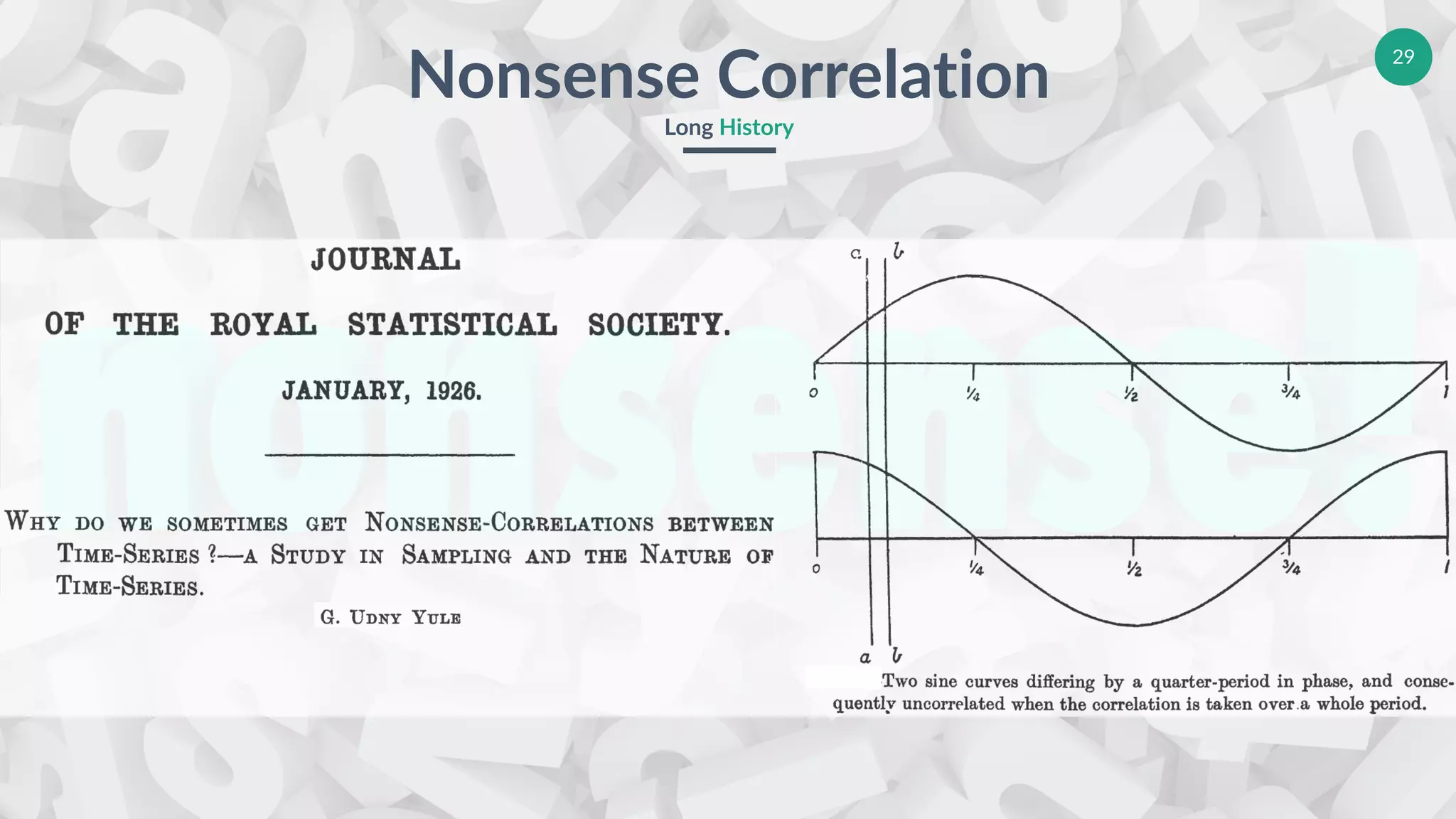
Discusses spurious correlations and their historical documentation in a statistical context.
Analysis of instances of nonsense correlation to provide context in statistical analysis.
Compilation of influential readings and resources detailing the history and developments in neural networks.























































































