Download as PDF, PPTX










![機械学習の分類
● 教師あり学習
● “事前に与えられたデータをいわば「例題(=先生から
の助言)」とみなして、それをガイドに学習(=デー
タへの何らかのフィッティング)を行う” [5]
● 例) SVM, ナイーブベイズ
● 教師なし学習
● “出力すべきものがあらかじめ決まっていないという点
で教師あり学習とは大きく異なる。 データの背後に存
在する本質的な構造を抽出するために用いられる” [6]
● 例) クラスタリング, 自己組織化マップ](https://image.slidesharecdn.com/mapreduce1010172-101017090123-phpapp01/85/Data-Intensive-Text-Processing-with-MapReduce-ch6-1-10-320.jpg)



![EMアルゴリズム
● "確率モデルのパラメータを最尤法に基づいて推定する手
法のひとつであり、 観測不可能な潜在変数に確率モデル
が依存する場合に用いられる" [7]
● Eステップ、Mステップの繰り返しで処理を行う
● Eステップ
● 与えられたパラメータを元に、尤度関数の期待値を算出
● Mステップ
● 期待値を最大化するパラメータを算出
● このセクションでは、このEMアルゴリズムについて解説
する(MapReduce一切なし)](https://image.slidesharecdn.com/mapreduce1010172-101017090123-phpapp01/85/Data-Intensive-Text-Processing-with-MapReduce-ch6-1-14-320.jpg)


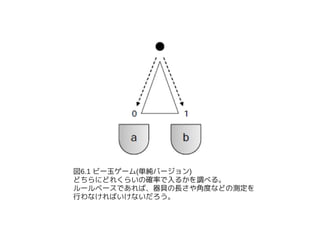




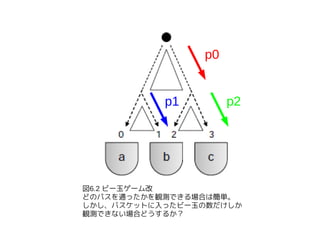














This document is written about "Data-Intensive Text Processing with MapReduce" Chapter 6.1. Chapter 6 describes how to design Expectation Maximization with MapReduce algorithm. Section 6.1 focus to Expectation Maximization algorithm itself, and so there are no description about MapReduce.


![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)




![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)




