Download to read offline







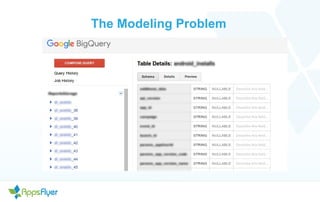

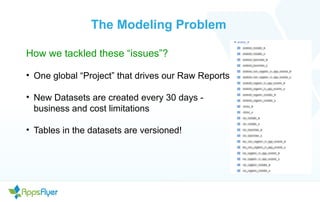
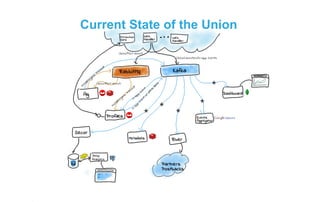






- The document discusses the past, present, and future of using BigQuery for mobile campaign analytics. In the past, they used small Python services and CouchDB which had performance issues. They started using BigQuery which improved performance but had some limitations and cost challenges. Through optimizations like unified schemas and table decorators, they addressed these issues. Going forward, they are waiting for custom partitioning functions in BigQuery to further improve performance and reduce costs.
















![[Codemash] Caching Made "Bootiful"!](https://cdn.slidesharecdn.com/ss_thumbnails/cachingmadebootifulcodemash11217-170112212321-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[Webinar] Getting Started with BigQuery: Basics, Its Appilcations & Use Cases](https://cdn.slidesharecdn.com/ss_thumbnails/webinargettingstartedwithbigquery-171116122740-thumbnail.jpg?width=640&height=640&fit=bounds)





























