Download as PDF, PPTX









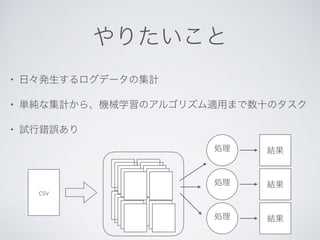











![Python + Spark
• Python serialize
• DataFrame API UDF
UDF Scala/Java
• http://www.slideshare.net/dragan10/performant-data-processing-with-pyspark-sparkr-
and-dataframe-api
Executor
JVM
DataFrame,
Cached
Python
lambda items:
items[0] == ‘abc’
transfer
DataFrame,
result
transfer
Driver](https://image.slidesharecdn.com/20161215python-pandas-spark-161221231309/85/20161215-python-pandas-spark-25-320.jpg)


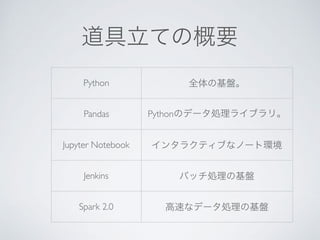
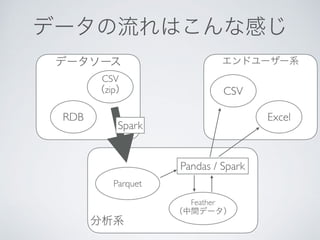
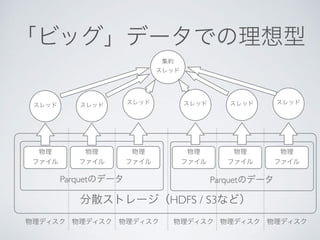
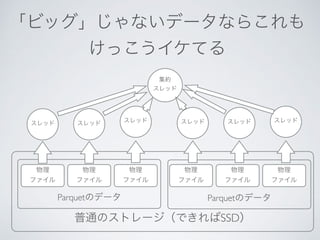
This document discusses using Python, Pandas, and Spark 2.0 for data analysis. It covers loading CSV and other data formats into Pandas and Spark DataFrames, using Parquet for efficient storage, and transferring data between Pandas and Spark for hybrid processing using CPUs and SSDs. The last part discusses new features in Spark 2.0 like SQL support on DataFrames and improved Python integration.






















































































