

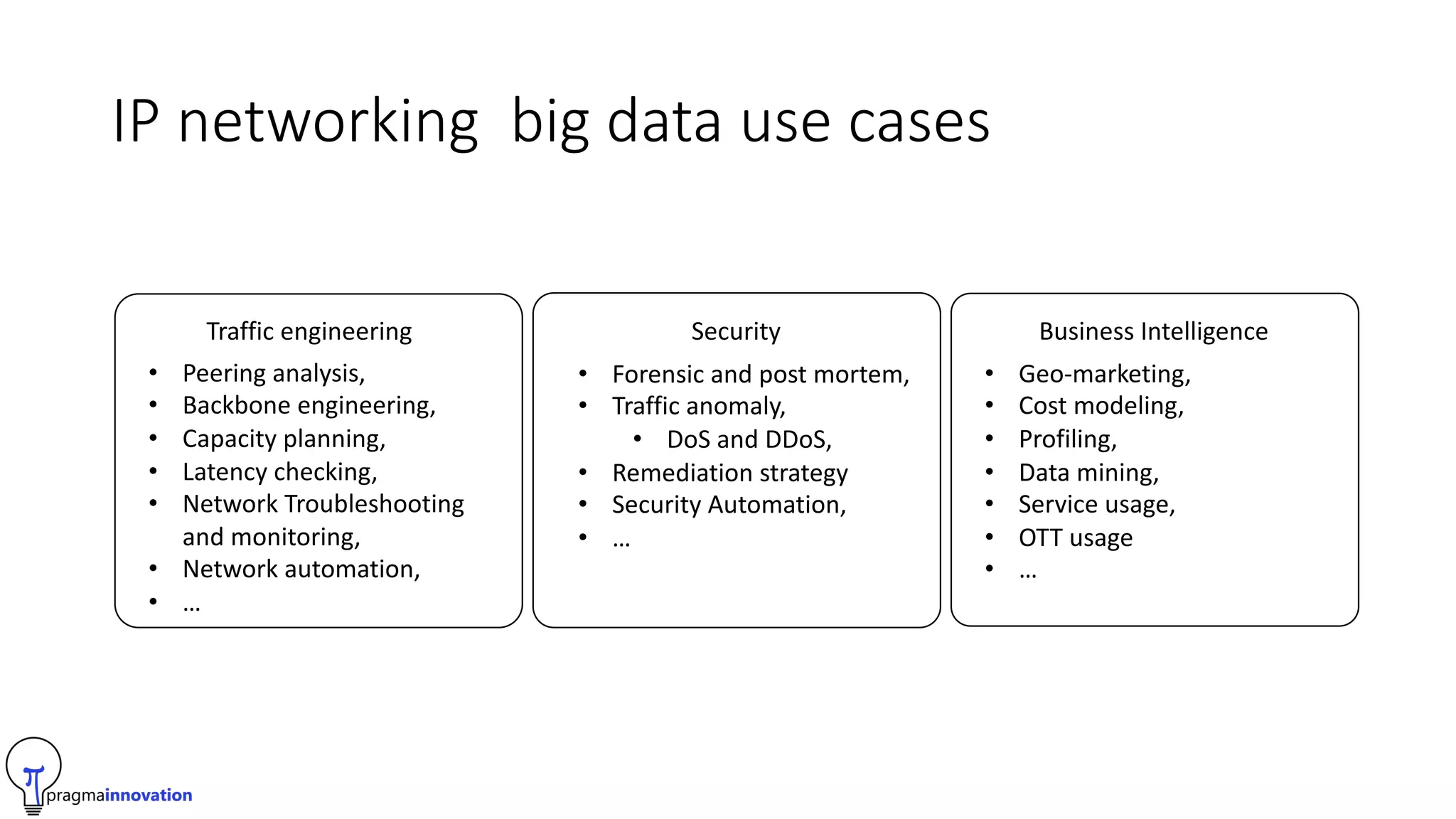

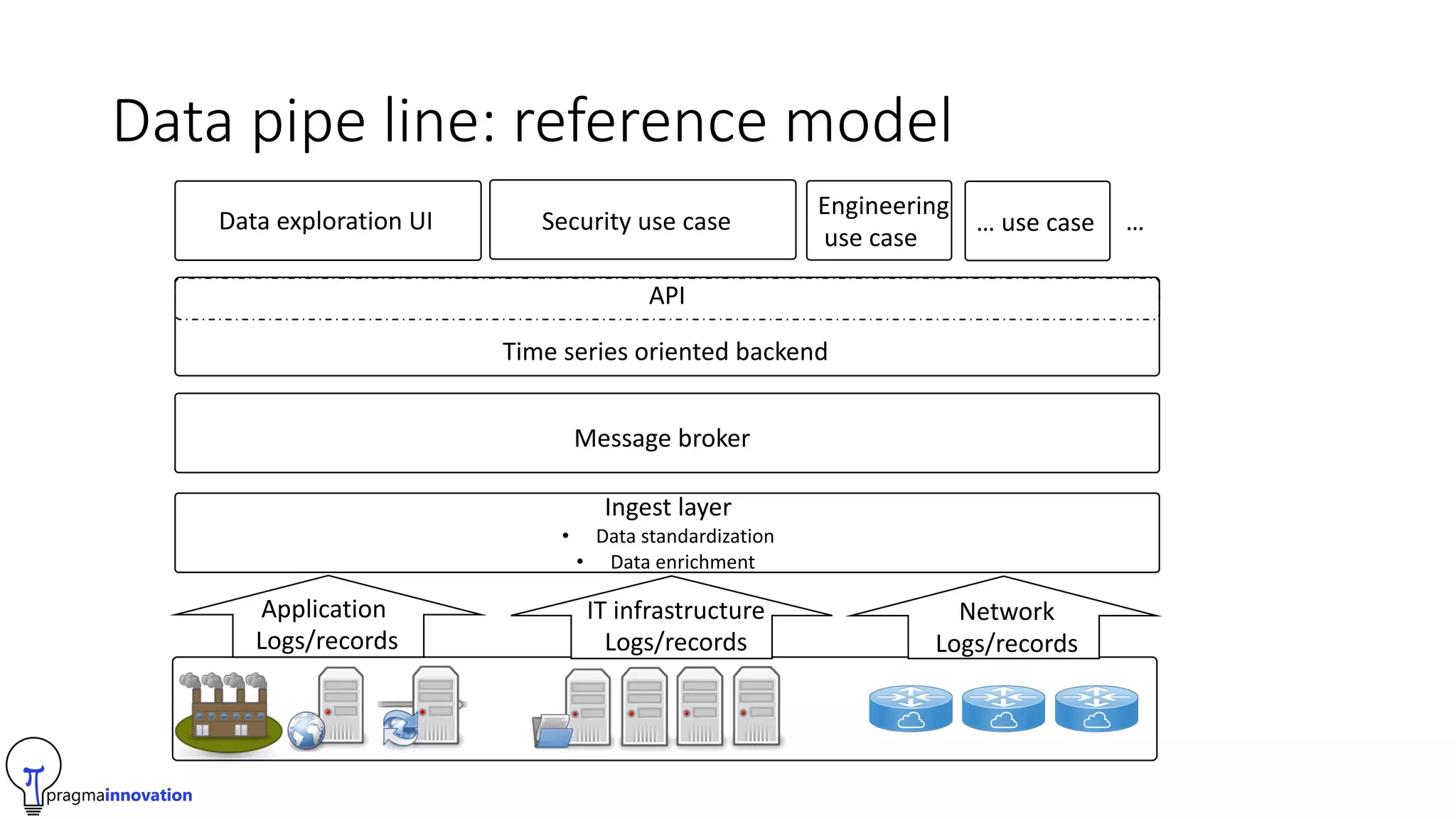








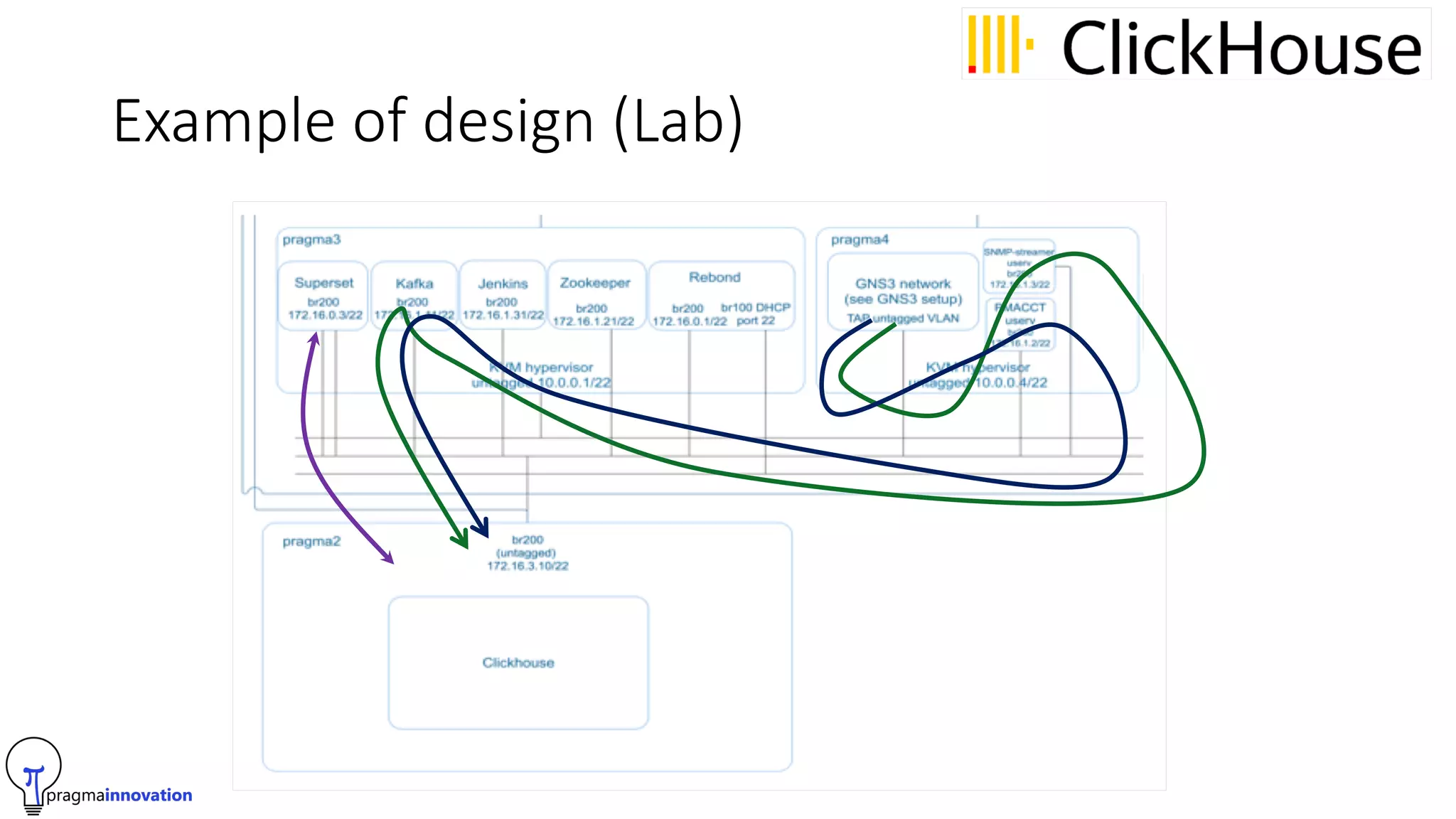






Pragma Innovation is an IT services company focused on time series data solutions. Their PASS (Pragma Analytics Software Suite) allows companies to analyze, report on, and make decisions from time series network data using open source software. It is designed for ISPs, hosting providers, and telecom companies. The solution ingests network and log data, standardizes it, enriches it using tools like GeoIP, and stores it in a time series database. This allows customers to build applications for traffic engineering, security, and business intelligence use cases. Key challenges addressed in version 2.0 of the solution include data sampling, IPv4/IPv6 support, and using ClickHouse as the time series database for its performance and simplicity

































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




