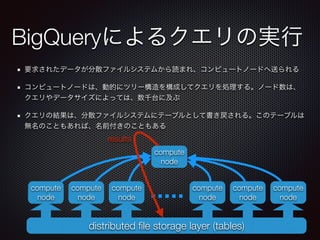
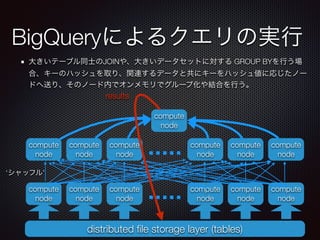
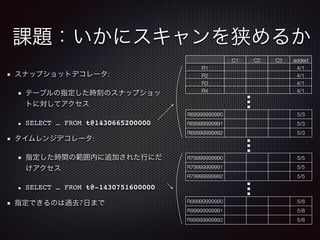
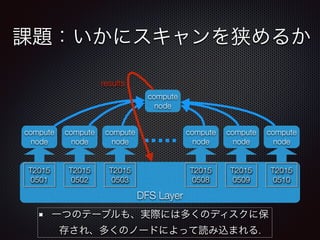
課金の対象
ストレージ - $0.020per GB / month
クエリ - $5 per TB processed (scanned)
ストリーミングインサート - $0.01 per 100,000 rows
until July 20, 2015. After July 20, 2015, $0.01 per 200
MB, with individual rows calculated using a 1 KB
minimum size.
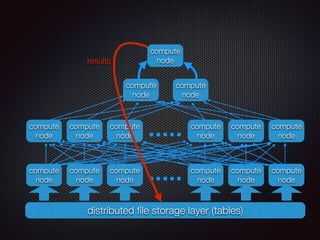
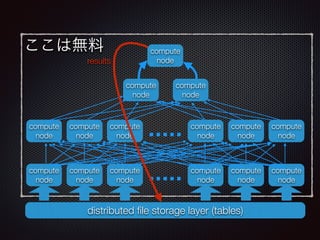
注目すべきはストレージ
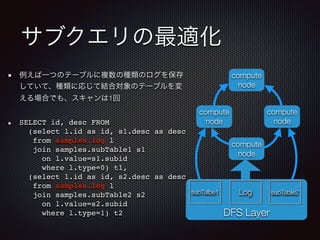
サブクエリの最適化
例えば一つのテーブルに複数の種類のログを保存
していて、種類に応じて結合対象のテーブルを変
える場合でも、スキャンは1回
SELECT id, descFROM
(select l.id as id, s1.desc as desc
from samples.log l
join samples.subTable1 s1
on l.value=s1.subid
where l.type=0) t1,
(select l.id as id, s2.desc as desc
from samples.log l
join samples.subTable2 s2
on l.value=s2.subid
where l.type=1) t2 DFS Layer
compute
node
compute
node
compute
node
subTalbe1 Log subTable2
compute
node



































![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[Cloud OnAir] BigQuery の一般公開データセットを 利用した実践的データ分析 2019年3月28日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0328-190328095050-thumbnail.jpg?width=640&height=640&fit=bounds)

























