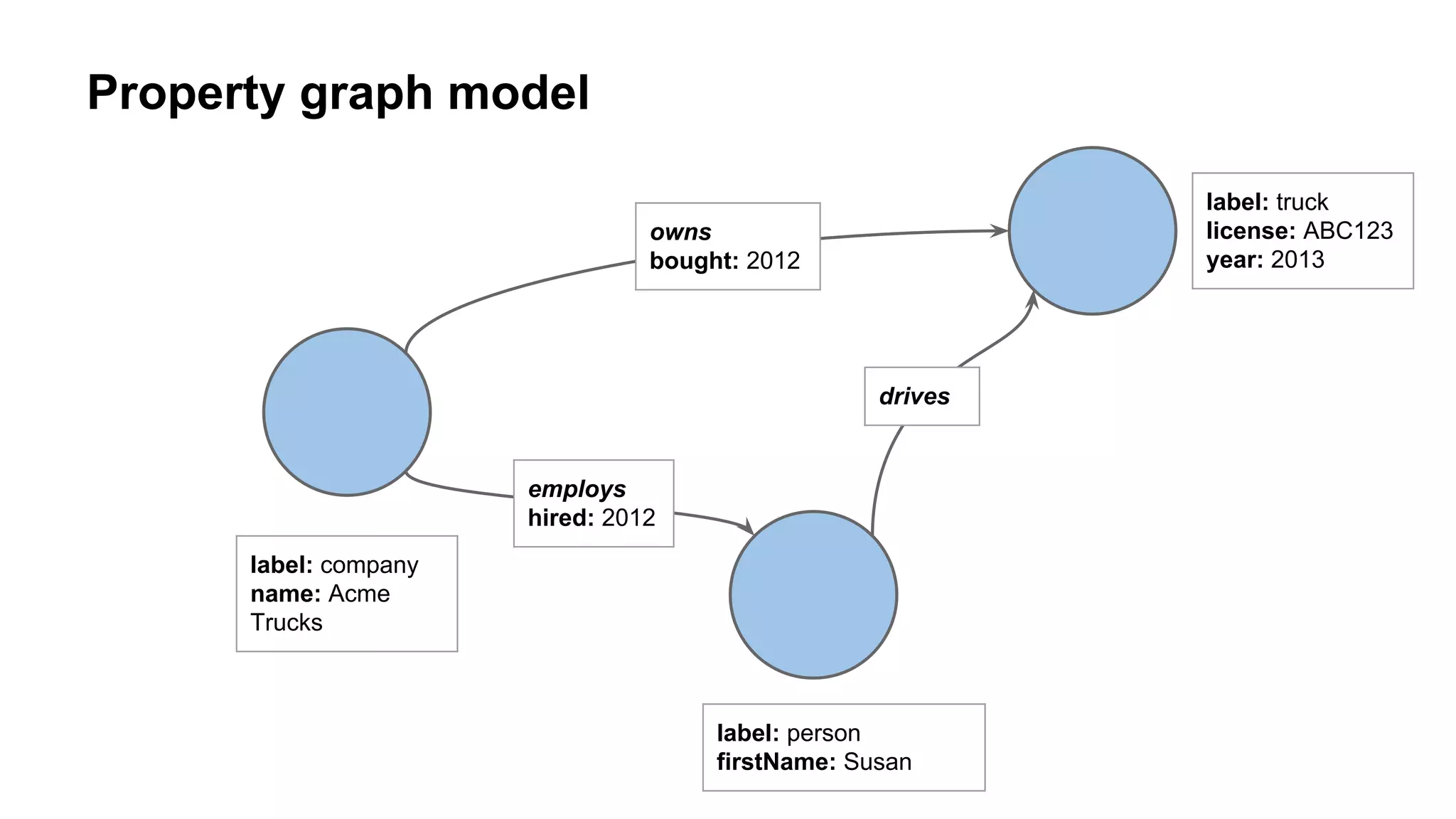
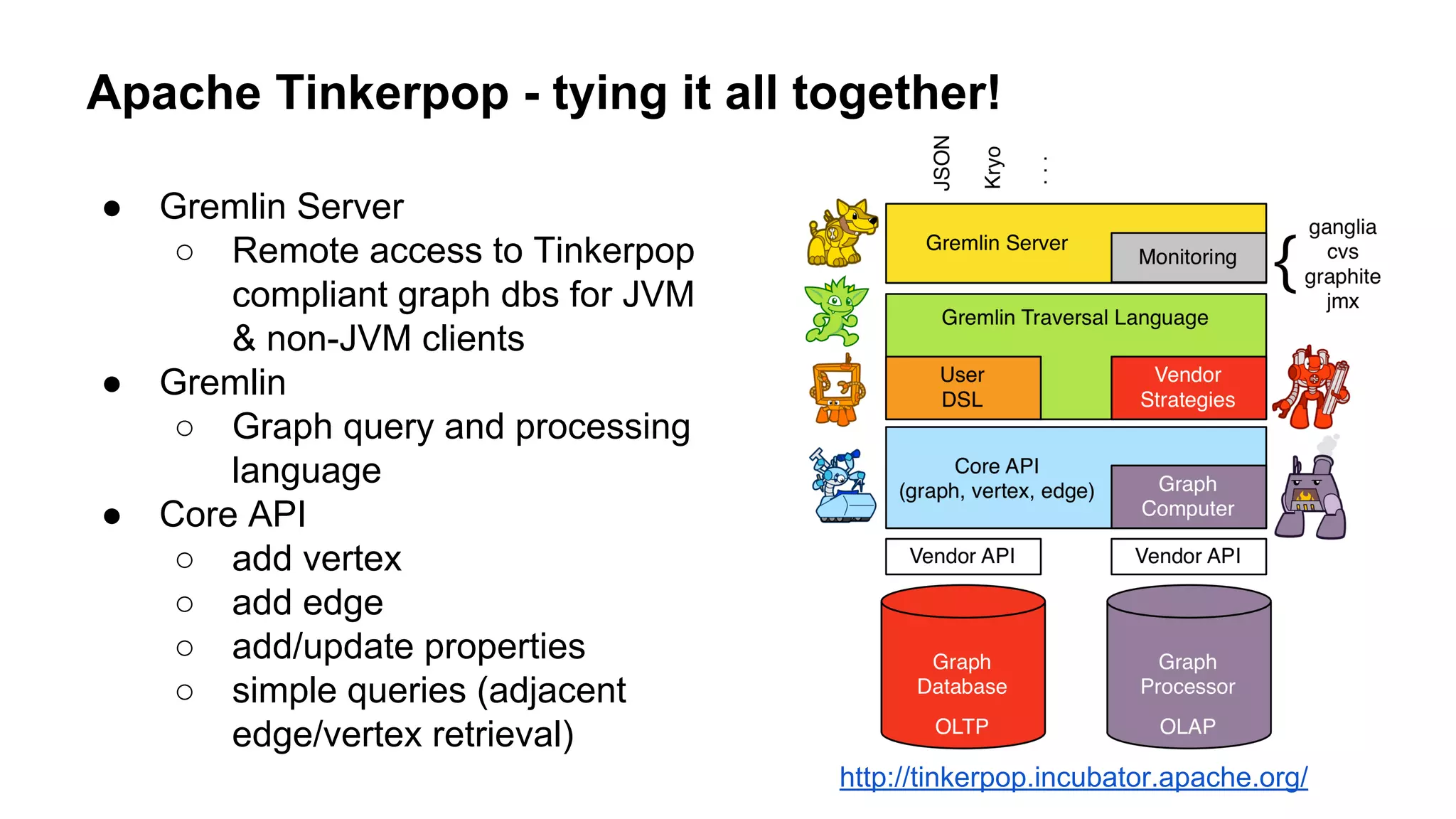
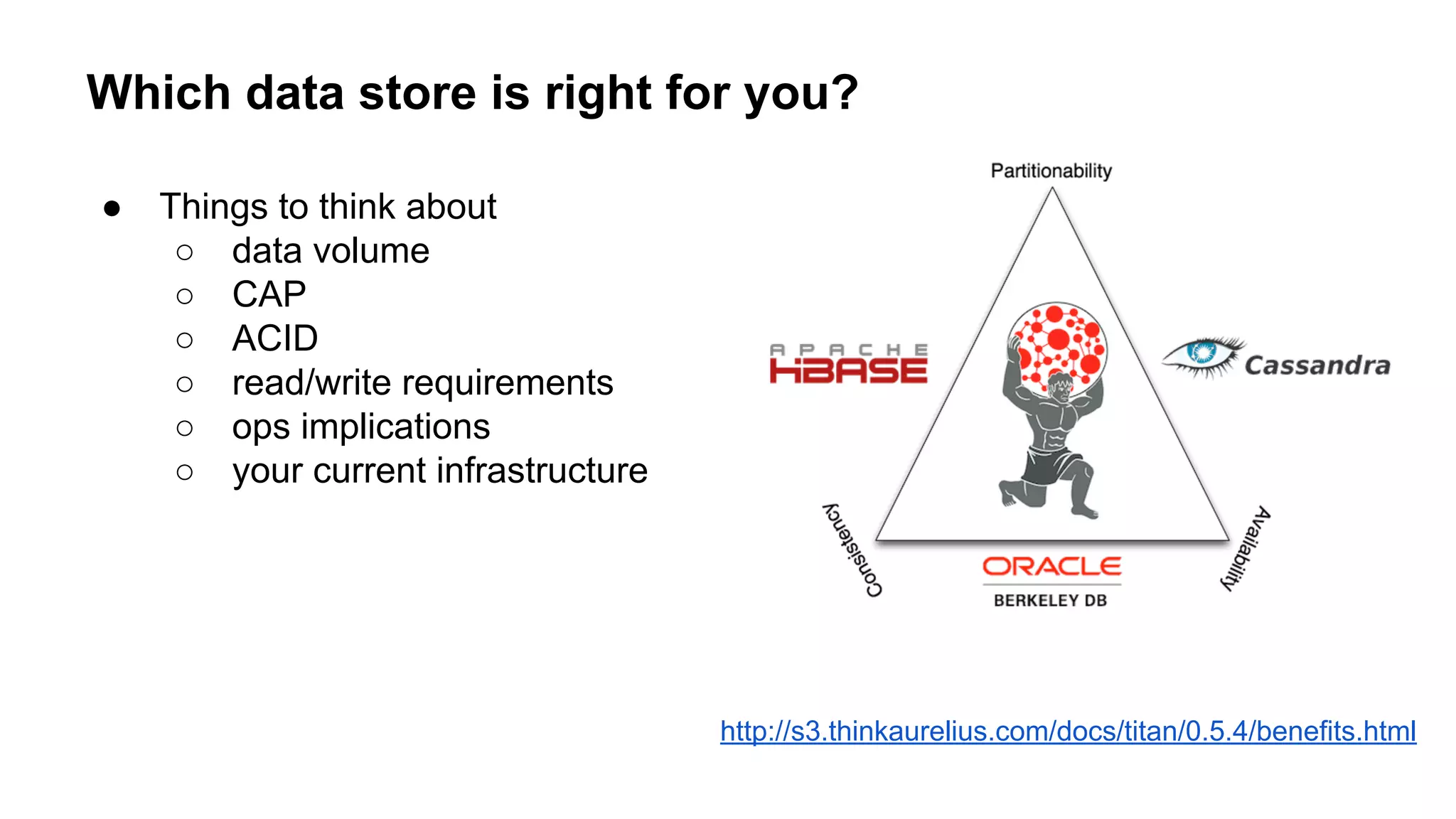
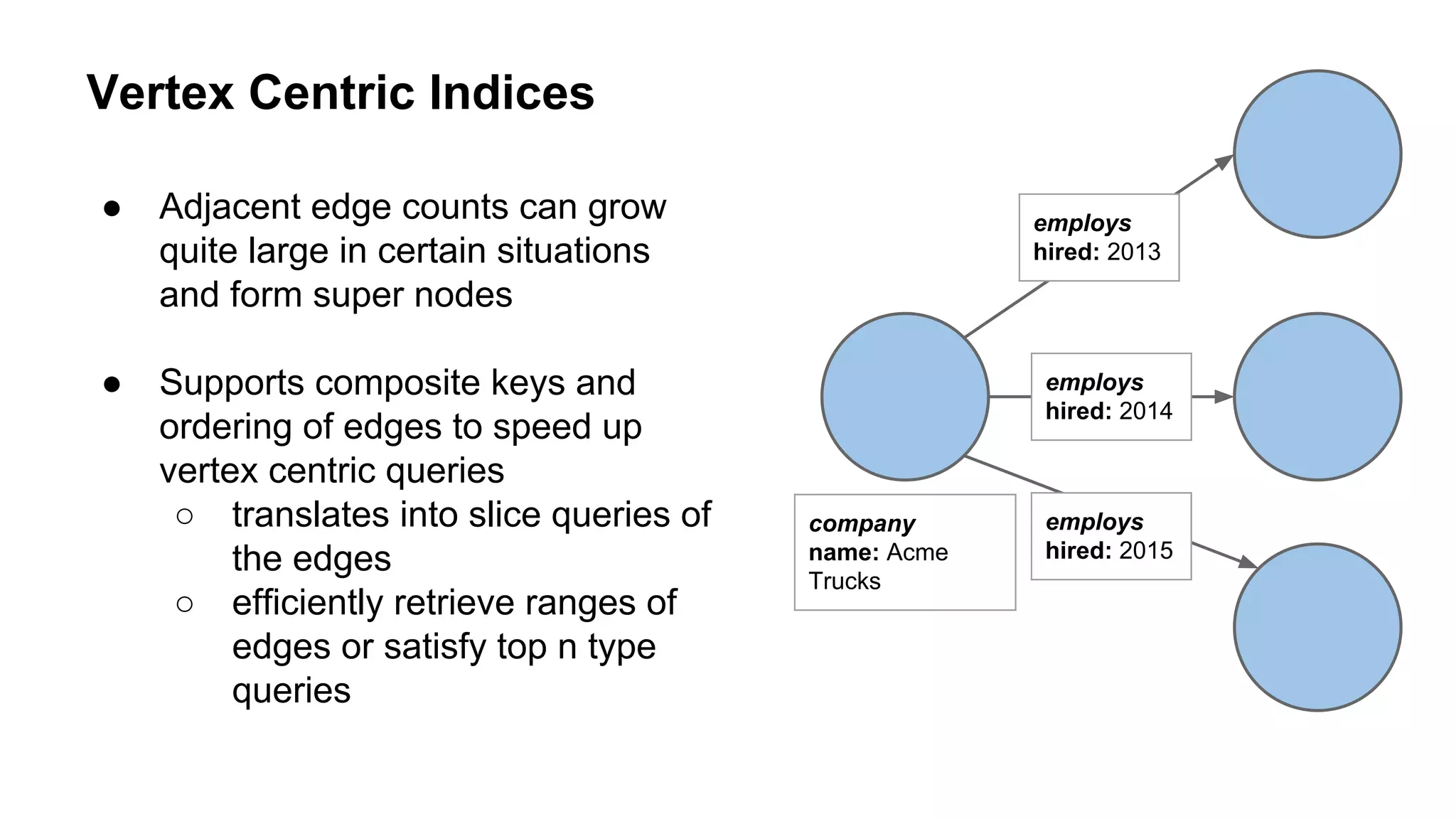
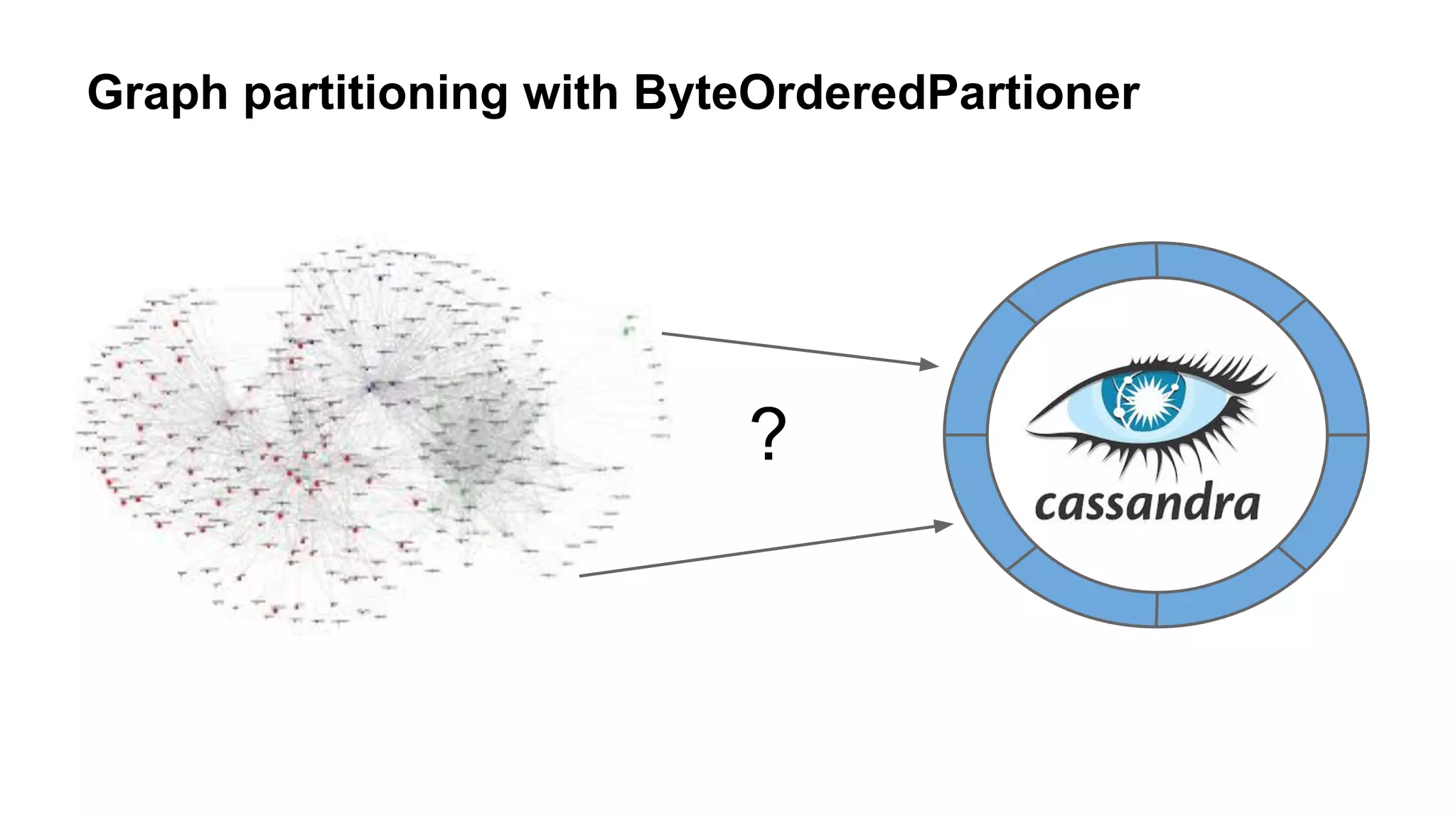
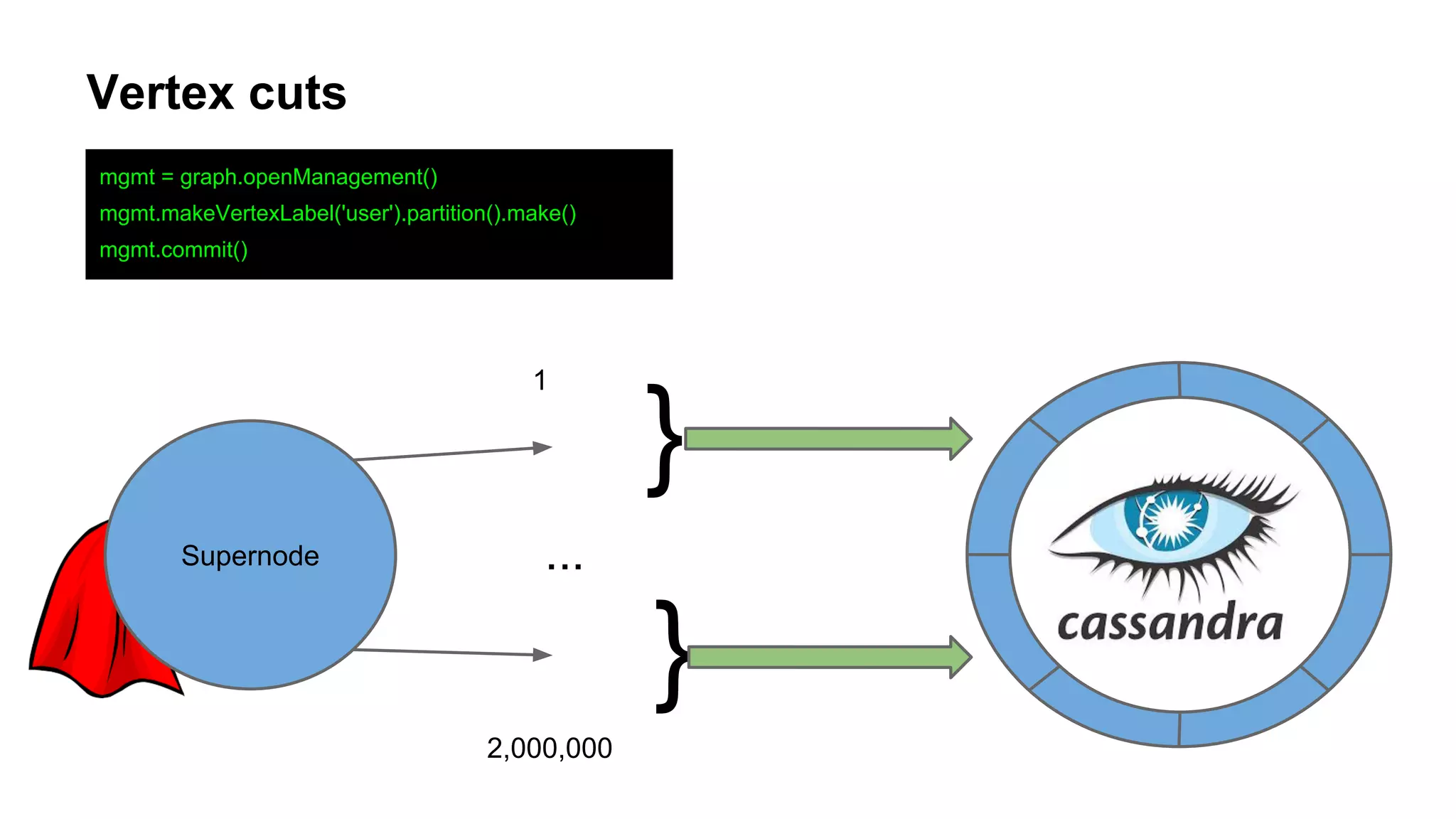
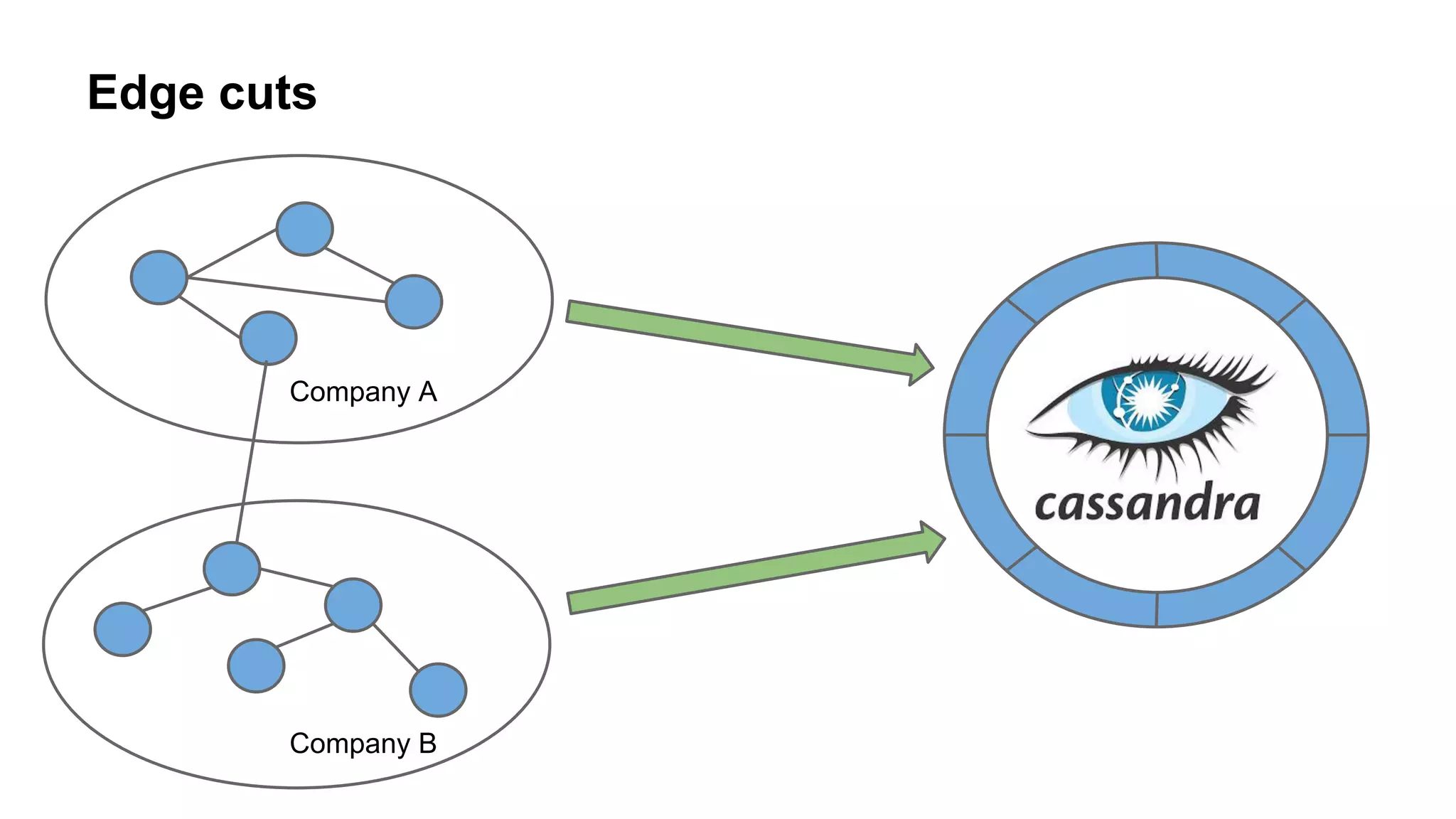
The document provides an overview of using the Titan graph database with Cassandra, detailing its property graph model and how to implement graph projects utilizing Apache TinkerPop. It highlights key graph operations, including adding vertices and edges, querying, and graph processing functionalities, along with insights on Titan's deployment and integration challenges within real-world applications. Additionally, it touches on the use cases for graph databases, Titan-specific features, and available resources for further learning.



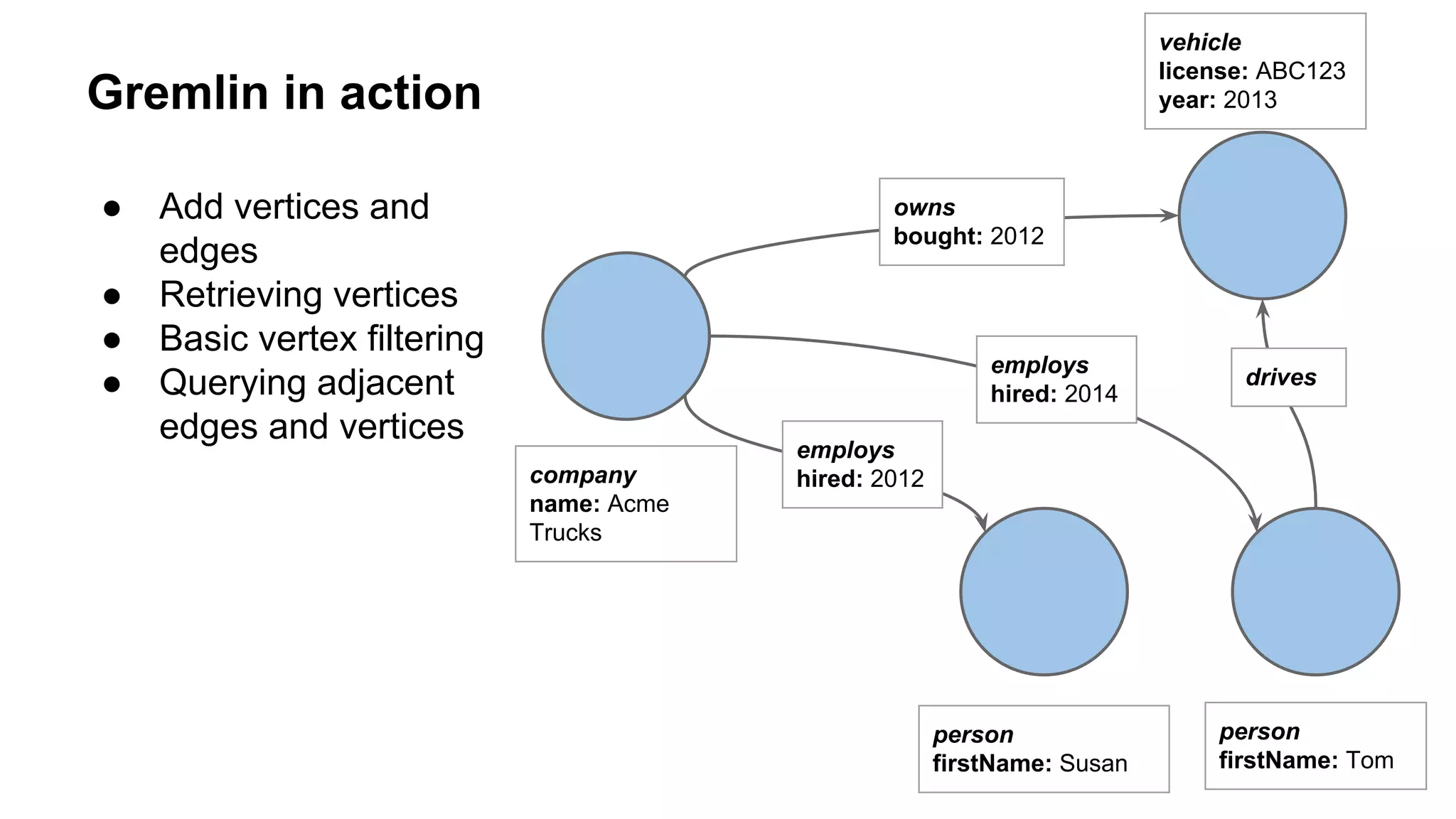

![Retrieving vertices
// Get a traverser so that we can run some queries
g = graph.traversal(standard())
gremlin> g.V()
==>v[0]
==>v[2]
==>v[4]
==>v[6]
// Get the properties for each vertex
gremlin> g.V().valueMap()
==>[name:[Acme Trucks]]
==>[firstName:[Susan]]
==>[firstName:[Tom]]
==>[license:[ABC123], year:[2012]]](https://image.slidesharecdn.com/titanatwellawareandgeneralgraphoverview-150620140919-lva1-app6891/75/Titan-and-Cassandra-at-WellAware-8-2048.jpg)
![Basic vertex filtering
// Retrieve all people with firstName Susan
gremlin> g.V().hasLabel("person").has("firstName", "Susan")
==>v[2]
// Retrieve all people with firstName Susan or Tom
gremlin> g.V().hasLabel("person").has("firstName", within("Susan", "Tom"))
==>v[2]
==>v[4]](https://image.slidesharecdn.com/titanatwellawareandgeneralgraphoverview-150620140919-lva1-app6891/75/Titan-and-Cassandra-at-WellAware-9-2048.jpg)











































































![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
