Download as PDF, PPTX








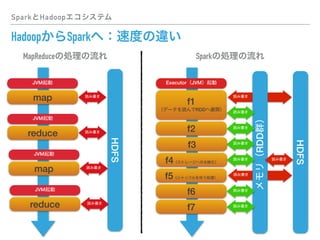


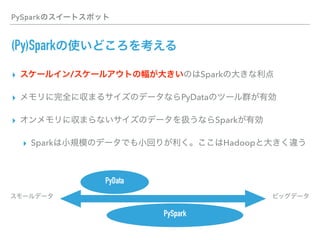




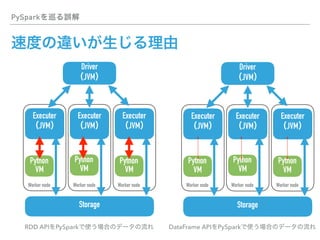




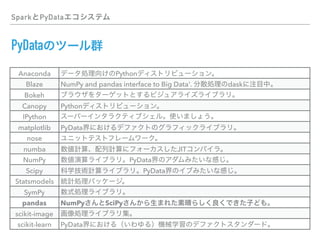

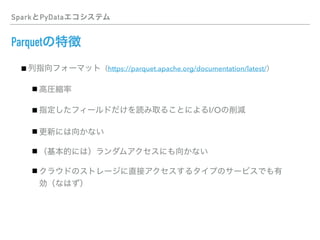

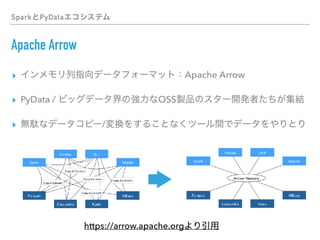

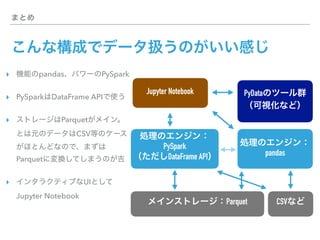


This document discusses PySpark and how it relates to Spark, Hadoop, and Python for data analysis (PyData). PySpark allows users to write Spark programs using Python APIs, access Spark functionality from Python, and interface between Spark and PyData tools like pandas. It also covers Spark file formats like Parquet that can improve performance when used with PySpark and PyData tools.






















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)








