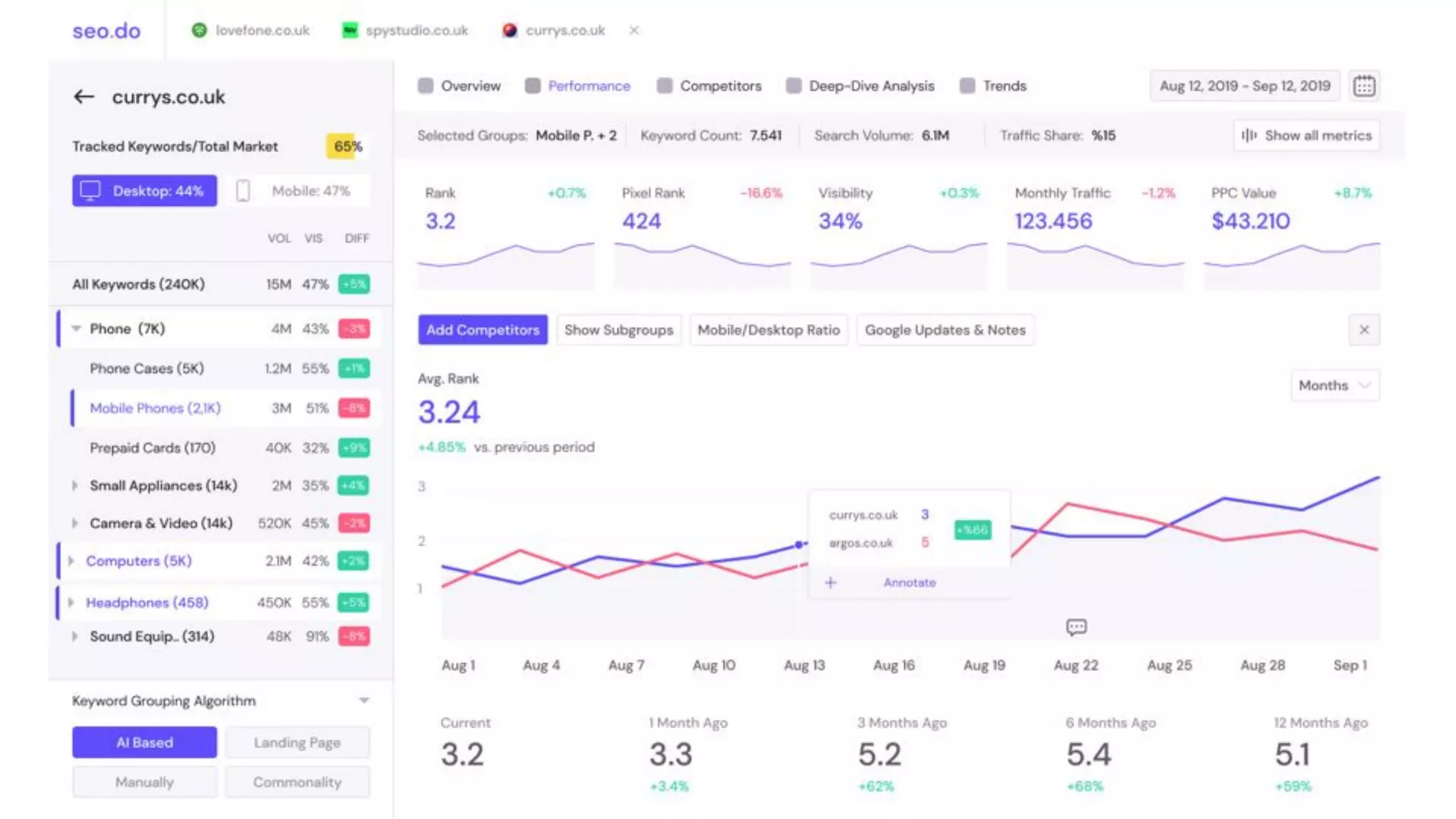
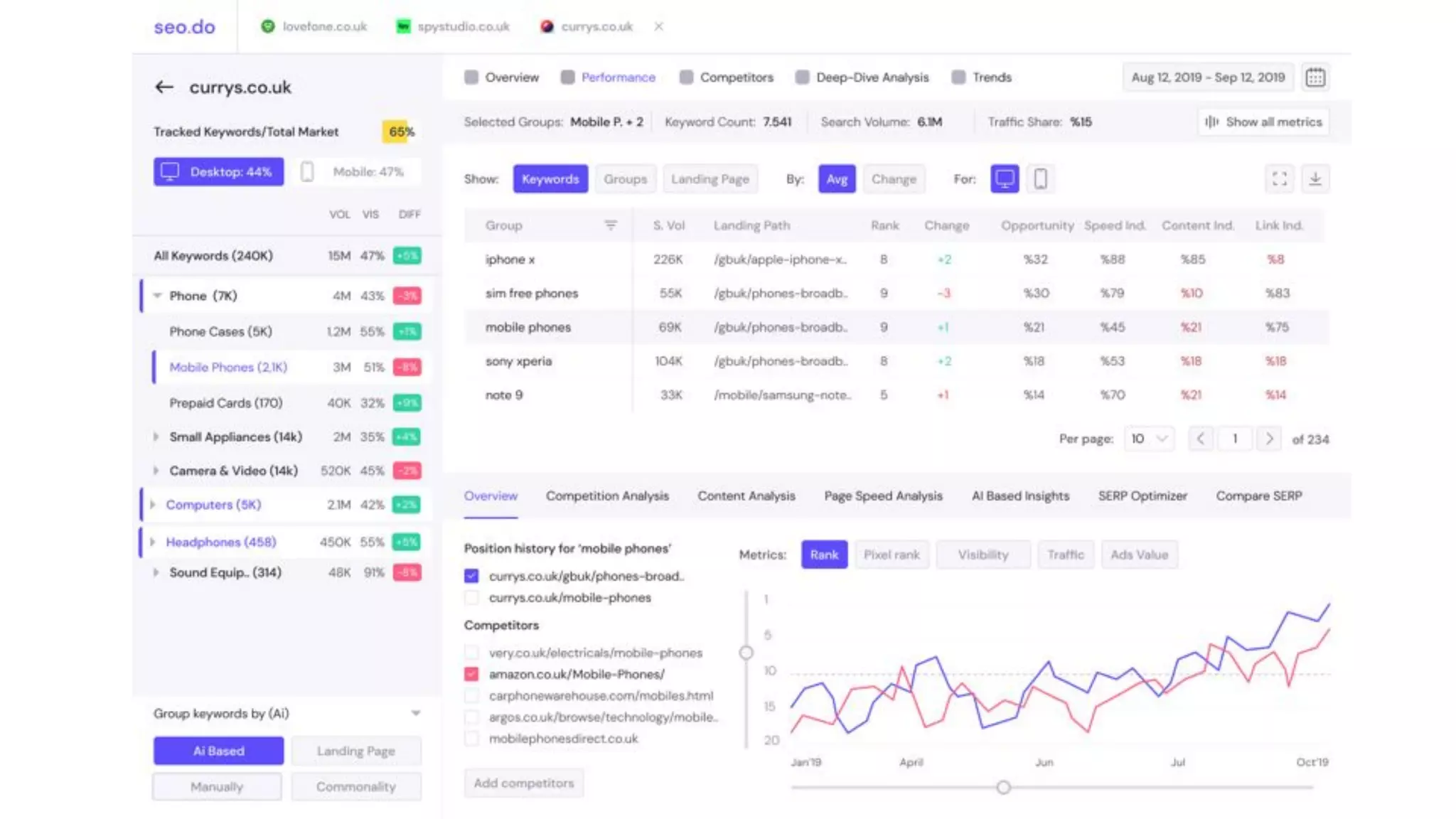
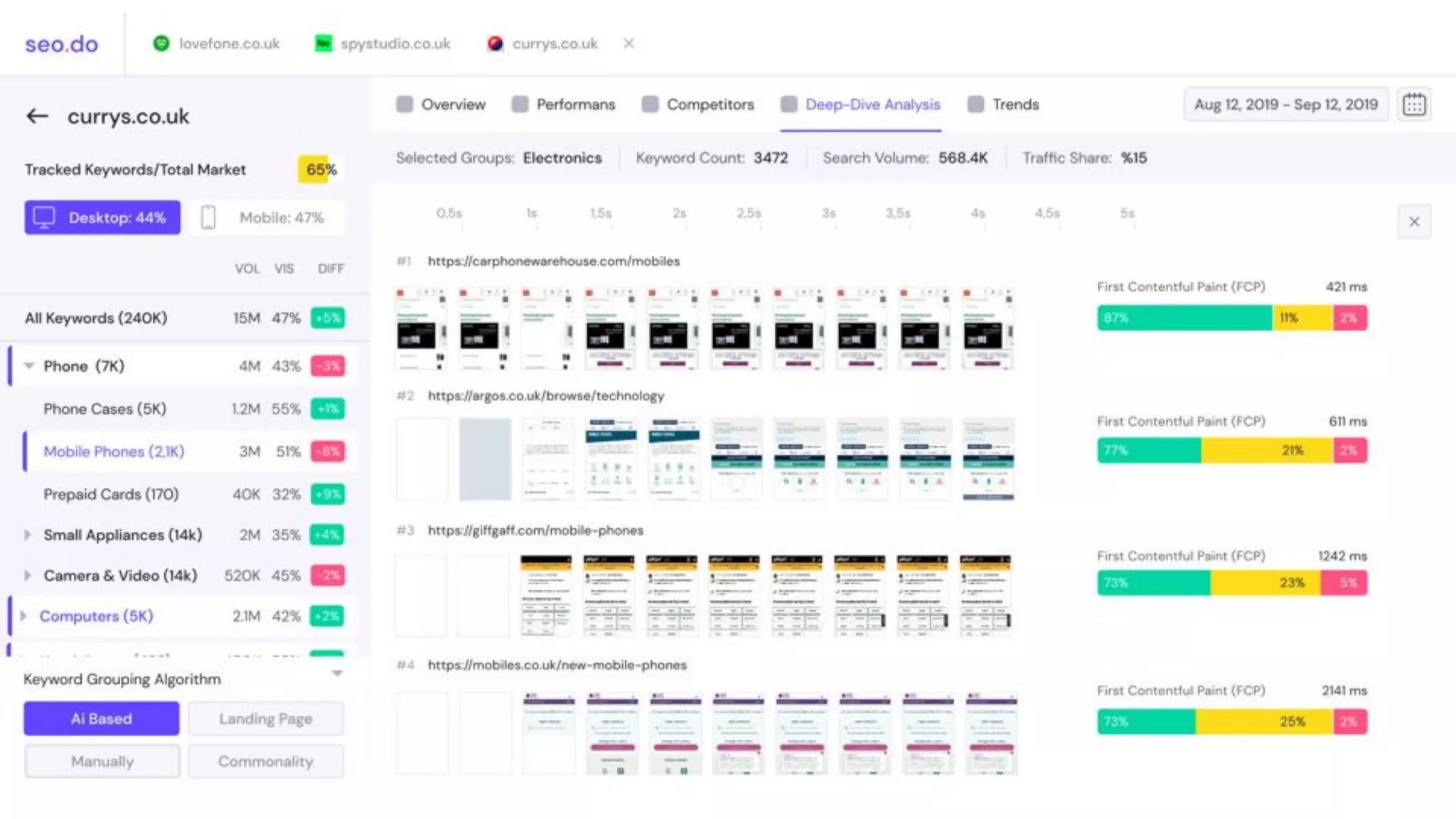
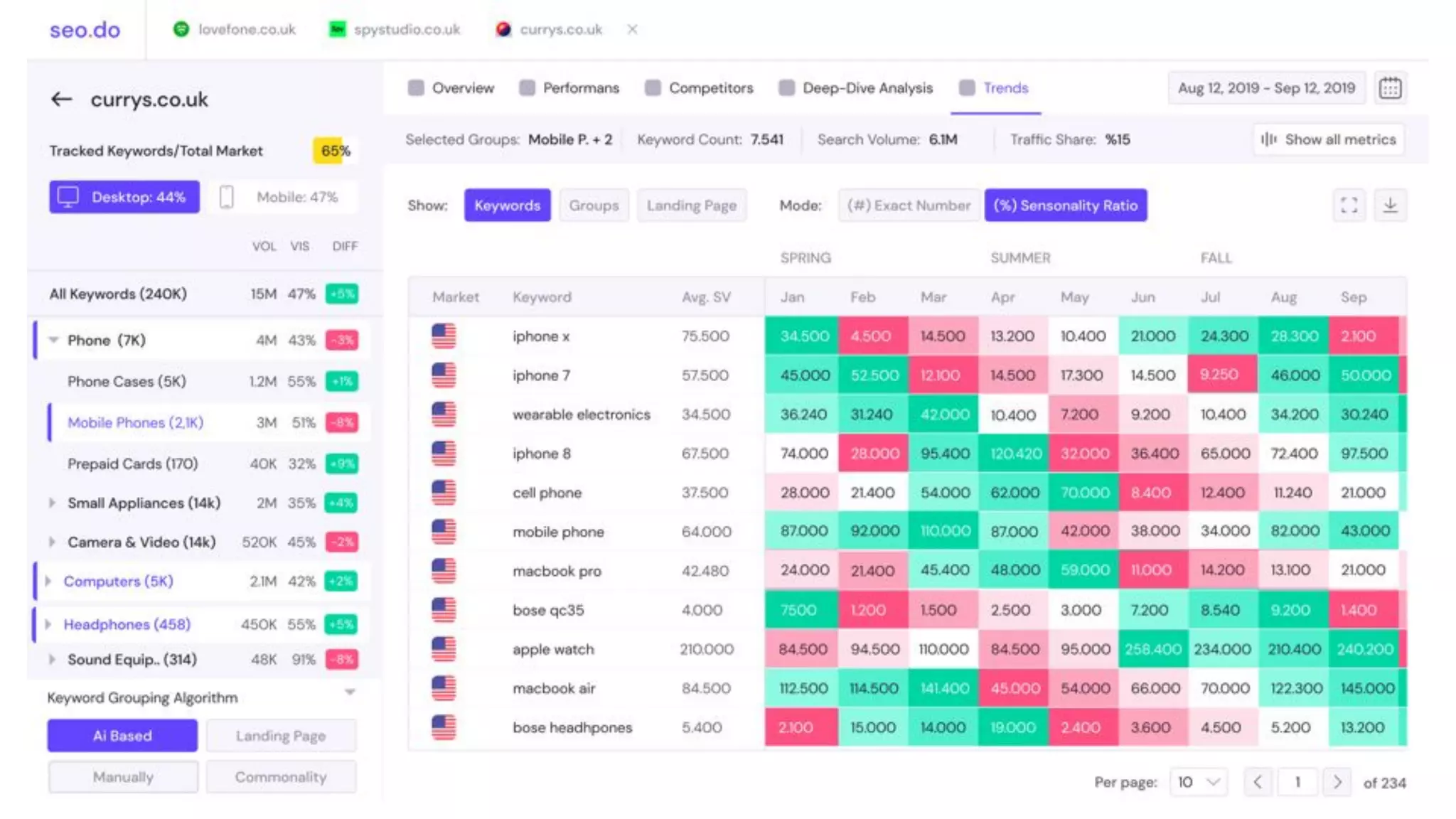
The document details the implementation of ClickHouse at SEO.do, focusing on its use case for handling and processing large amounts of time series data without the need for updates or deletes. It explores schema design, query optimization, and performance testing, highlighting the advantages of ClickHouse's built-in functions and high compression rates. The document also discusses the creation of a cluster for high availability and load balancing, along with testing API frameworks for handling queries efficiently.


























































![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)






































