Download as PDF, PPTX

![Today s Session
Ulrich Rueckert Michael Zeller
Data Scientist CEO
Datameer Zementis
After this session, you will be able to…
1. Effectively deliver predictive solutions combining:
a. R, KNIME & Others [Model Development]
b. Zementis Universal PMML Plug-in [Model Deployment & Execution]
c. Datameer [Scalable Hadoop Infrastructure]
2. Identify PMML as a vendor-neutral & open standard to:
a. Incorporate predictive models from virtually any commercial vendor or open source tool
b. Apply such models on Big Data
3. Leverage a lightweight, agile deployment process for predictive analytics to:
a. Accelerate time-to-market
b. Lower cost and complexity
c. Reuse existing predictive assets
© 2012 Datameer, Inc. All rights reserved. Page 2](https://image.slidesharecdn.com/agiledeploymentpredictiveanalyticsonhadoop-120620115854-phpapp02/85/Agile-deployment-predictive-analytics-on-hadoop-2-320.jpg)



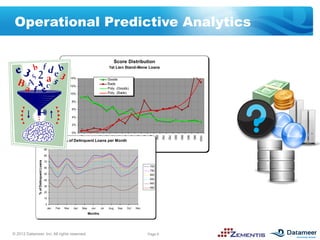
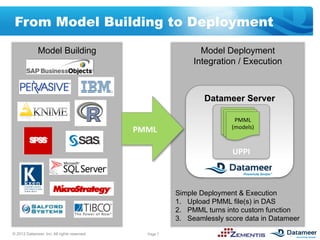

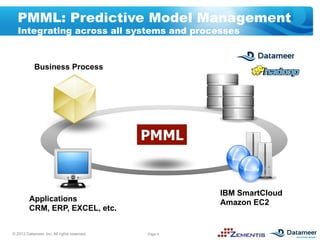
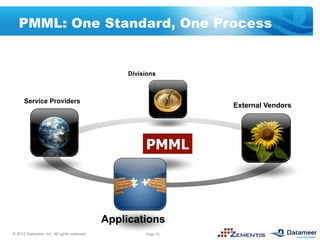





The document discusses leveraging open standards like PMML and tools from Datameer and Zementis to enable agile deployment of predictive analytics on Hadoop. PMML allows incorporating predictive models from various sources and applying them to big data via a lightweight process. This accelerates time to market, lowers costs and complexity, and reuses existing predictive assets.






















































































