Downloaded 279 times











![17 © Hortonworks Inc. 2011–2018. All rights reserved
1
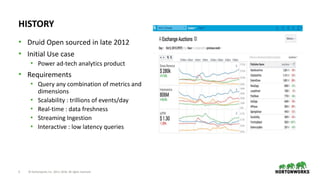
Dictionary Encoding
• Create and store Ids for each value
• e.g. page column
⬢ Values - Justin Bieber, Ke$ha, Selena Gomes
⬢ Encoding - Justin Bieber : 0, Ke$ha: 1, Selena Gomes: 2
⬢ Column Data - [0 0 0 1 1 2]
• city column - [0 0 0 1 1 1]
timestamp page language city country … added deleted
2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65
2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62
2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45
2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87
2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99
2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53](https://image.slidesharecdn.com/anintroductiontodruid-180428004007/85/An-Introduction-to-Druid-17-320.jpg)
![18 © Hortonworks Inc. 2011–2018. All rights reserved
1
Bitmap Indices
• Store Bitmap Indices for each value
⬢ Justin Bieber -> [0, 1, 2] -> [1 1 1 0 0 0]
⬢ Ke$ha -> [3, 4] -> [0 0 0 1 1 0]
⬢ Selena Gomes -> [5] -> [0 0 0 0 0 1]
• Queries
⬢ Justin Bieber or Ke$ha -> [1 1 1 0 0 0] OR [0 0 0 1 1 0] -> [1 1 1 1 1 0]
⬢ language = en and country = CA -> [1 1 1 1 1 1] AND [0 0 0 1 1 1] -> [0 0 0 1 1 1]
• Indexes compressed with Concise or Roaring encoding
timestamp page language city country … added deleted
2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65
2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62
2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45
2011-01-01T00:01:35Z Ke$ha en Calgary CA 17 87
2011-01-01T00:01:35Z Ke$ha en Calgary CA 43 99
2011-01-01T00:01:35Z Selena Gomes en Calgary CA 12 53](https://image.slidesharecdn.com/anintroductiontodruid-180428004007/85/An-Introduction-to-Druid-18-320.jpg)




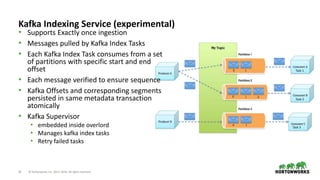













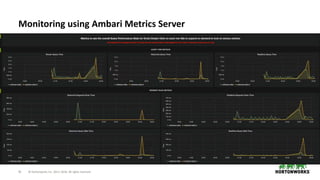



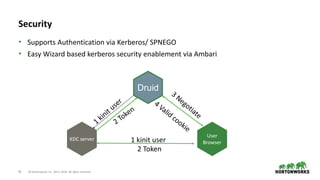







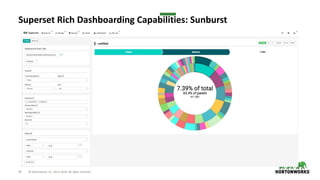


The document provides an overview of Druid, a column-oriented distributed datastore designed for business intelligence and analytics, particularly for real-time data processing with capabilities for sub-second query times. It covers Druid's architecture, including its various node types, data storage formats, indexing services, and querying options, along with use cases and performance metrics. Additionally, it touches on operational considerations such as cluster management, monitoring, high availability, and security features relevant to deploying Druid in production environments.






















































































