Download as PPSX, PPTX







![12 | AMD Direct3D Futures | March 20th, 2014
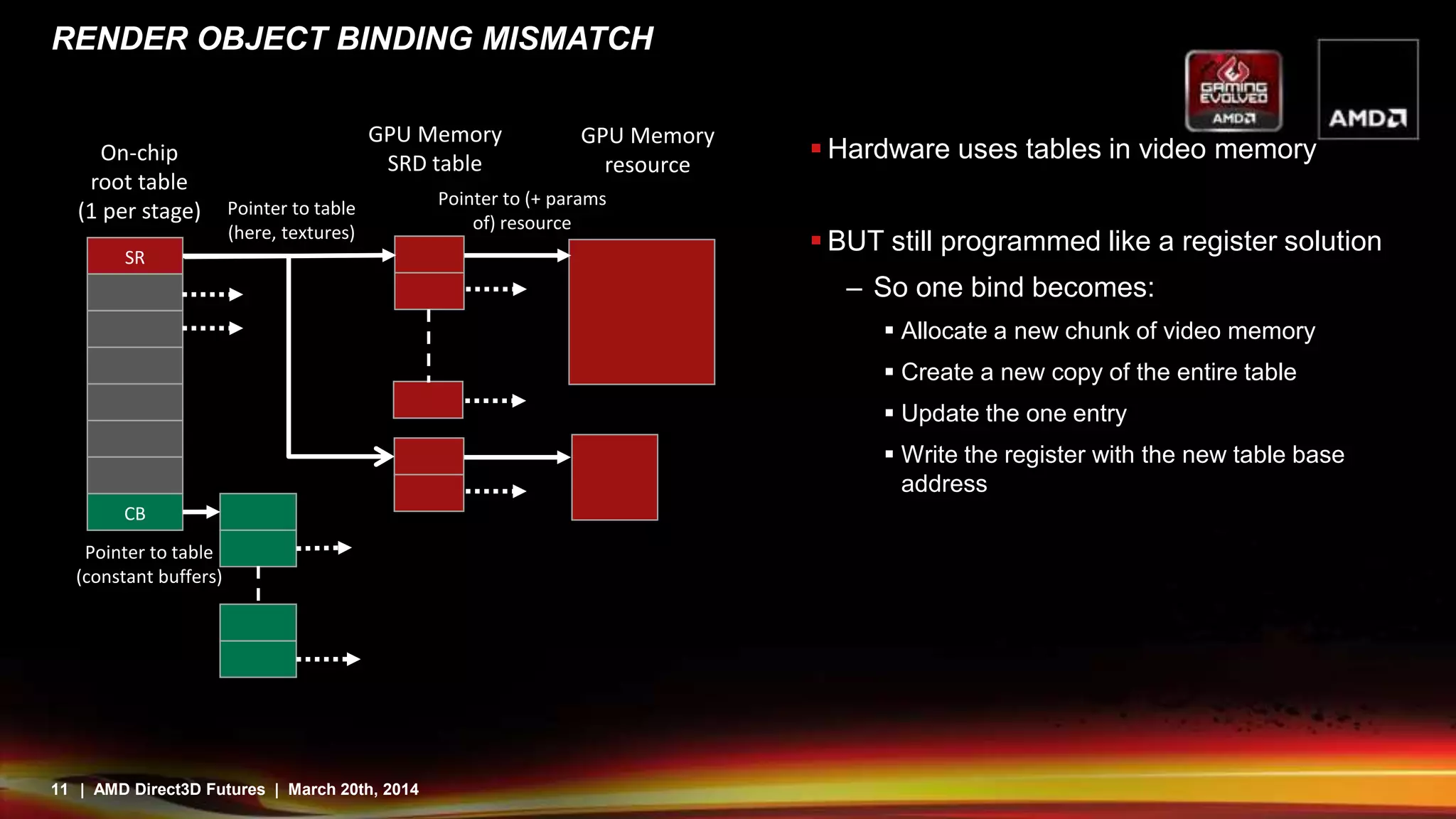
DESCRIPTOR TABLES
Several tables of each type of resource
– Easy to divide up by frequency
Tables can be of arbitrary size; dynamically indexed to
provide bindless textures
Changing a pointer in the root table is cheap
Updating a descriptor in a table is not so cheap
– Some dynamic descriptors are a requirement but avoid
in general.
SR.T[0]
SR.T[3]
SR.T[2]
SR.T[1]
UAV
CB.T[1]
CB.T[0]
Samp
SR.T[0][0]
SR.T[0][2]
SR.T[0][1]
CB.T[1][0]
CB.T[1][1]
On-chip
root table Pointer to table
(textures table 0)
GPU Memory
SRD table
Pointer to table
(constbuf table 1)](https://image.slidesharecdn.com/d3d12andthefutureofgraphicsapisbydaveoldcorn-140609112146-phpapp02/75/Direct3D12-and-the-Future-of-Graphics-APIs-by-Dave-Oldcorn-12-2048.jpg)

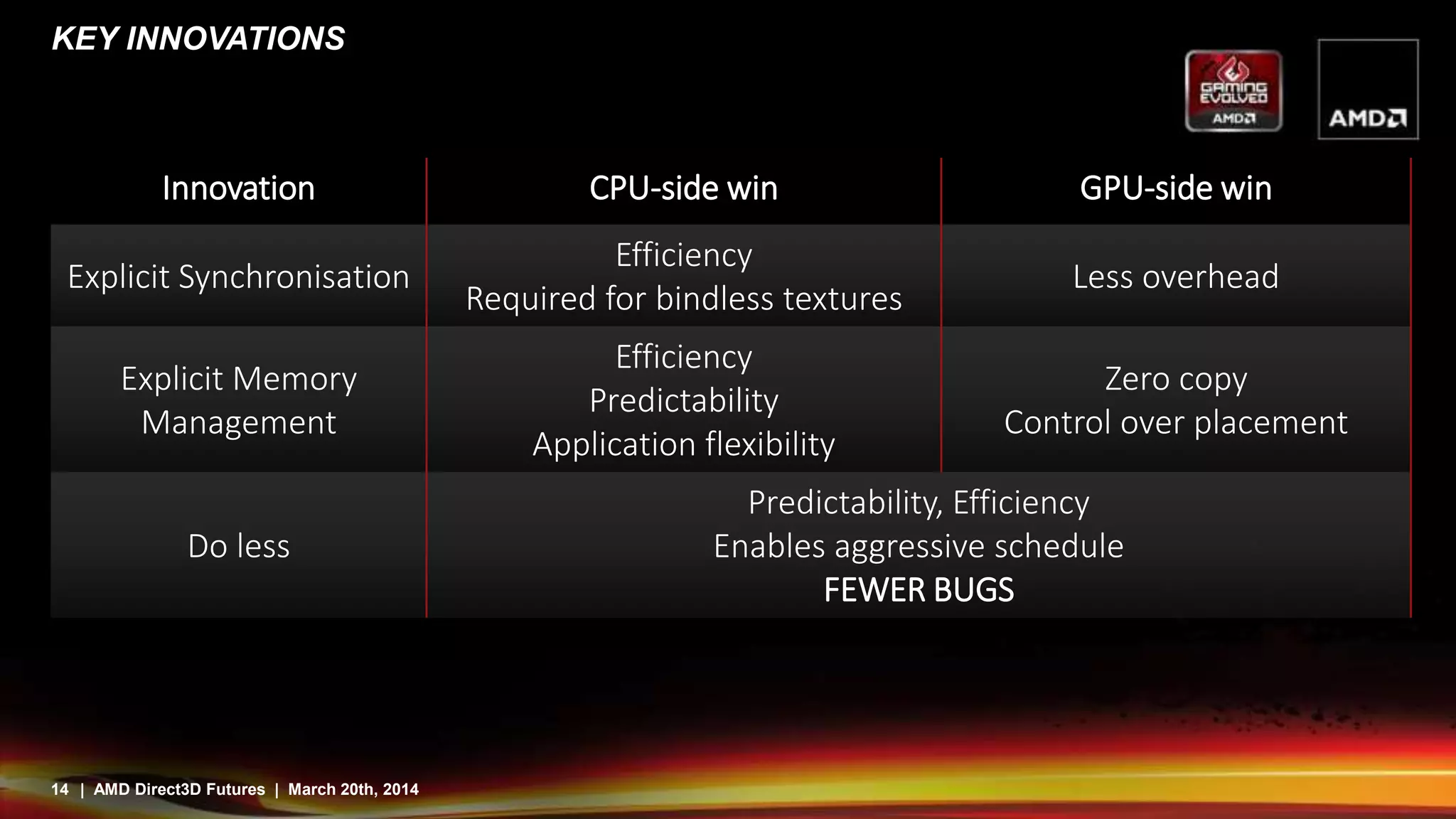











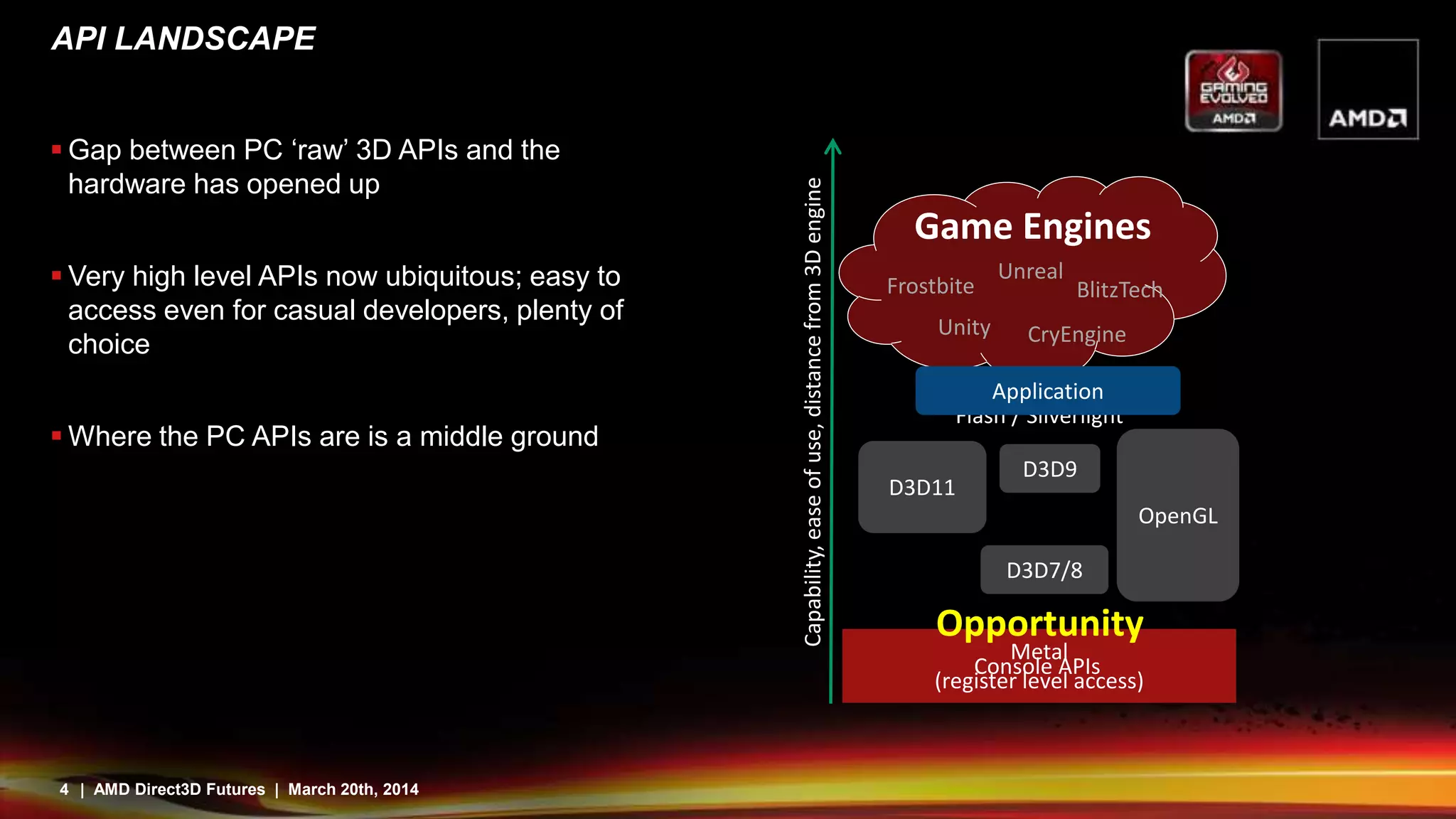
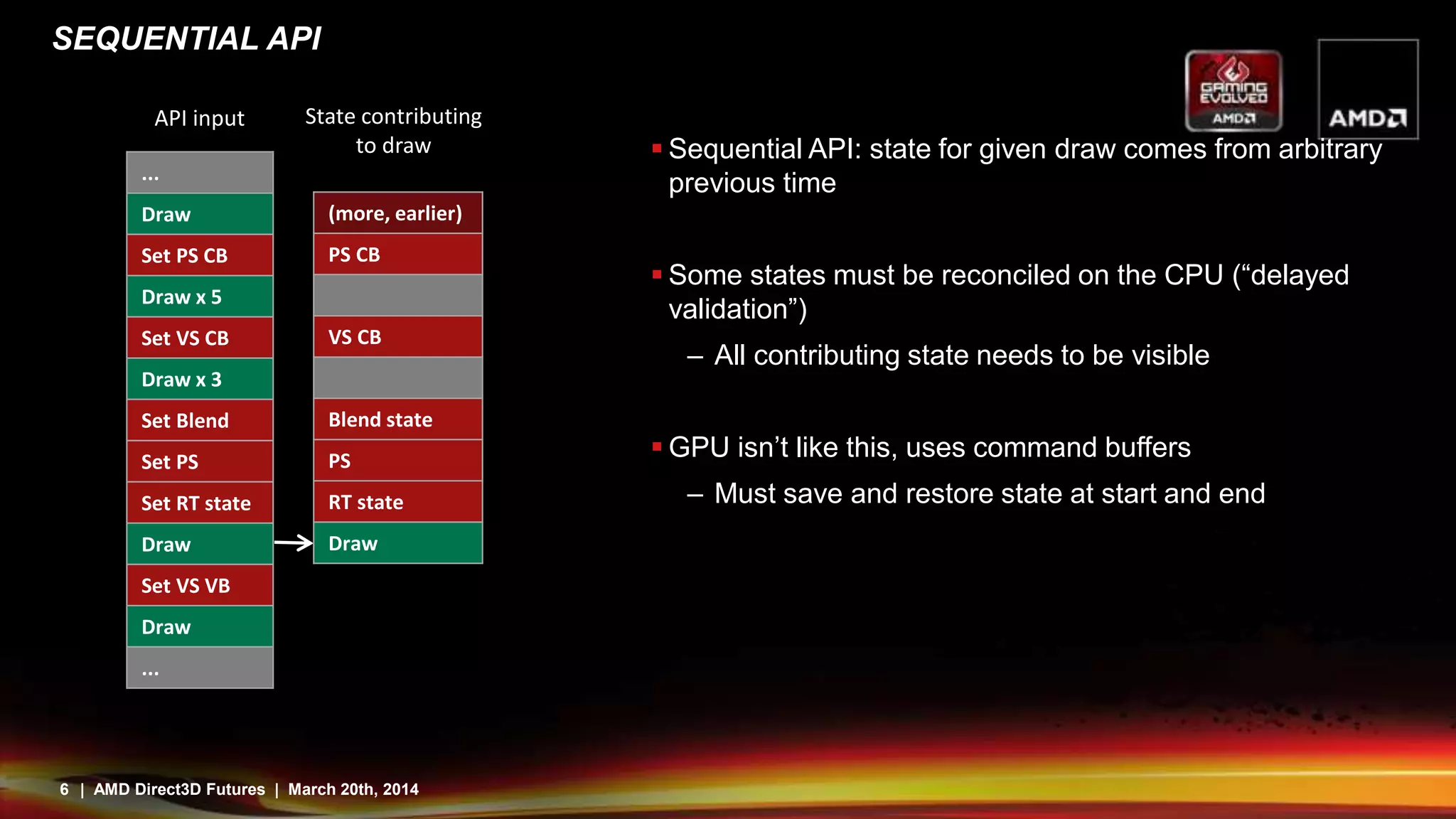
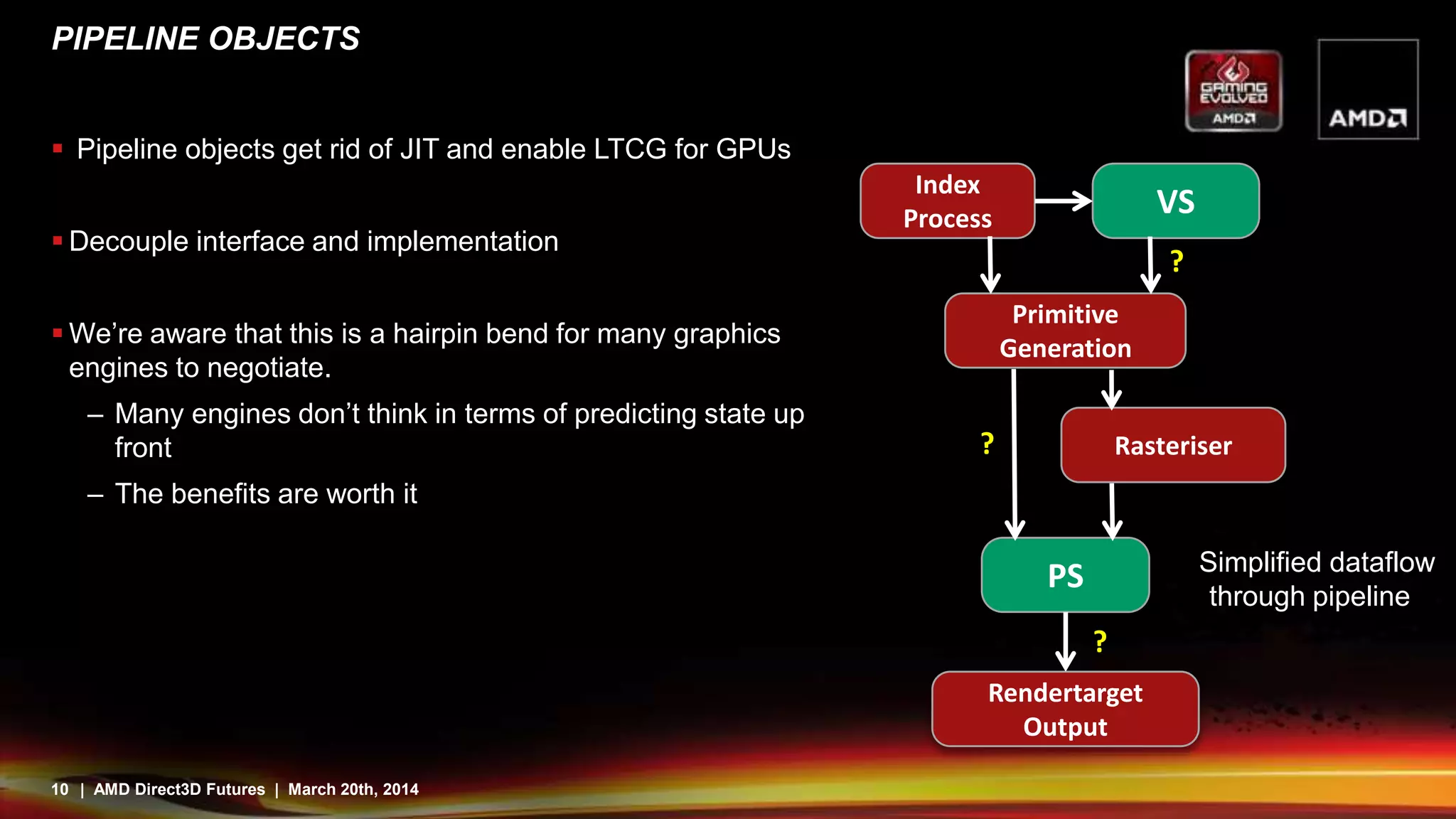
Direct3D12 aims to address issues with existing APIs by providing a more direct mapping to hardware capabilities. It features command buffers that allow work to be built in parallel threads and scheduled more efficiently. Pipeline state objects avoid runtime compilation overhead. Descriptor tables provide bindless resources through pointers and reduce state changes. While this gives more control and efficiency, it also means applications have more responsibility to avoid errors. Overall, Direct3D12 is designed to better expose the capabilities of modern graphics hardware.




























![[学内勉強会]C++11とdirectxライブラリ](https://cdn.slidesharecdn.com/ss_thumbnails/cdirectx911-140128050214-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































