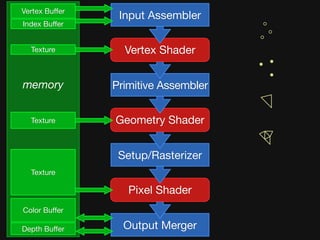
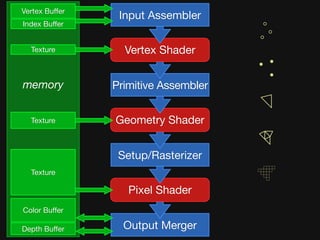
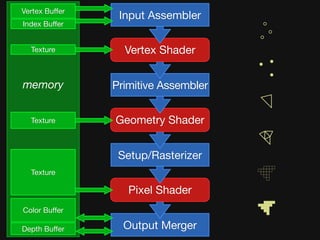
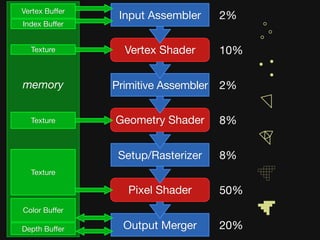
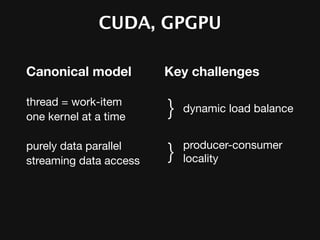
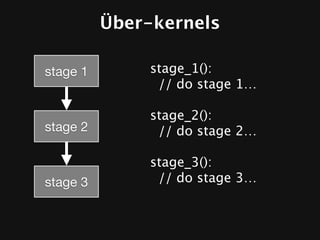
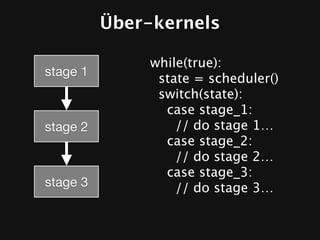
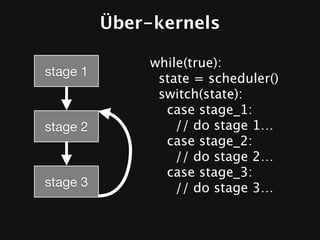
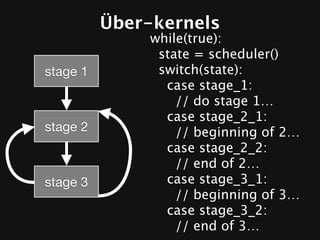
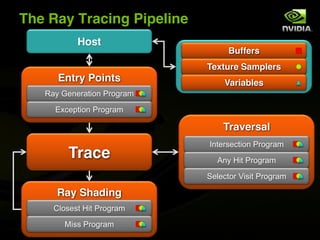
The document discusses the efficiency of graphics processing and its implications for parallel programming, highlighting various forms of parallelism such as data parallelism and task parallelism within graphics pipelines. It explores implementation details like load balancing, scheduling, and memory access, emphasizing the challenges and future directions for more dynamic task decomposition and orchestration in GPUs. The integration of advanced structures like 'über-kernels' aims to enhance performance by managing complex tasks in a more efficient manner.








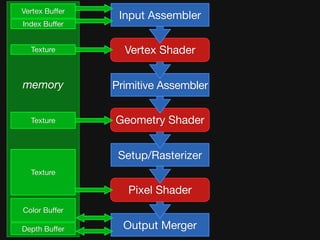
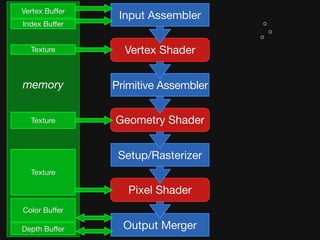
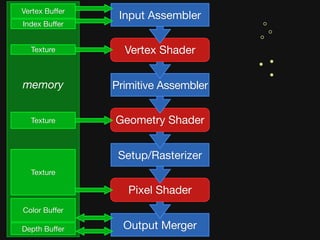
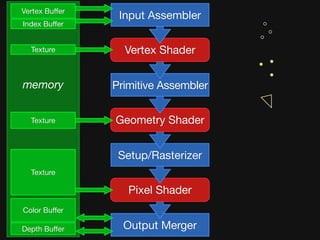




![Shader Stage-specific Variation
Vertex
less latency hiding needed,
so use less local memory,
[perhaps] no dynamic fibering (simpler schedule).
Geometry
variable output.
more state = less parallelism,
but (hopefully) need less latency hiding.
Fragment
derivatives → neighborhood communication.
texture intensive → more (dynamic) latency hiding.](https://image.slidesharecdn.com/fastgraphicspipelinessketch-091230194902-phpapp02/85/Why-Graphics-Is-Fast-and-What-It-Can-Teach-Us-About-Parallel-Programming-20-320.jpg)
![Fixed-function Stages
[Input,Primitive] Assembly
Hairy finite state machine
Indirect indexing
Rasterization
Locally data-parallel (~16xSIMD), No memory access
Globally branchy, incremental, hierarchical
Output Merge
Really data-parallel, but ordered read-modify-write
Implicit data amplification (for antialiasing)](https://image.slidesharecdn.com/fastgraphicspipelinessketch-091230194902-phpapp02/85/Why-Graphics-Is-Fast-and-What-It-Can-Teach-Us-About-Parallel-Programming-21-320.jpg)



![Sort-Middle
Front-end: transform/vertex processing
Scatter all geometry to screen-space tiles
Merge sort (through memory)
Maintain primitive order
Back-end: pixel processing
In-order (per-pixel)
scoreboard per-pixel → screen-space parallelism
One tile per-core
framebuffer data in local store
one scheduler, several worker [hardware] threads collaborating
Pixel Shader + Output Merge together
lower scheduling overhead](https://image.slidesharecdn.com/fastgraphicspipelinessketch-091230194902-phpapp02/85/Why-Graphics-Is-Fast-and-What-It-Can-Teach-Us-About-Parallel-Programming-25-320.jpg)



























































![[Unite Seoul 2019] Mali GPU Architecture and Mobile Studio](https://cdn.slidesharecdn.com/ss_thumbnails/maligpuarchitectureandmobilestudiofinal3-190717042828-thumbnail.jpg?width=640&height=640&fit=bounds)















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







