Downloaded 852 times




























![MaterialID pack/unpack
- Using texcoord (uv/uv2)
- pack: mesh.uv[i].x = mesh.uv[i].x + MaterialID;
- unpack: int MaterialID = (int) v.texcoord.x;
- Using color
- pack: mesh.colors32[i].a = MaterialID;
- unpack: int MaterialID = (int) (v.color.a*255.0f + 0.5f);](https://image.slidesharecdn.com/googlei-o2014-140811015501-phpapp02/85/Optimizing-unity-games-Google-IO-2014-29-320.jpg)





























































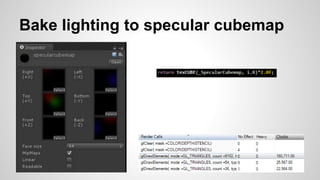








The document covers optimization techniques for Unity games, focusing on CPU and GPU performance improvements over a range of platforms. It includes methods for identifying bottlenecks, optimizing draw calls, vertex and fragment shaders, as well as caching strategies for mathematical computations. Various tools and profiling techniques are emphasized for real-time performance analysis and optimization strategies tailored to specific mobile GPU architectures.




![[UniteKorea2013] Memory profiling in Unity](https://cdn.slidesharecdn.com/ss_thumbnails/memoryprofilinginunity-130509204713-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[Unite Seoul 2020] Mobile Graphics Best Practices for Artists](https://cdn.slidesharecdn.com/ss_thumbnails/arm-uniteseoul2020final-210524084305-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Unity Forum 2019] Mobile Graphics Optimization Guides](https://cdn.slidesharecdn.com/ss_thumbnails/20191108taipeiunityforum-191204024024-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TGDF 2020] Mobile Graphics Best Practices for Artist](https://cdn.slidesharecdn.com/ss_thumbnails/mobilegraphicsbestpracticesforartist-200712102753-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Unite Seoul 2019] Mali GPU Architecture and Mobile Studio](https://cdn.slidesharecdn.com/ss_thumbnails/maligpuarchitectureandmobilestudiofinal3-190717042828-thumbnail.jpg?width=640&height=640&fit=bounds)