Downloaded 26 times



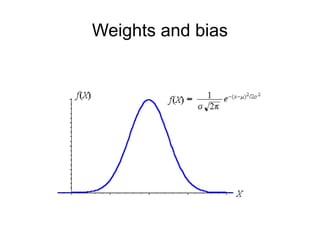
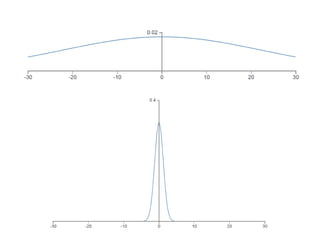
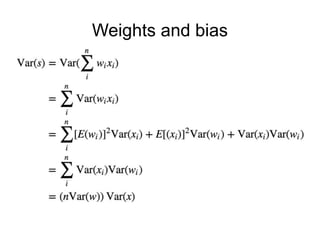



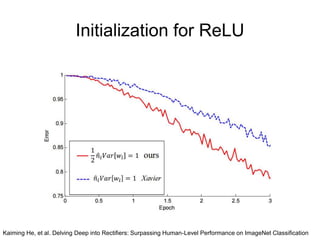

The document discusses different methods for initializing weights in neural networks. It first mentions that all zero initialization causes every neuron to compute the same output, lacking asymmetry. Xavier initialization scales the variance of the weights so that the variance of the input and output are the same. Initialization for ReLU networks is discussed in a paper by Kaiming He et al. that achieved human-level performance on ImageNet classification.























































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)











![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)