Downloaded 66 times








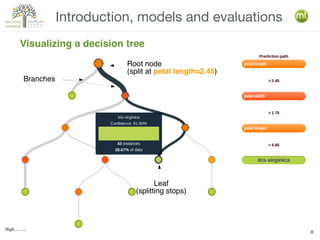







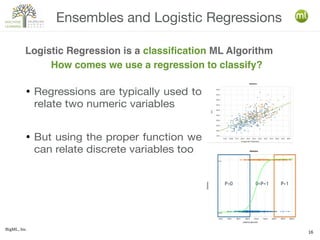












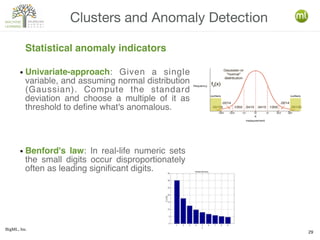
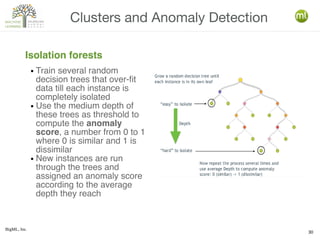




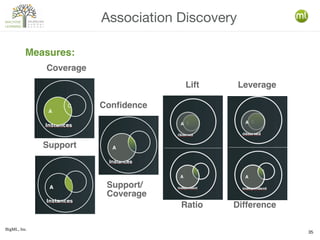
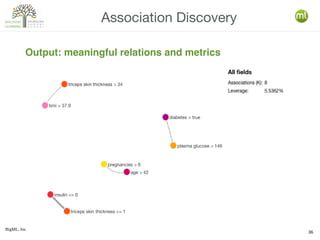




The document discusses various machine learning techniques, including decision trees, clustering, and anomaly detection. It highlights the importance of data-driven decision-making and outlines steps for creating machine learning programs, explaining algorithms and their evaluations. Additionally, it covers ensemble methods and the role of logistic regression, as well as the uses of clustering and anomaly detection in applications like customer segmentation and fraud detection.























































































