Download to read offline




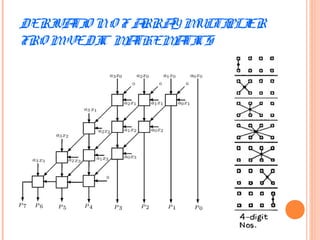
![TABLE 1- 16 x 16 bit Vedic multiplier Using Urdhva Tiryakbhyam
CP- Cross Product (Vertically and Crosswise)
A= A15 A14 A13 A12 A11 A10 A9 A8 A7 A6 A5 A4 A3 A2 A1 A0
X3 X2 X1 X0
B= B15 B14 B13 B12 B11 B10 B9 B8 B7 B6 B5 B4 B3 B2 B1 B0
Y3 Y2 Y1 Y0
X3 X2 X1 X0 Multiplicand[16 bits]
Y3 Y2 Y1 Y0 Multiplier [16 bits]
------------------------------------------------------------------
J I H G F E D C
P7 P6 P5 P4 P3 P2 P1 P0 Product[32 bits]
Where X3, X2, X1, X0, Y3, Y2, Y1 and Y0 are each of 4 bits.
PARALLEL COMPUTATION & METHODOLOGY
1. CP X0 = X0 * Y0 = A
Y0
2. CP X1 X0 = X1 * Y0+X0 * Y1= B
Y1 Y0
3 CP X2 X1 X0 = X2 * Y0 +X0 * Y2 +X1 * Y1=C
Y2 Y1 Y0
4 CP X3 X2 X1 X0 = X3 * Y0 +X0 * Y3+X2 * Y1 +X1 * Y2=D
Y3 Y2 Y1 Y0
5 CP X3 X2 X1 = X3 * Y1+X1 * Y3+X2 * Y2=E
Y3 Y2 Y1
6 CP X3 X2 = X3 * Y2+X2 * Y3=F
Y3 Y2
7 CP X3 = X3 * Y3 =G
Y3
Note: Each Multiplication operation is an embedded parallel 4x4 multiply module](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-5-320.jpg)


![DUPLEXFO R BINARY NUMBER
In order to calculate the square of a number
“Duplex” D property of binary numbers has been
taken advantage of. In the Duplex, we take twice
the product of the outermost pair, and then add
twice the product of the next outermost pair, and
so on till no pairs are left. When there are odd
number of bits in the original sequence, there is
one bit left by itself in the middle, and this enters
as such.
[1] H.Thapliyal and and H.R. Arabnia , "A Time-Area-Power Efficient Multiplier and Square Architecture Based On Ancient
Indian Vedic Mathematics", Proceedings of the 2004 International Conference on VLSI (VLSI'04: Las Vegas, USA), Paper
acceptance rate of 35%; pp. 434-439.
[2]H. Thapliyal and M.B. Srinivas ,”Design and Analysis of A Novel Parallel Square and Cube Architecture Based On
Ancient Indian Vedic Mathematics", Proceedings of the 48th IEEE MIDWEST Symposium on Circuits and Systems
(MWSCAS 2005), Cincinnati, Ohio, USA, August 7-10, 2005, pp.1462-1465.
[3] H. Thapliyal and M.B. Srinivas ,”An Efficient Method of Elliptic Curve Encryption Using Ancient Indian Vedic
Mathematics", Proceedings of the 48th IEEE MIDWEST Symposium on Circuits and Systems (MWSCAS 2005),
Cincinnati, Ohio, USA, August 7-10, 2005, pp. 826-829.](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-10-320.jpg)

![SQUARE PRO PO SED IN[1 , 2]
[1] Albert A. Liddicoat and Michael J. Flynn, "Parallel Square and Cube Computations", 34th
Asilomar Conference on Signals, Systems, and Computers, California, October 2000.
[2] Albert Liddicoat and Michael J. Flynn," Parallel Square and Cube Computations", Technical
report CSL-TR-00-808 , Stanford University, August 2000.](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-12-320.jpg)
![PRO PO SED SQUARE
The proposed square architecture is an
improvement over partition multipliers in which
the NXN bit multiplication can be performed by
decomposing the multiplicand and multiplier
bits into M partitions where M=N/K ( here N
is the width of multiplicand and
multiplier(divisible by 4 ) and K is a multiple
of 4 such as 4, 8 , 12 ,16……….. 4* n). The
partition multipliers are the fastest multipliers
implemented in the commercial processors and
are much faster than conventional multipliers.[1] H. Thapliyal and M.B. Srinivas ,”Design and Analysis of A Novel Parallel Square and Cube Architecture
Based On Ancient Indian Vedic Mathematics", Proceedings of the 48th IEEE MIDWEST Symposium on Circuits
and Systems (MWSCAS 2005), Cincinnati, Ohio, USA, August 7-10, 2005, pp.1462-1465.
[2] H. Thapliyal and M.B. Srinivas ,”An Efficient Method of Elliptic Curve Encryption Using Ancient Indian Vedic
Mathematics", Proceedings of the 48th IEEE MIDWEST Symposium on Circuits and Systems (MWSCAS 2005),
Cincinnati, Ohio, USA, August 7-10, 2005, pp. 826-829.](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-13-320.jpg)

![CO MPARISO NWITH [1 , 2]
[1] Albert A. Liddicoat and Michael J. Flynn, "Parallel Square and Cube Computations", 34th
Asilomar Conference on Signals, Systems, and Computers, California, October 2000.
[2] Albert Liddicoat and Michael J. Flynn," Parallel Square and Cube Computations", Technical
report CSL-TR-00-808 , Stanford University, August 2000.](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-15-320.jpg)

![This sutra has been utilized in this work to find the cube of a number.
The number M of N bits having its cube to be calculated is divided in
two partitions of N/2 bits, say a and b, and then the Anurupya Sutra is
applied to find the cube of the number.
[1] H. Thapliyal and M.B. Srinivas ,”Design and Analysis of A Novel Parallel Square and Cube Architecture
Based On Ancient Indian Vedic Mathematics", Proceedings of the 48th IEEE MIDWEST Symposium on Circuits
and Systems (MWSCAS 2005), Cincinnati, Ohio, USA, August 7-10, 2005, pp.1462-1465.
[2] H. Thapliyal and M.B. Srinivas ,”An Efficient Method of Elliptic Curve Encryption Using Ancient Indian Vedic
Mathematics", Proceedings of the 48th IEEE MIDWEST Symposium on Circuits and Systems (MWSCAS 2005),
Cincinnati, Ohio, USA, August 7-10, 2005, pp. 826-829.](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-17-320.jpg)
![CUBE PRO PO SED IN[1 , 2]
[1] Albert A. Liddicoat and Michael J. Flynn, "Parallel Square and Cube Computations", 34th
Asilomar Conference on Signals, Systems, and Computers, California, October 2000.
[2] Albert Liddicoat and Michael J. Flynn," Parallel Square and Cube Computations", Technical
report CSL-TR-00-808 , Stanford University, August 2000.](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-18-320.jpg)
![A COMPARISON
[1] Albert A. Liddicoat and Michael J. Flynn, "Parallel Square and Cube Computations", 34th
Asilomar Conference on Signals, Systems, and Computers, California, October 2000.
[2] Albert Liddicoat and Michael J. Flynn," Parallel Square and Cube Computations", Technical
report CSL-TR-00-808 , Stanford University, August 2000.](https://image.slidesharecdn.com/vedicmathmetics-160626200105/85/Vedic-mathmetics-19-320.jpg)

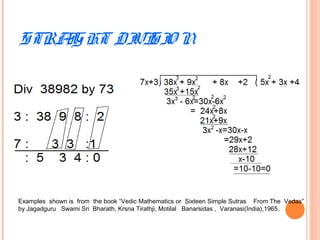



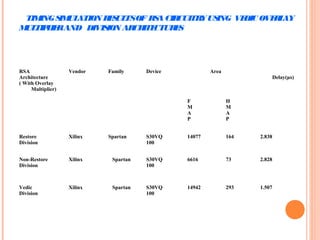
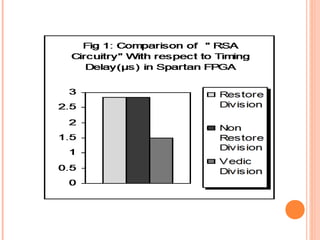




This document discusses the application of Vedic mathematics principles to the design of high-speed arithmetic circuits. It introduces Vedic mathematics, which is based on 16 simple formulae from ancient Hindu scriptures. These formulae can be used to design efficient multiplier and divider architectures. The document presents the implementation of a 16x16 bit Vedic multiplier based on the Urdhva Tiryagbhyam formula. It also discusses square and cube architectures designed using the Duplex property and Anurupya Sutra respectively. The Vedic algorithms allow for faster circuits compared to traditional designs. RSA encryption circuits implemented using the Vedic multiplier and divider show improved performance and timing delays.