Download to read offline













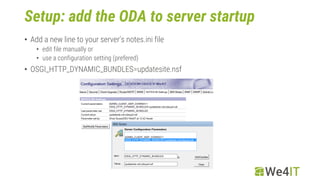



































The document provides an overview of the OpenNTF Domino API (ODA). It discusses what the ODA is, how to set it up and implement it, considerations for using it, and provides examples. Specifically: - The ODA is an open source project that fills gaps and enhances Java capabilities for Domino. It consists of packages that can be installed as an OSGi plugin on Domino servers. - Setup involves importing the ODA into an update site NSF, adding it to the server startup, and preparing Domino Designer. - Other considerations include logging, transactions, views, documents, dates, and graphs. - Examples shown include session handling, view handling,


















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)









