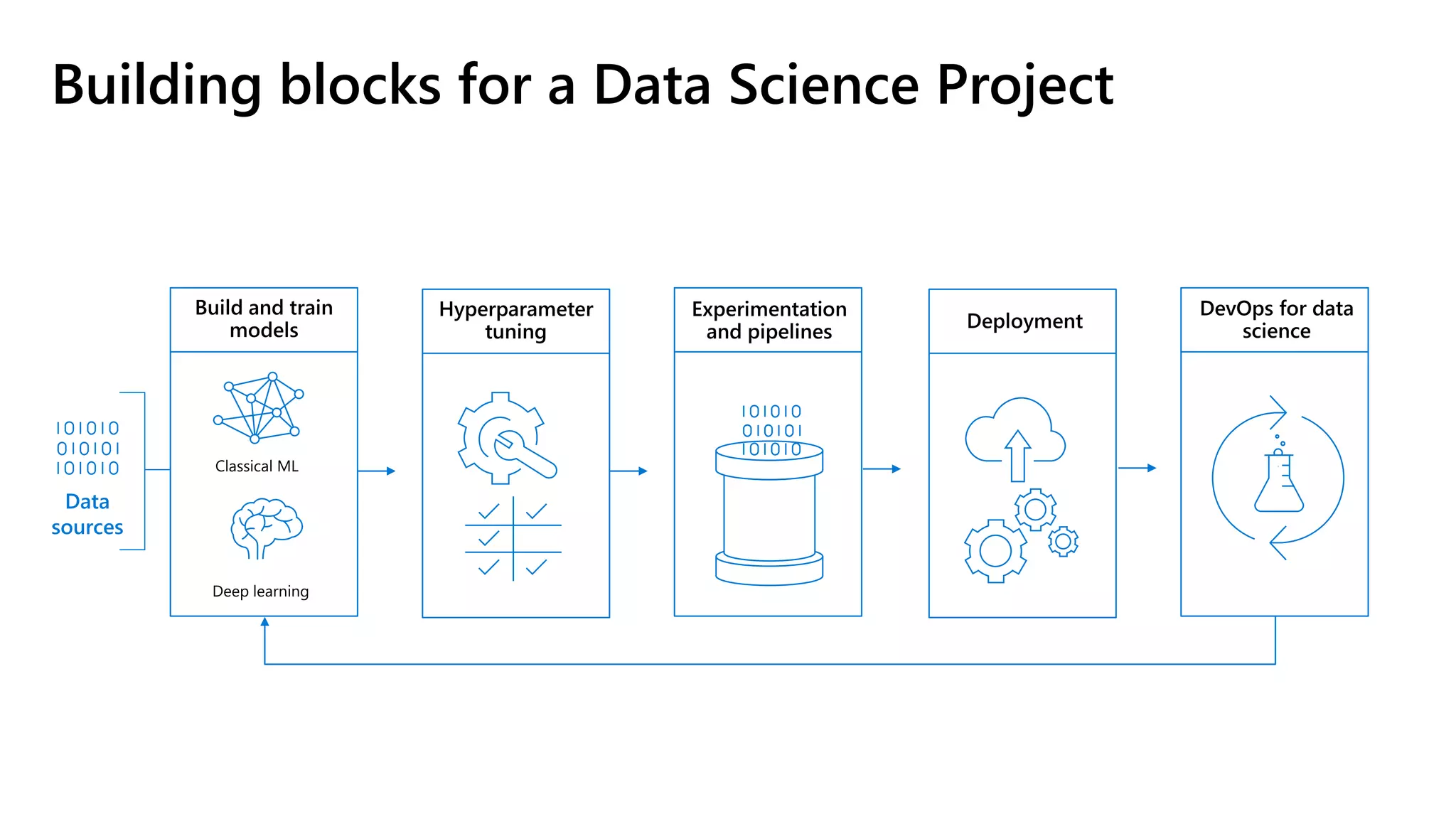
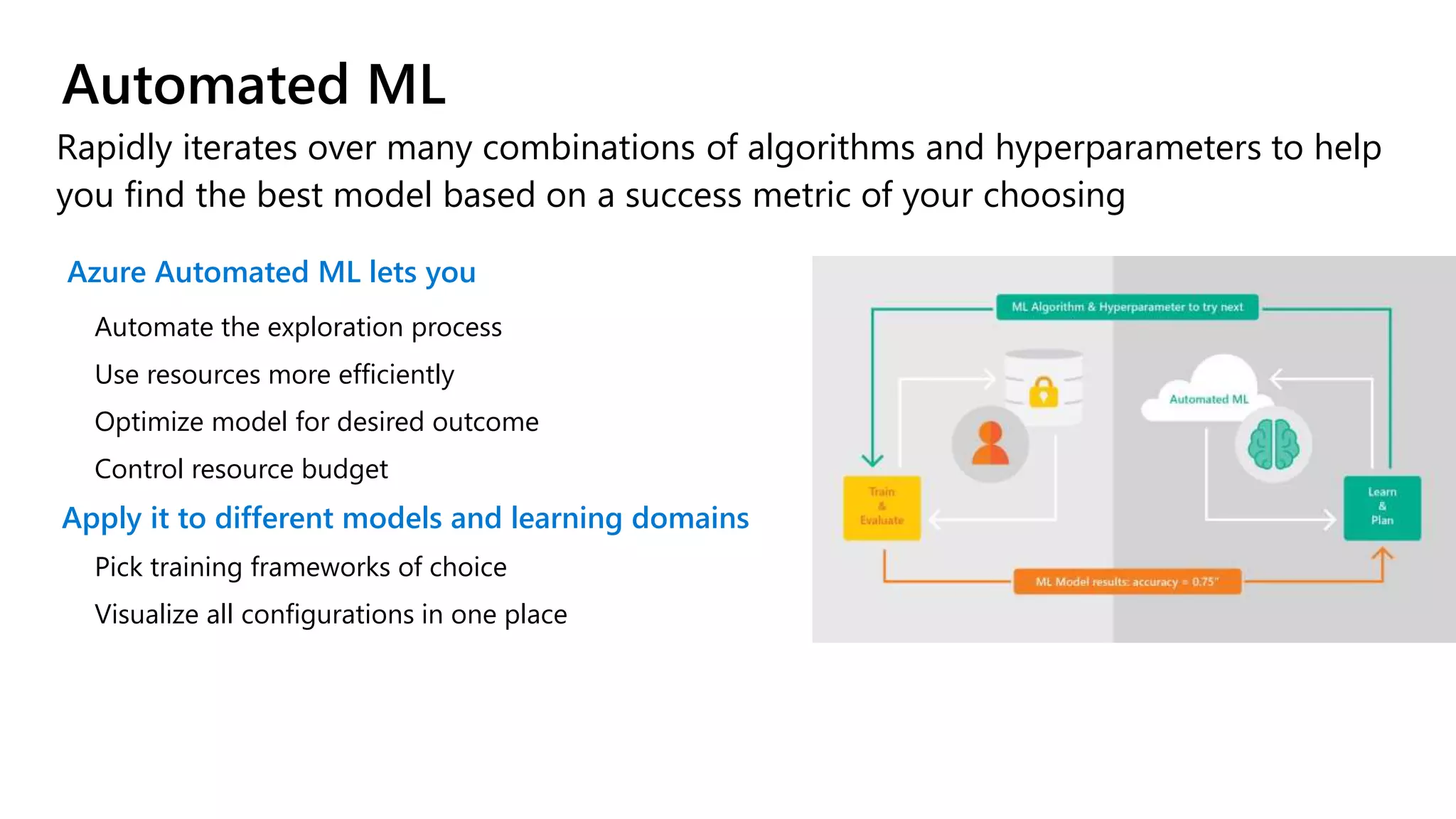
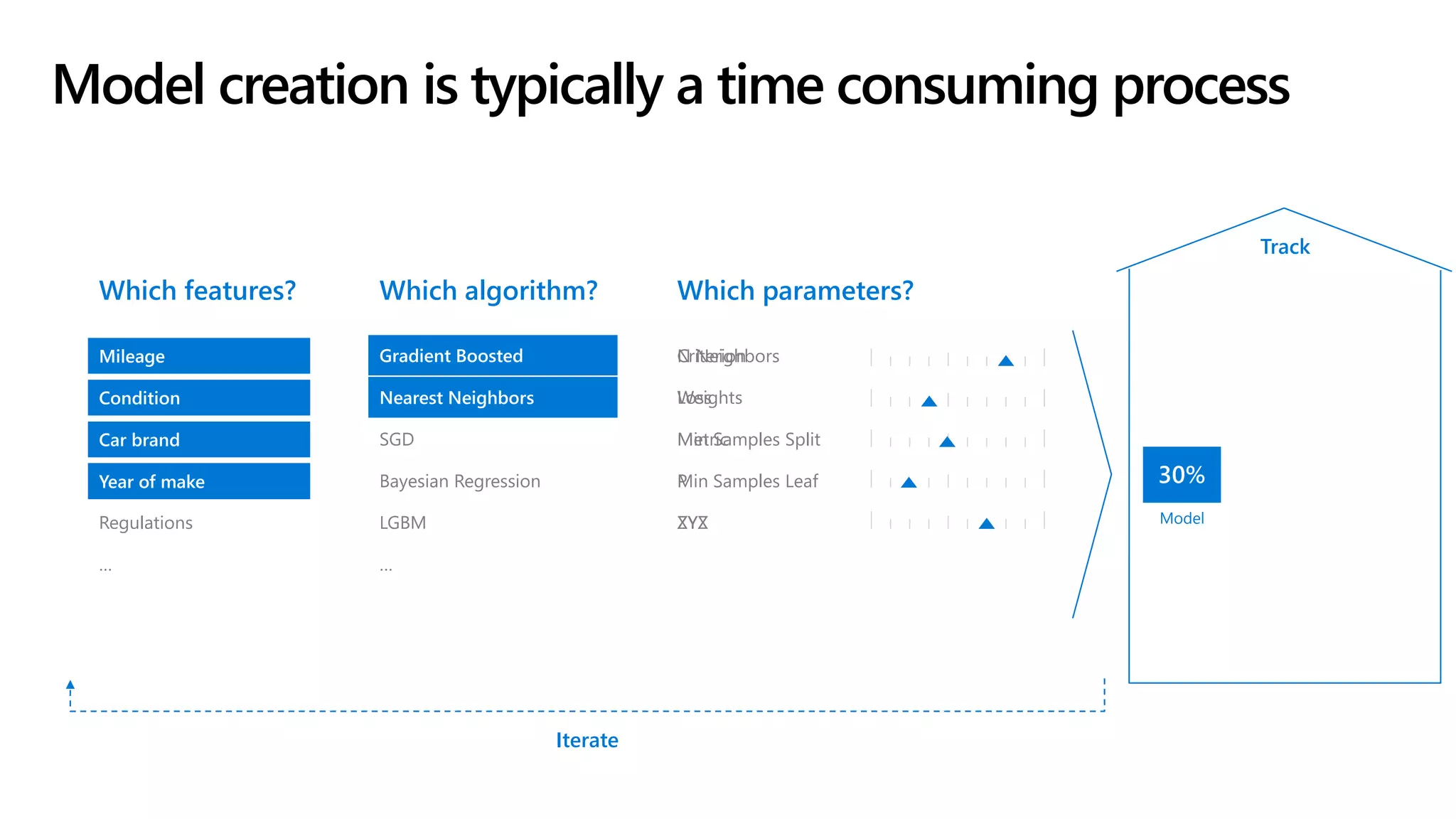
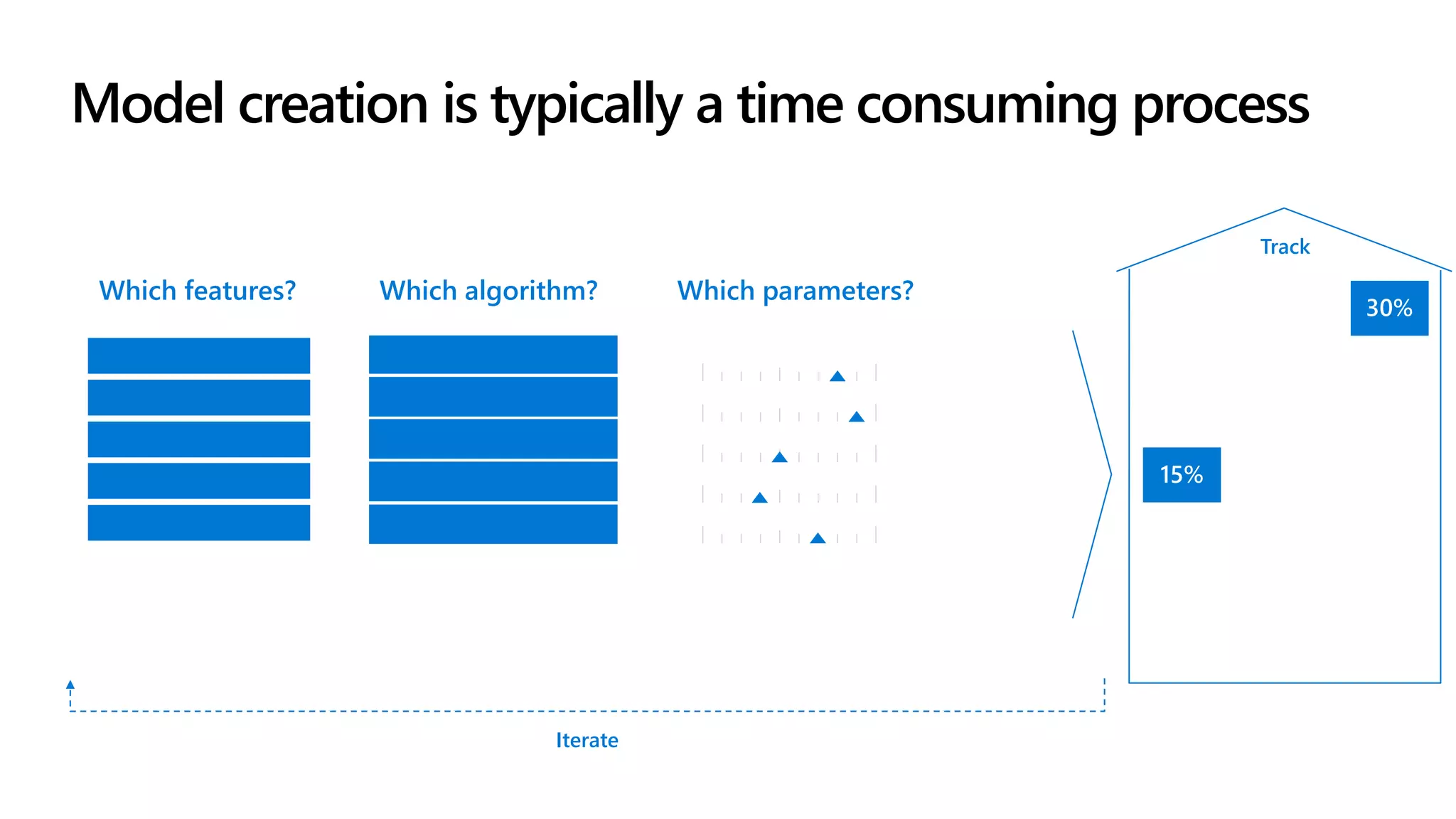
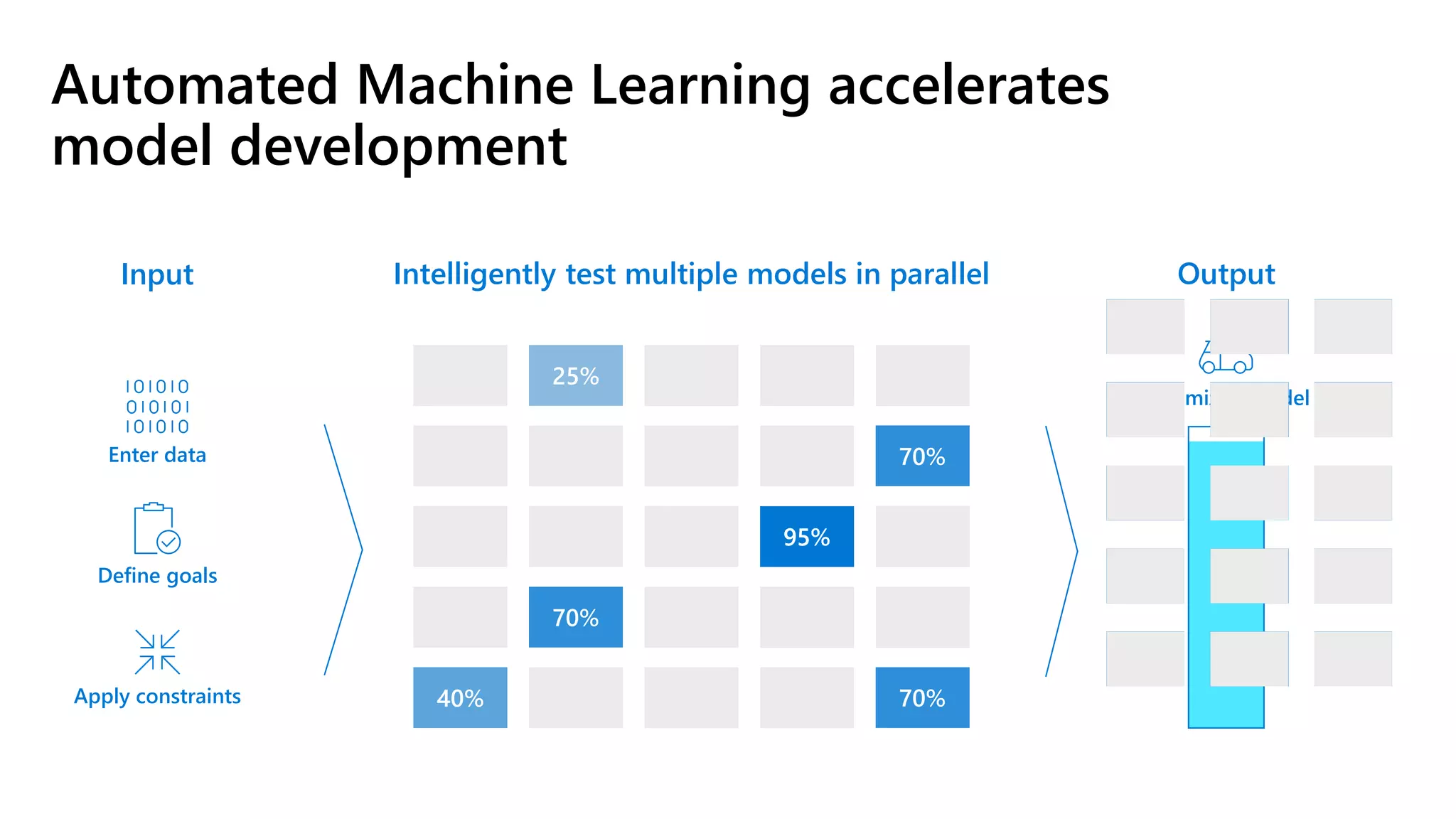
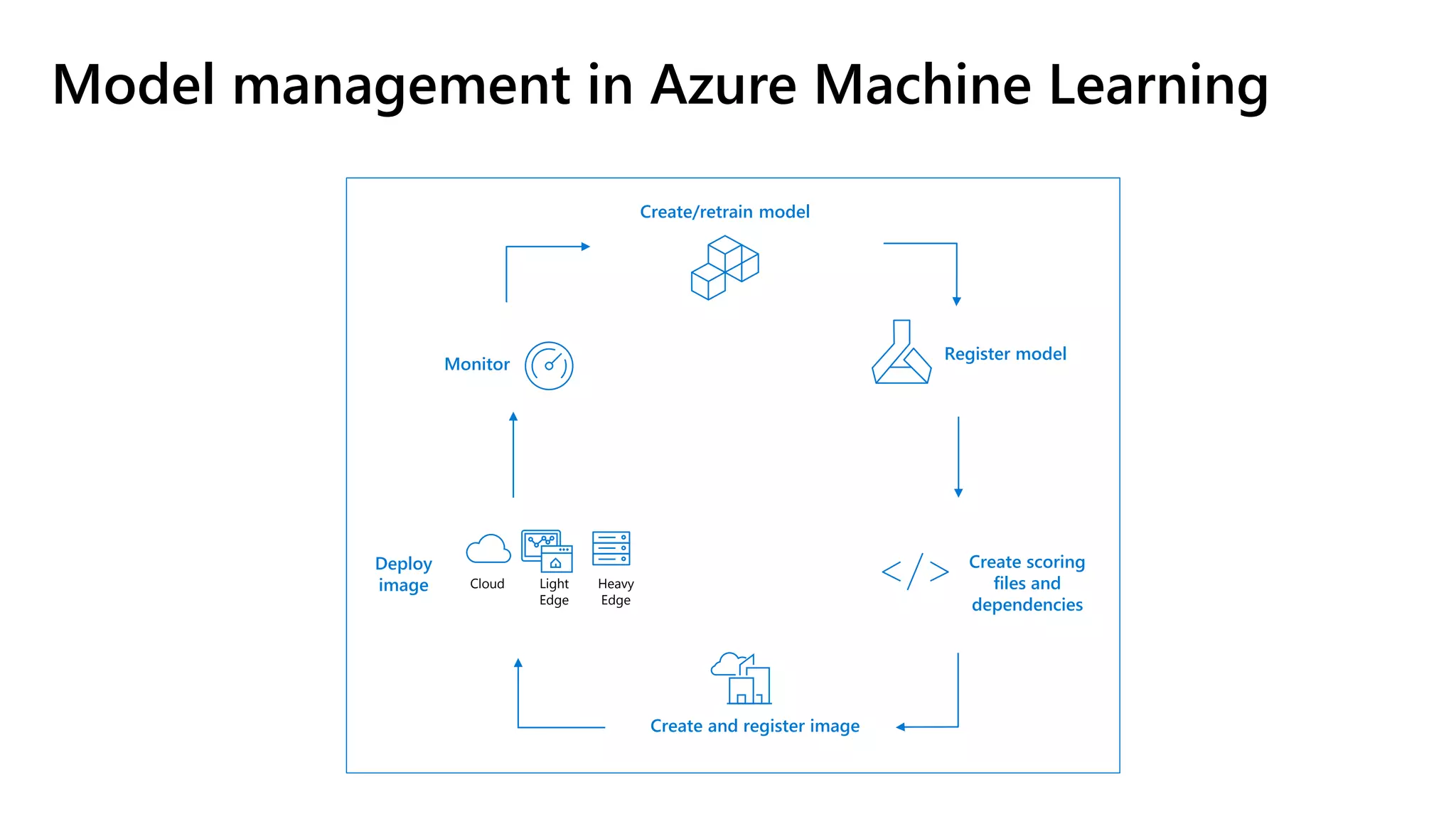
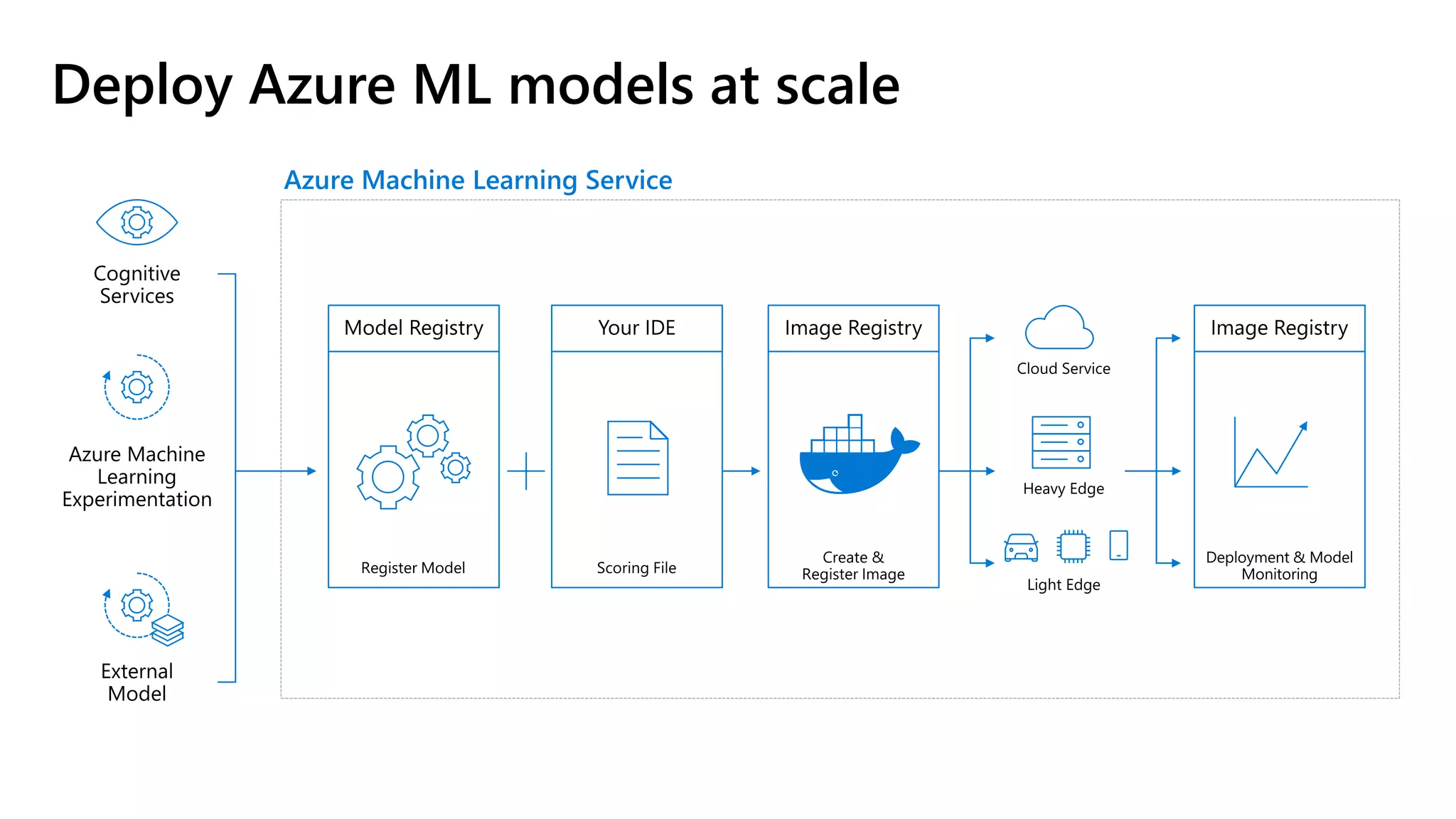
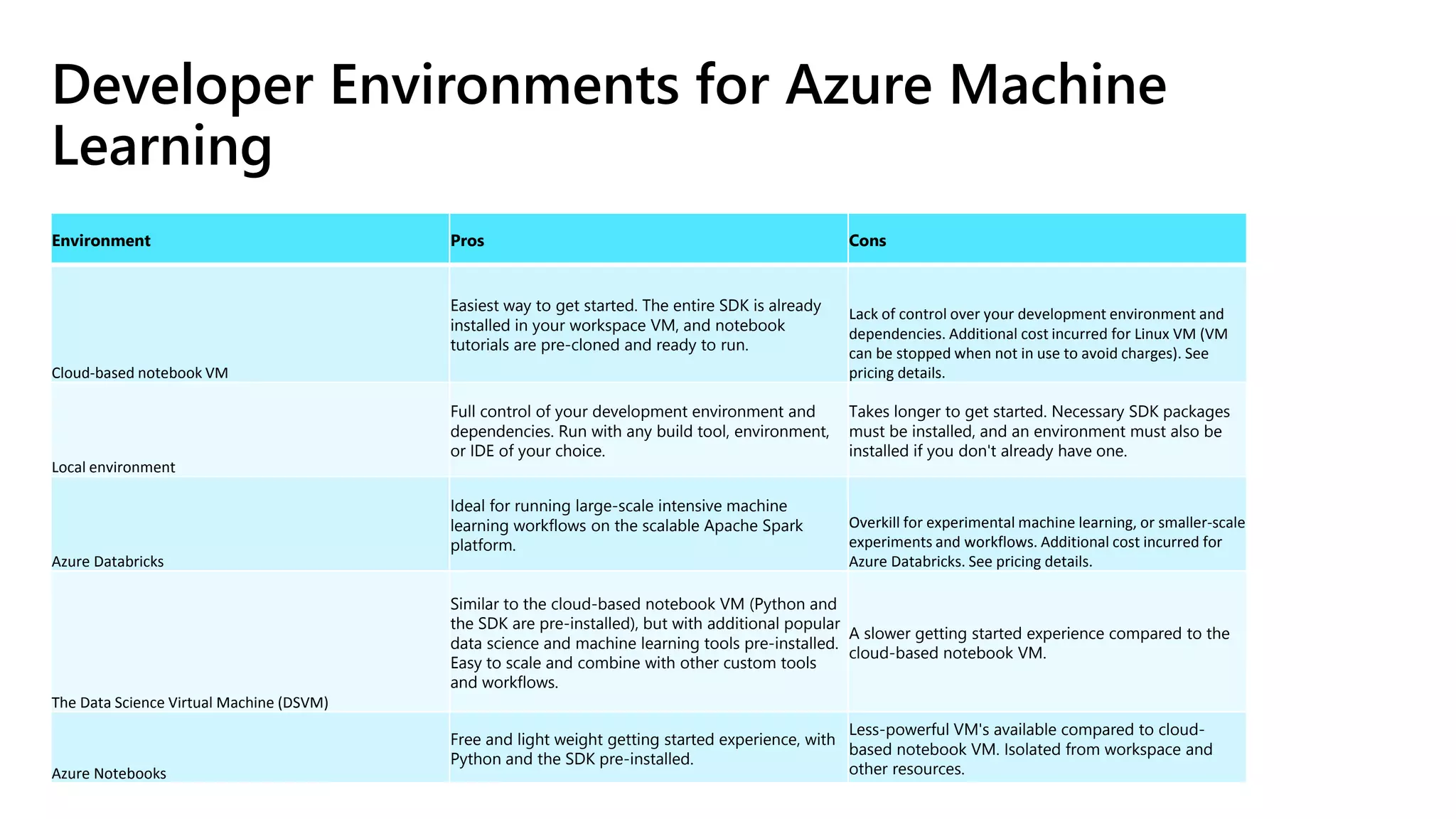
The document outlines the use of Azure Machine Learning services for developing data science projects, detailing the creation and management of workspaces, automated machine learning capabilities, and model deployment. It provides a step-by-step guide for creating a workspace, training models, and deploying them while discussing various Azure resources and environments available for machine learning. The document also highlights pros and cons of different development environments for Azure Machine Learning.












![Step 7 – Create the scoring script
Create the scoring script, called score.py, used by the web service call to show how to use the model.
It requires two functions – init() and run (input data)
from azureml.core.model import Model
def init():
global model
# retreive the path to the model file using the model name
model_path = Model.get_model_path(‘<model-name>’)
model = joblib.load(model_path)
def run(raw_data):
data = np.array(json.loads(raw_data)['data’])
# make prediction
y_hat = model.predict(data) return json.dumps(y_hat.tolist())](https://image.slidesharecdn.com/azuremachinelearningservice-191211194511/75/Azure-machine-learning-service-20-2048.jpg)
![Step 10 – Deploy the model to ACI
%%time
from azureml.core.webservice import Webservice
from azureml.core.image import ContainerImage
# configure the image
image_config = ContainerImage.image_configuration(
execution_script ="score.py",
runtime ="python",
conda_file ="myenv.yml")
service = Webservice.deploy_from_model(workspace=ws, name='sklearn-mnist-svc’,
deployment_config=aciconfig, models=[model],
image_config=image_config)
service.wait_for_deployment(show_output=True)](https://image.slidesharecdn.com/azuremachinelearningservice-191211194511/75/Azure-machine-learning-service-22-2048.jpg)

















































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)






