Downloaded 104 times





























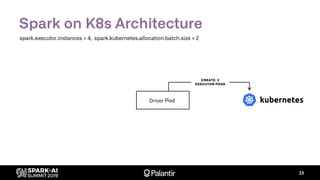
![Spark on K8s Architecture
32
CREATE
DRIVER POD
spark-submit input:
…
--master k8s://example.com:8443
--conf spark.kubernetes.image=example.com/appImage
--conf …
com.palantir.spark.app.main.Main
spark-submit output:
…
spec:
containers:
- name: example
image: example.com/appImage
command: [”/opt/spark/entrypoint.sh"]
args: [”--driver", ”--class”, “com.palantir.spark.app.main.Main”]
…
spark-submit](https://image.slidesharecdn.com/willmanningmattcheah-191103044612/85/Reliable-Performance-at-Scale-with-Apache-Spark-on-Kubernetes-32-320.jpg)
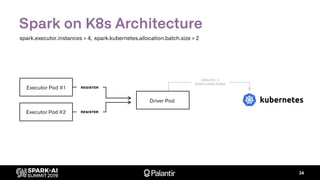
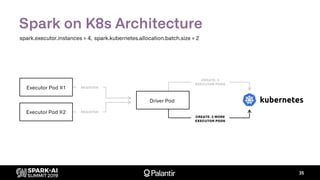
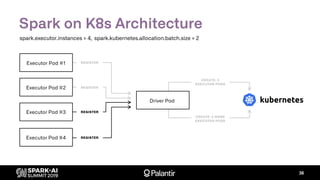
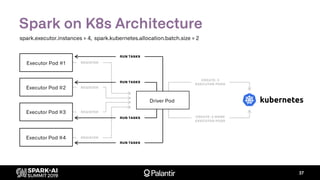












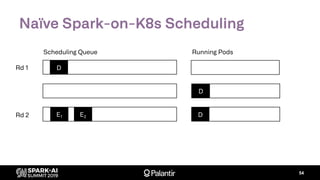
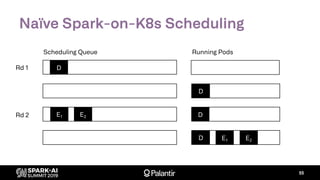


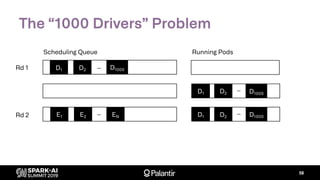
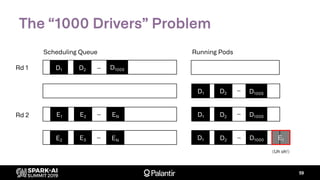


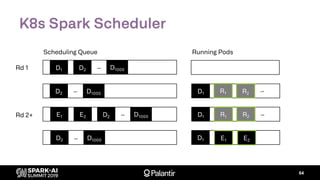
![K8s Spark Scheduler
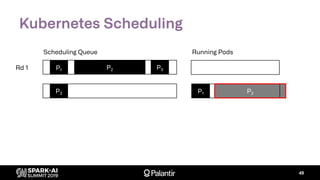
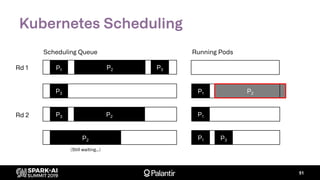
Goal: build entirely with native K8s extension points
– Scheduler extender API: fn(pod, [node]) -> Option[node]
– Custom resource definition: ResourceReservation
– Driver annotations for resource requests (executors)](https://image.slidesharecdn.com/willmanningmattcheah-191103044612/85/Reliable-Performance-at-Scale-with-Apache-Spark-on-Kubernetes-62-320.jpg)






![“Soft” dynamic allocation
72
– Saves $$$$, ~no runtime variance if consistent from run to run
– Inspired by a 2018 Databricks blog post [1]
– Merged into our fork in ~January 2019
– Recently adapted by @vanzin (thanks!) and merged upstream [2]
[1] https://databricks.com/blog/2018/05/02/introducing-databricks-optimized-auto-
scaling.html
[2] https://github.com/apache/spark/pull/24817](https://image.slidesharecdn.com/willmanningmattcheah-191103044612/85/Reliable-Performance-at-Scale-with-Apache-Spark-on-Kubernetes-72-320.jpg)


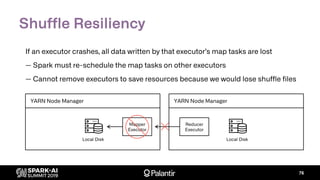
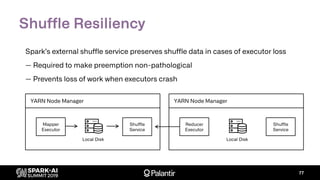
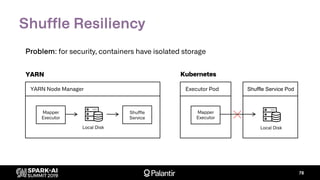
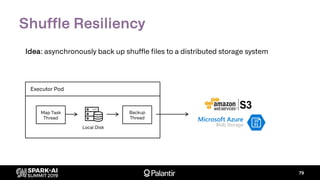
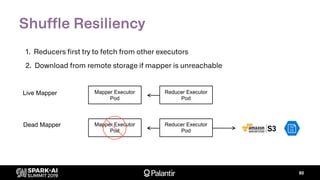





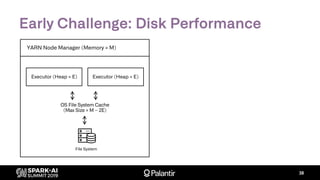
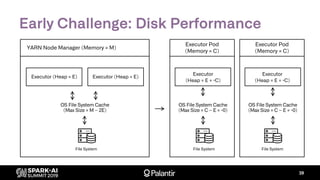
The document discusses Palantir Technologies' transition from using YARN to Kubernetes for managing Spark applications, emphasizing the challenges and technical solutions involved. It highlights performance issues, kubernetes scheduling, and the necessity for reliability and security in multitenant environments while executing user-defined code. Additionally, it outlines how Palantir's infrastructure enables users to perform complex data transformations and analyses securely.












































![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)










































