Download as PDF, PPTX




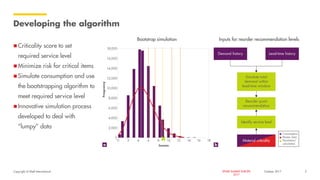
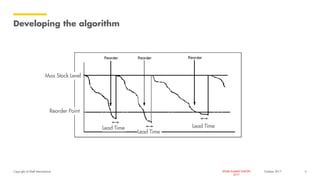


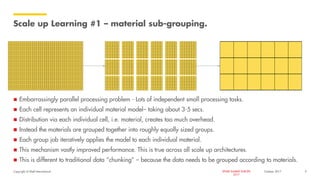
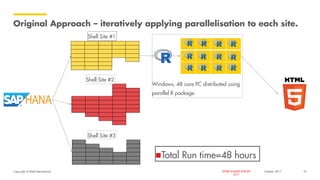




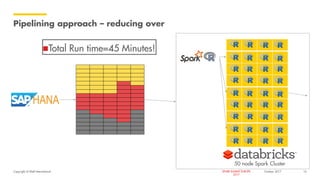
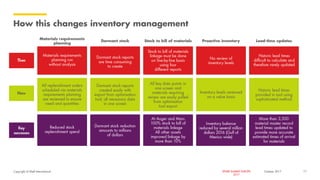




The document outlines Shell's advancements in optimizing spare part inventory through advanced analytics, highlighting challenges in materials management, user confidence, and algorithm development. A pilot project in the Gulf of Mexico demonstrated significant cost savings and efficiency improvements, including reducing simulation times dramatically via upgraded computing methods. The initiative is set to scale globally, with potential for extensive benefits across Shell's operations.









































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













