Distance measures-Euclidean, Manhattan, Hamming, Minkowski Distance Metric,
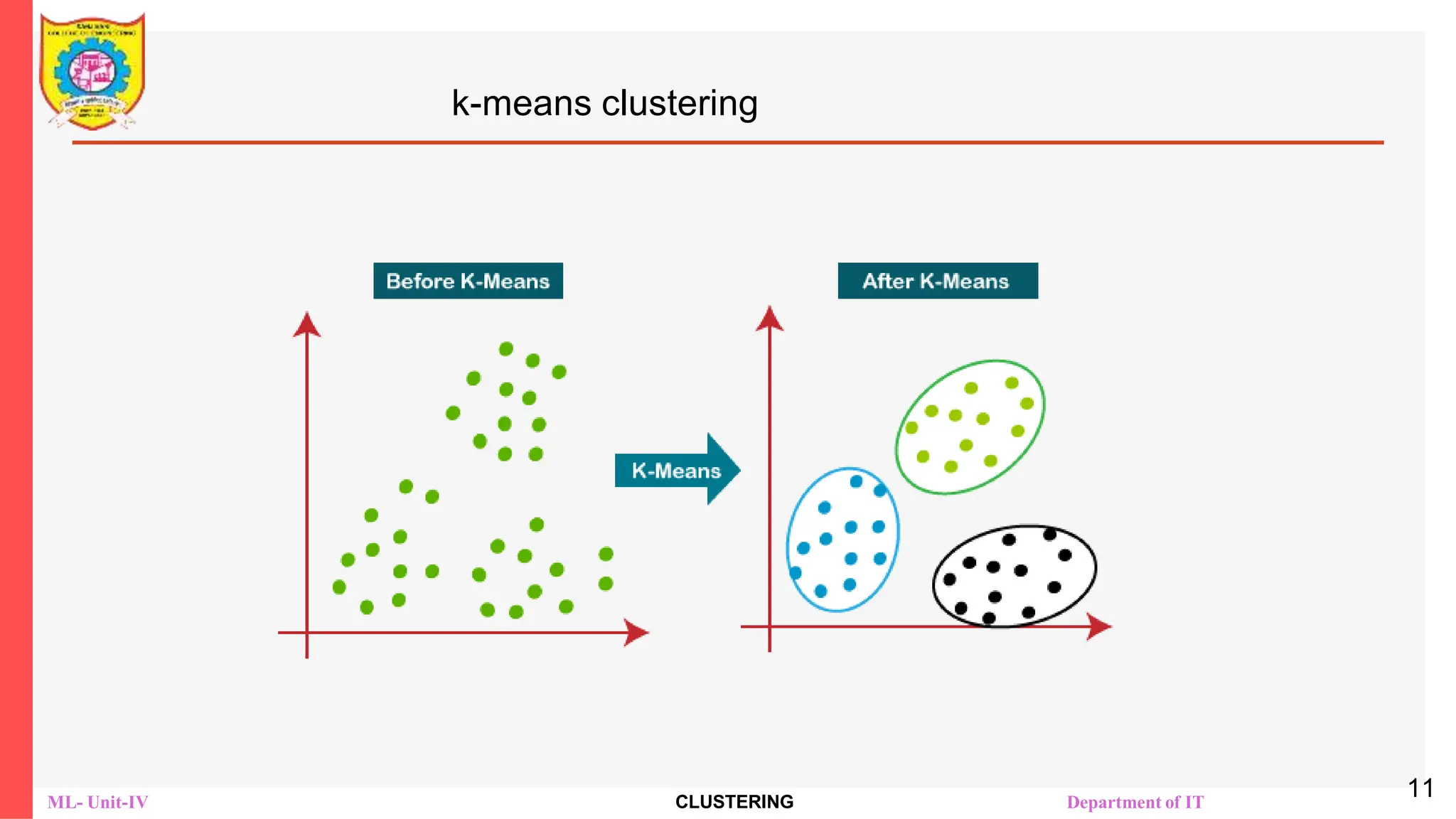
Different clustering methods (Distance, Density, Hierarchical), K-means clustering
Algorithm-with example, k-medoid algorithm-with example, Performance Measures
Rand Index,K-Nearest Neighbour algorithm



![ML- Unit-IV CLUSTERING Department of IT
Unit-IV- CLUSTERING
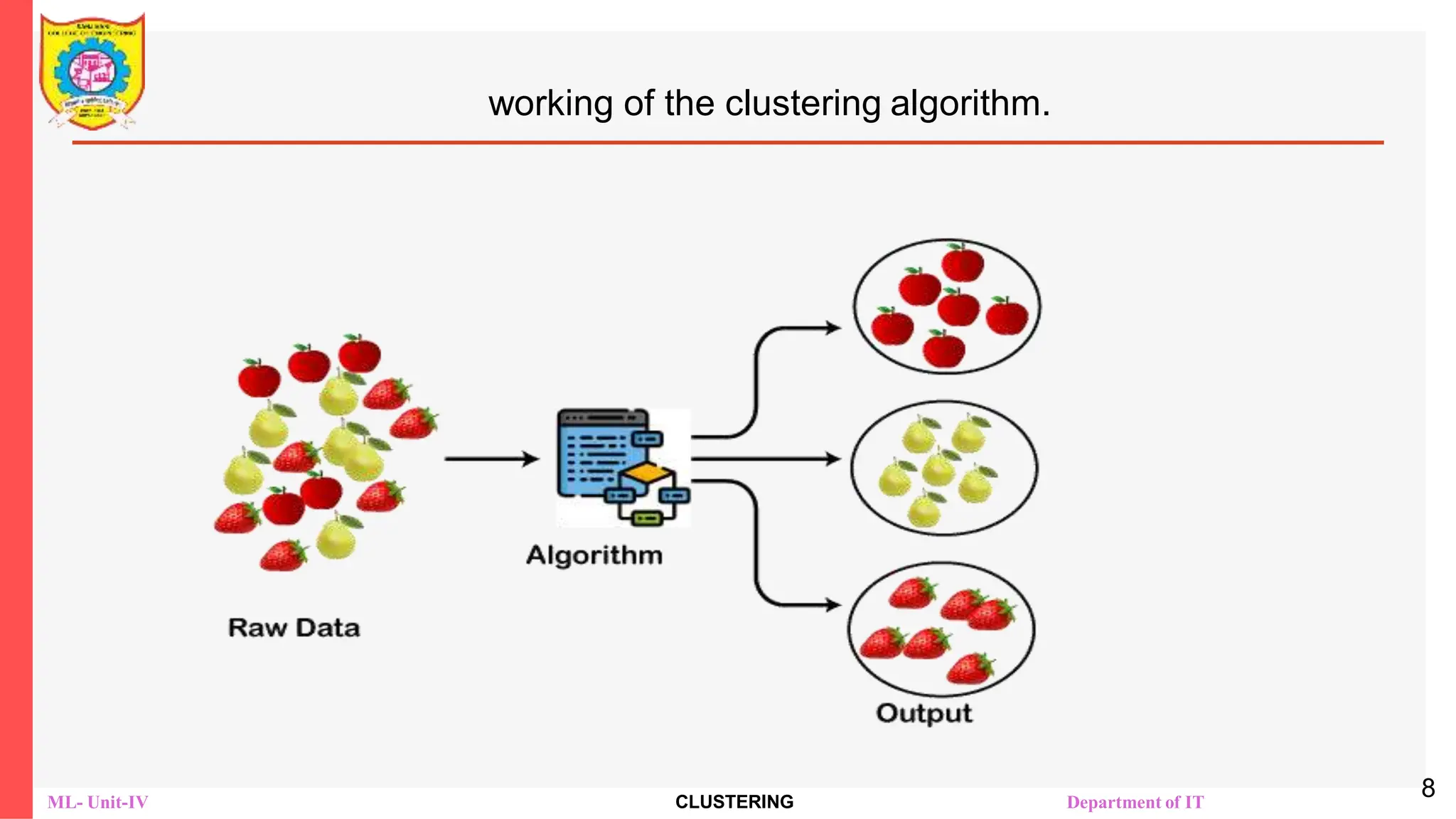
Motivation: Clustering
Grouping similar data points: Cluster analysis allows grouping similar data
samples together, which can help identify patterns and relationships in your
data. e.g., Clustering customers based on their buying behavior.
Identifying outliers: Cluster analysis can help identify outliers in the dataset.
By identifying outliers, the data distribution can be better understood, and
more accurate predictions can be made.
e.g., the height of Dalip Singh Rana (The Great Khali) among the heights of all
the WWE wrestlers in 2017 [2.16m v/s 1.8m*].
4](https://image.slidesharecdn.com/unit4clusteringkmeans-250415053057-100a3b0a/75/Unit4_Clustering-k-means_Clustering-in-ML-pdf-4-2048.jpg)
























![ML- Unit-IV CLUSTERING Department of IT
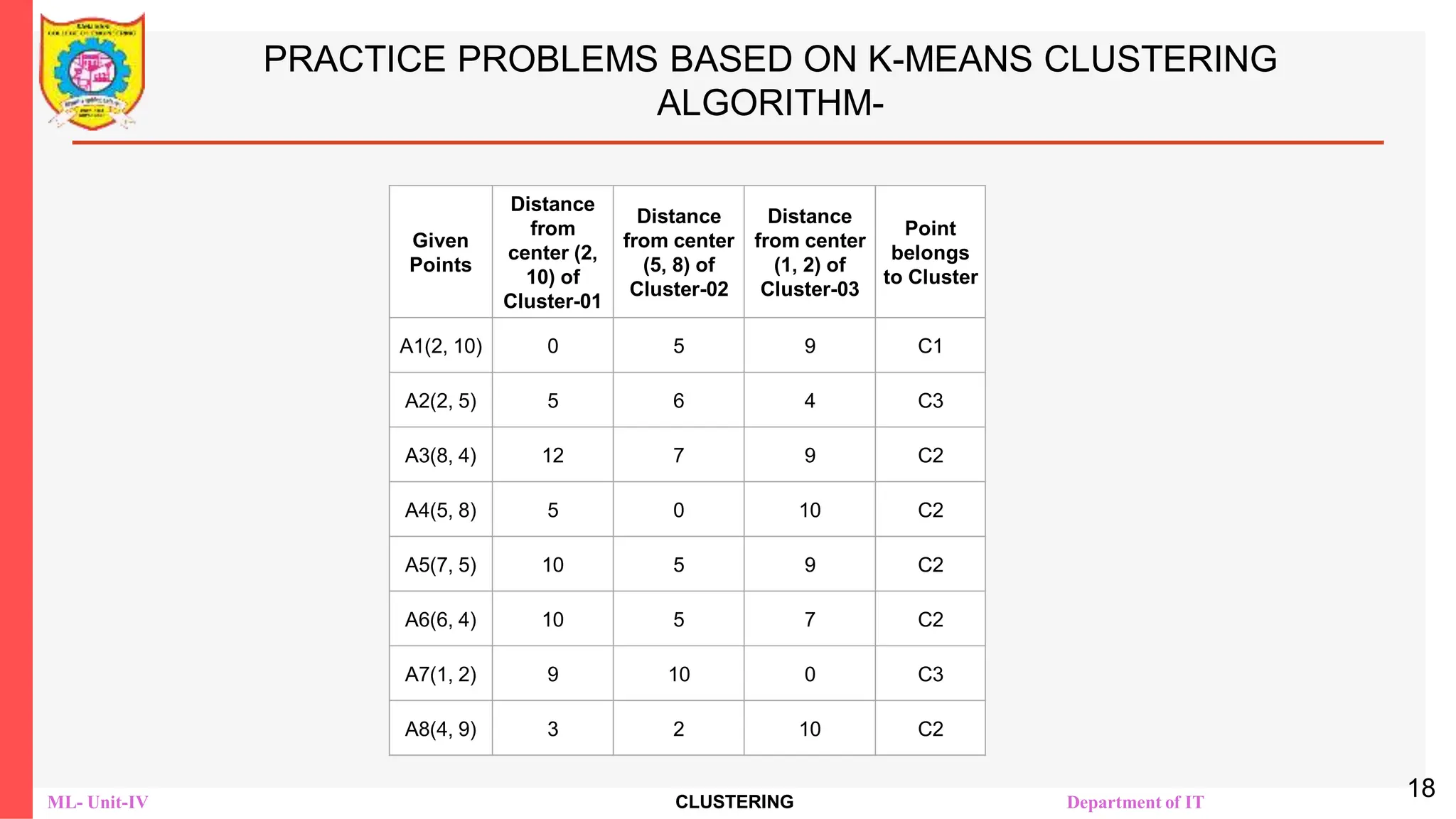
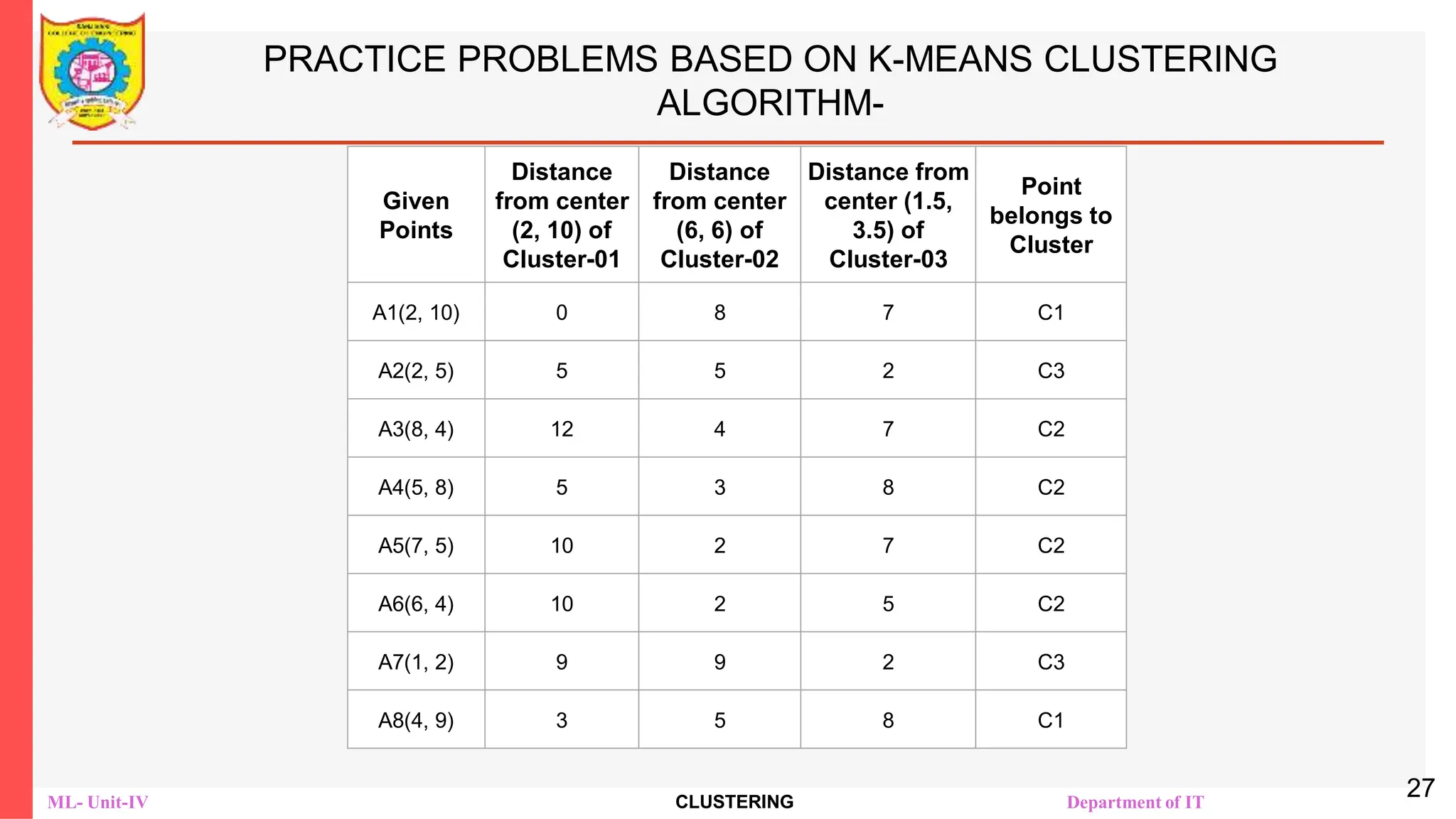
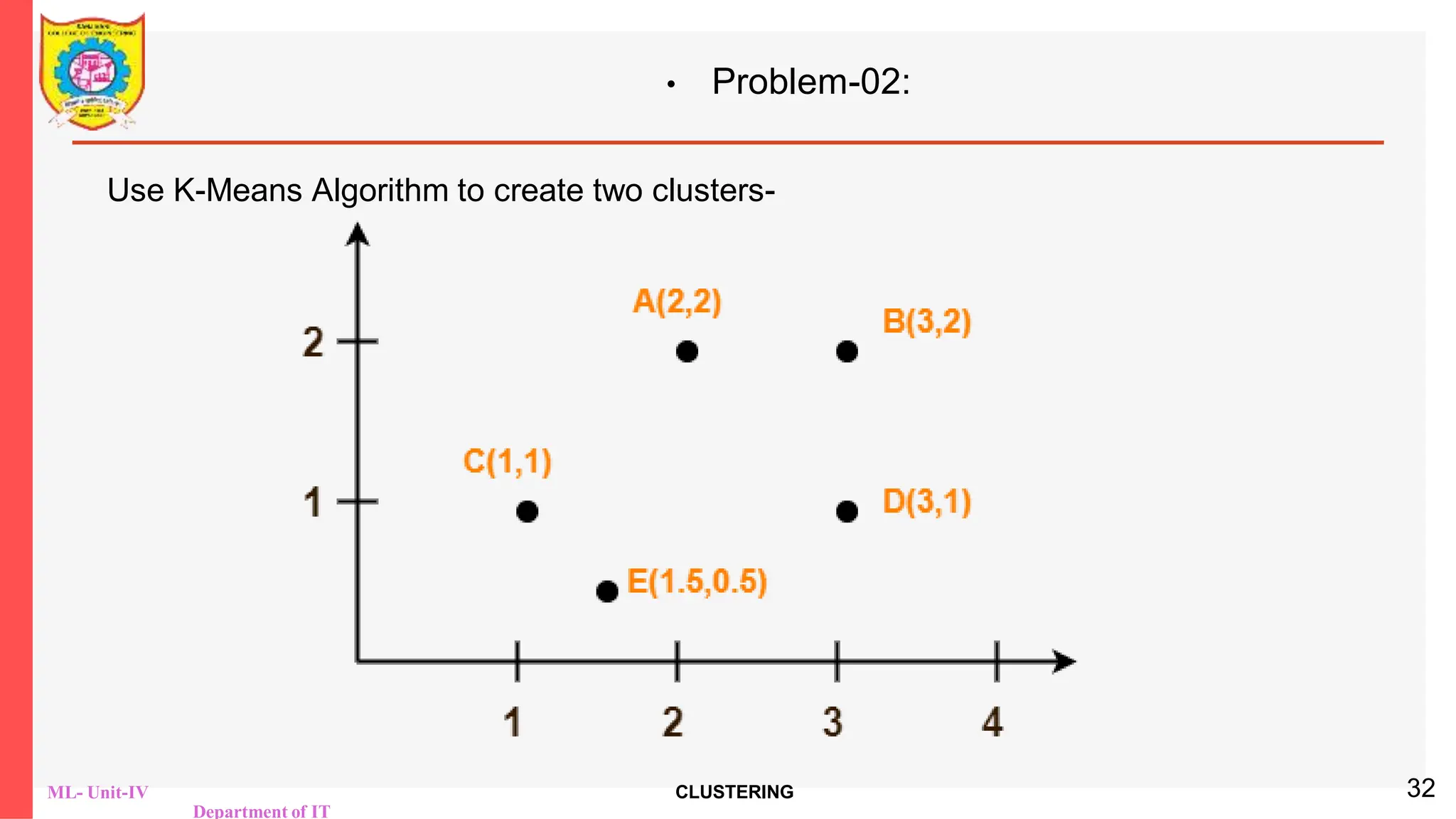
PRACTICE PROBLEMS BASED ON K-MEANS CLUSTERING
ALGORITHM-
The following illustration shows the calculation of distance between
point A(2, 2) and each of the center of the two clusters-
Calculating Distance Between A(2, 2) and C1(2, 2)-
Ρ(A, C1)
= sqrt [ (x2 – x1)2 + (y2 – y1)2 ]
= sqrt [ (2 – 2)2 + (2 – 2)2 ]
= sqrt [ 0 + 0 ]
= 0
34](https://image.slidesharecdn.com/unit4clusteringkmeans-250415053057-100a3b0a/75/Unit4_Clustering-k-means_Clustering-in-ML-pdf-34-2048.jpg)
![ML- Unit-IV CLUSTERING Department of IT
PRACTICE PROBLEMS BASED ON K-MEANS CLUSTERING
ALGORITHM-
Calculating Distance Between A(2, 2) and C2(1, 1)-
Ρ(A, C2)
= sqrt [ (x2 – x1)2 + (y2 – y1)2 ]
= sqrt [ (1 – 2)2 + (1 – 2)2 ]
= sqrt [ 1 + 1 ]
= sqrt [ 2 ]
= 1.41
35](https://image.slidesharecdn.com/unit4clusteringkmeans-250415053057-100a3b0a/75/Unit4_Clustering-k-means_Clustering-in-ML-pdf-35-2048.jpg)

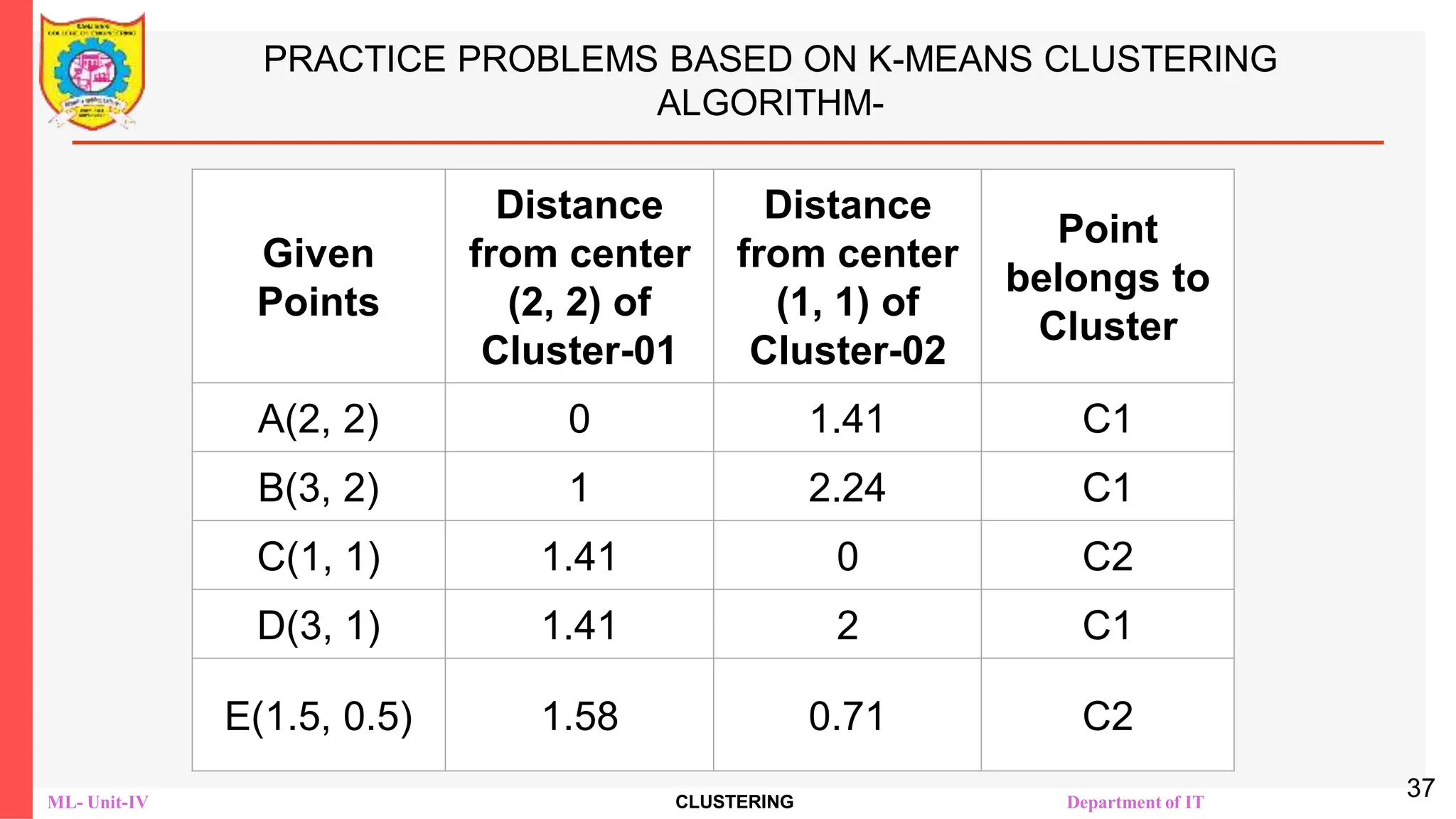




![ML- Unit-IV CLUSTERING Department of IT
PRACTICE PROBLEMS BASED ON K-MEANS CLUSTERING
ALGORITHM-
[MSQ – 3 points] Suppose you have a dataset with the data samples in two-dimensional feature
space. Perform k-means clustering with k=3 and initial cluster centroids at C1 (3, 4), C2 (5,6) and C3
(5, 1). Select the data samples which will be initially assigned to center C3? (1,1)
(1,2)
(2,1)
(2,2)
(3,1)
(6, 1)
(7,2)
(6.5, 0.5)
(4,5)
(4, 6)
(4.5, 5.5)
(5,5)
Data Samples: (1,1), (1,2), (2,1), (2,2), (3,1), (6, 1), (7,2), (6.5, 0.5), (4,5), (4, 6), (4.5, 5.5), (5,5)
42](https://image.slidesharecdn.com/unit4clusteringkmeans-250415053057-100a3b0a/75/Unit4_Clustering-k-means_Clustering-in-ML-pdf-42-2048.jpg)































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)






![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)
















































