Download as PDF, PPTX



![[ESOP 2015]](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-3-320.jpg)





















![[PEPM 2016]](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-28-320.jpg)

![LMR: Language with Modules and Records
prog = decl⇤
decl = module id {decl⇤
}
| import id
| def bind
| record id {fdecl⇤
}
fdecl = id : ty
ty = Int
| Bool
| id
| ty ! ty
exp = int
| true
| false
| id
| exp exp
| if exp then exp else exp
| fun ( id : ty ) {exp}
| exp exp
| letrec tbind in exp
| new id {fbind⇤
}
| with exp do exp
| exp . id
bind = id = exp
| tbind
tbind = id : ty = exp
fbind = id = exp
Figure 5. Syntax of LMR.
[[ds]]prog :=
[[module xi {ds}]]decl
s :=
[[import xi]]decl
s :=
[[def b]]decl
s :=
[[record xi {fs}]]decl
s :=
[[xi = e]]bind
s :=
[[xi : t = e]]bind
s :=
[[xi:t]]fdecl
sr,sd
:=
[[Int]]ty
s,t :=
[[Bool]]ty
s,t :=
[[t1 ! t2]]ty
s,t :=
[[xi]]ty
s,t :=
[[fun (xi:t1){e}]]exp
s,t :=](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-31-320.jpg)
![Constraints for Declarations
p
[[ds]]prog := !D(s) ^ [[ds]]decl⇤
s
[[module xi {ds}]]decl
s := s xD
i ^ xD
i s0 ^ s0 P
s ^ !D(s0) ^ [[ds]]decl⇤
s0
[[import xi]]decl
s := xR
i s ^ s I
xR
i
[[def b]]decl
s := [[b]]bind
s
[[record xi {fs}]]decl
s := s xD
i ^ xD
i s0 ^ s0 P
s ^ !D(s0) ^ [[fs]]fdecl⇤
s,s0
[[xi = e]]bind
s := s xD
i ^ xD
i : ⌧ ^ [[e]]exp
s,⌧
[[xi : t = e]]bind
s := s xD
i ^ xD
i : ⌧ ^ [[t]]ty
s,⌧ ^ [[e]]exp
s,⌧
[[xi:t]]fdecl
sr,sd
:= sd xD
i ^ xD
i : ⌧ ^ [[t]]ty
sr,⌧
[[Int]]ty
s,t := t ⌘ Int
[[Bool]]ty
s,t := t ⌘ Bool
[[t1 ! t2]]ty
s,t := t ⌘ Fun[⌧1,⌧2] ^ [[t1]]ty
s,⌧1 ^ [[t2]]ty
s,⌧2
[[xi]]ty
:= t ⌘ Rec( ) ^ xR
s ^ xR
7!](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-36-320.jpg)
![Constraints for Expressions
LMR.
be the algo-
R’s concrete
defined by a
by syntactic
ach function
nt and possi-
parameters,
sibly involv-
ables or new
s are defined
ach possible
gory. For ex-
rules, and is
e s in which
the expres-
ected type t
the notation
ms of syntac-
result of ap-
and return-
esulting con-
pty sequence.
1 2 s,t 1 2 1 s,⌧1 2 s,⌧2
[[xi]]ty
s,t := t ⌘ Rec( ) ^ xR
i s ^ xR
i 7!
[[fun (xi:t1){e}]]exp
s,t := t ⌘ Fun[⌧1,⌧2] ^ s0 P
s ^ !D(s0) ^ s0 xD
i
^ xD
i : ⌧1 ^ [[t1]]ty
s,⌧1 ^ [[e]]exp
s0,⌧2
[[letrec bs in e]]exp
s,t := s0 P
s ^ !D(s0) ^ [[bs]]bind
s0 ^ [[e]]exp
s0,t
[[n]]exp
s,t := t ⌘ Int
[[true]]exp
s,t := t ⌘ Bool
[[false]]exp
s,t := t ⌘ Bool
[[e1 e2]]exp
s,t := t ⌘ t3 ^ ⌧1 ⌘ t1 ^ ⌧2 ⌘ t2 ^ [[e1]]exp
s,⌧1 ^ [[e2]]exp
s,⌧2
(where has type t1 ⇥ t2 ! t3)
[[if e1 then e2 else e3]]exp
s,t := ⌧1 ⌘ Bool ^ [[e1]]exp
s,⌧1 ^ [[e2]]exp
s,t ^ [[e3]]exp
s,t
[[xi]]exp
s,t := xR
i s ^ xR
i 7! ^ : t
[[e1 e2]]exp
s,t := ⌧ ⌘ Fun[⌧1,t] ^ [[e1]]exp
s,⌧ ^ [[e2]]exp
s,⌧1
[[e.xi]]exp
s,t := [[e]]exp
s,⌧ ^ ⌧ ⌘ Rec( ) ^ & ^ s0 I
& ^ [[xi]]exp
s0,t
[[with e1 do e2]]exp
s,t := [[e1]]exp
s,⌧ ^ ⌧ ⌘ Rec( ) ^ &
^ s0 P
s ^ s0 I
& ^ [[e2]]exp
s0,t
[[new xi {bs}]]exp
s,t := xR
i s ^ xR
i 7! ^ s0 I
xR
i
^ [[bs]]fbind⇤
s,s0 ^ V(s0) ⇡ R(s0) ^ t ⌘ Rec( )
[[xi = e]]fbind
s,s0 := xR
i s0 ^ xR
i 7! ^ : ⌧ ^ [[e]]exp
s,⌧](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-37-320.jpg)

![Constraint Generation
module constraint-gen
imports signatures/-
rules
[[ Constr(t1, ..., tn) ^ (s1, …, sn) : ty ]] :=
C1,
...,
Cn.
one rule per abstract syntax constructor](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-39-320.jpg)
![Generic Constraints
false // always fails
true // always succeeds
C1, C2 // conjunction of constraints
[[ e ^ (s) : ty ]] // generate constraints for sub-term
C | error $[something is wrong] // custom error message
C | warning $[does not look right] // custom warning](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-40-320.jpg)

![Name Set Constraints
distinct D(s)/NS, // declarations for NS in s should be distinct
D(s1) subseteq R(s2), // name set
D(s_rec)/Field subseteq R(s_use)/Field
| error $[Field [NAME] not initialized] @r
Note: incomplete](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-42-320.jpg)
![Type Signature and Type Constraints
signature
types
TC1()
TC2(type)
TC3(scope)
TC4(type, scope, type)
[[ e ^ (s) : ty ]] // subterm e has type ty under scope s
o : ty // occurrence o has type ty
o : ty ! // with priority
ty1 == ty2 // ty1 and ty2 should unify
ty <! ty2 // declare ty1 a subtype of ty2
ty1 <? ty2 // is ty1 a subtype of ty1?](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-43-320.jpg)


![Declaration of Built-in Types and Functions
init ^ (s) : ty_init :=
new s, // the root scope
Type{"int"} <- s, // declare primitive type int
Type{"int"} : INT() !!,
Type{"string"} <- s, // declare primitive type string
Type{"string"} : STRING() !!,
// standard library
Var{"print"} <- s,
Var{"print"} : FUN([STRING()], UNIT()) !!,
…
Var{"exit"} <- s,
Var{"exit"} : FUN([INT()], UNIT()) !!.](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-46-320.jpg)
![module nabl-lib
rules
[[ None() ^ (s) ]] := true.
[[ Some(e) ^ (s) ]] := [[ e ^ (s) ]].
Map[[ [] ^ (s) ]] := true.
Map[[ [ x | xs ] ^ (s) ]] :=
[[ x ^ (s) ]], Map[[ xs ^ (s) ]].
Map2[[ [] ^ (s, s') ]] := true.
Map2[[ [ x | xs ] ^ (s, s') ]] :=
[[ x ^ (s, s') ]], Map2[[ xs ^ (s, s') ]].
MapT2[[ [] ^ (s, s') : [] ]] := true.
MapT2[[ [ x | xs ] ^ (s, s') : [ty | tys] ]] :=
[[ x ^ (s, s') : ty ]], MapT2[[ xs ^ (s, s') : tys ]].
MapT[[ [] ^ (s) : ty ]] := true.
MapT[[ [ x | xs ] ^ (s) : ty ]] :=
[[ x ^ (s) : ty ]], MapT[[ xs ^ (s) : ty ]].
MapTs[[ [] ^ (s) : [] ]] := true.
MapTs[[ [ x | xs ] ^ (s) : [ty | tys] ]] :=
[[ x ^ (s) : ty ]],
MapTs[[ xs ^ (s) : tys ]].
MapTs2[[ [] ^ (s1, s2) : [] ]] := true.
MapTs2[[ [ x | xs ] ^ (s1, s2) : [ty | tys] ]] :=
[[ x ^ (s1, s2) : ty ]], MapTs2[[ xs ^ (s1, s2) : tys ]].
Constraint Generation
for Lists of Terms](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-47-320.jpg)

![Literals and Operators
rules // literals
[[ Int(i) ^ (s) : INT() ]] := true.
[[ String(str) ^ (s) : STRING() ]] := true.
[[ NilExp() ^ (s) : NIL() ]] := true.
rules // operators
[[ Uminus(e) ^ (s) : INT() ]] :=
[[ e ^ (s) : INT() ]].
[[ Divide(e1, e2) ^ (s) : INT() ]] :=
[[ e1 ^ (s) : INT() ]], [[ e2 ^ (s): INT() ]].
[[ Times(e1, e2) ^ (s) : INT() ]] :=
[[ e1 ^ (s) : INT() ]], [[ e2 ^ (s): INT() ]].
// etc.](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-49-320.jpg)
![Assignment
rules
[[ Assign(e1, e2) ^ (s) : UNIT() ]] :=
[[ e1 ^ (s) : ty1 ]],
[[ e2 ^ (s) : ty2 ]],
ty2 <? ty1 | error $[type mismatch] @ e2.](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-50-320.jpg)
![Sequences
rules
[[ Seq(es) ^ (s) : ty ]] :=
Seq[[ es ^ (s) : ty ]].
Seq[[ [] ^ (s) : UNIT() ]] :=
true.
Seq[[ [e] ^ (s) : ty ]] :=
[[ e ^ (s) : ty ]].
Seq[[ [ e | es@[_|_] ] ^ (s) : ty ]] :=
[[ e ^ (s) : ty' ]],
Seq[[ es ^ (s) : ty ]].](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-51-320.jpg)
![Control-Flow
rules
[[ If(e1, e2, e3) ^ (s) : ty2 ]] :=
[[ e1 ^ (s) : INT() ]],
[[ e2 ^ (s) : ty2 ]],
[[ e3 ^ (s) : ty3 ]],
ty2 == ty3 | error $[branches should have same type].
[[ IfThen(e1, e2) ^ (s) : UNIT() ]] :=
[[ e1 ^ (s) : INT() ]],
[[ e2 ^ (s) : ty ]].
[[ While(e1, e2) ^ (s) : UNIT() ]] :=
new s', s' -P-> s,
[[ e1 ^ (s) : INT() ]],
[[ e2 ^ (s') : ty ]].](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-52-320.jpg)

![Lets Bind Sequentially
rules // let
[[ Let(blocks, exps) ^ (s) : ty ]] :=
new s_body,
distinct D(s_body),
Decs[[ blocks ^ (s, s_body) ]],
Seq[[ exps ^ (s_body) : ty ]].
Decs[[ [] ^ (s_outer, s_body) ]] :=
s_body -P-> s_outer.
Decs[[ [block] ^ (s_outer, s_body) ]] :=
s_body -P-> s_outer,
Dec[[ block ^ (s_body, s_outer) ]].
Decs[[ [block | blocks@[_|_]] ^ (s_outer, s_body) ]] :=
new s_dec,
s_dec -P-> s_outer,
Dec[[ block ^ (s_dec, s_outer) ]],
Decs[[ blocks ^ (s_dec, s_body) ]].
let
var x : int := 0 + z // z not in scope
var y : int := x + 1
var z : int := x + y + 1
in
x + y + z
end](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-54-320.jpg)
![Variable Declarations and References
rules // variable declarations
Dec[[ VarDec(x, t, e) ^ (s, s_outer) ]] :=
Var{x} <- s, Var{x} : ty1 !,
[[ t ^ (s_outer) : ty1 ]],
[[ e ^ (s_outer) : ty2 ]],
ty2 <? ty1 | error $[type mismatch] @ e.
Dec[[ VarDecNoInit(x, t) ^ (s, s_outer) ]] :=
Var{x} <- s, Var{x} : ty !,
[[ t ^ (s_outer) : ty ]].
rules // variable references
[[ Var(x) ^ (s) : ty ]] :=
Var{x} -> s,
Var{x} |-> d,
d : ty.
let
var x : int := 5
var f : int := 1
in
for y := 1 to x do (
f := f * y
)
end](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-55-320.jpg)
![Type Declarations
let
type foo = int
function foo(x : foo) : foo = 3
var foo : foo := foo(4)
in foo(56) + foo // both refer to the variable foo
end
rules
Dec[[ TypeDecs(tdecs) ^ (s, s_outer) ]] :=
Map[[ tdecs ^ (s) ]].
[[ TypeDec(x, t) ^ (s) ]] :=
Type{x} <- s, Type{x} : ty !,
[[ t ^ (s) : ty ]].
rules // types
[[ Tid(x) ^ (s) : ty ]] :=
Type{x} -> s,
Type{x} |-> d | error $[Type [x] not declared],
d : ty.](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-56-320.jpg)


![Function Definitions
rules
Dec[[ FunDecs(fdecs) ^ (s, s_outer) ]] :=
Map2[[ fdecs ^ (s, s_outer) ]].
[[ FunDec(f, args, t, e) ^ (s, s_outer) ]] :=
Var{f} <- s,
Var{f} : FUN(tys, ty) !,
new s_fun,
s_fun -P-> s,
distinct D(s_fun) | error $[duplicate argument] @ NAMES,
MapTs2[[ args ^ (s_fun, s_outer) : tys ]],
[[ t ^ (s_outer) : ty ]],
[[ e ^ (s_fun) : ty_body ]],
ty == ty_body| error $[return type does not match body] @ t.
[[ FArg(x, t) ^ (s_fun, s_outer) : ty ]] :=
Var{x} <- s_fun,
Var{x} : ty !,
[[ t ^ (s_outer) : ty ]].
let function fact(n : int) : int =
if n < 1 then 1 else (n * fact(n - 1))
in fact(10)
end](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-59-320.jpg)
![let function fact(n : int) : int =
if n < 1 then 1 else (n * fact(n - 1))
in fact(10)
end
Function Calls
rules
[[ Call(Var(f), exps) ^ (s) : ty ]] :=
Var{f} -> s,
Var{f} |-> d | error $[Function [f] not declared],
d : FUN(tys, ty) | error $[Function expected] ,
MapTs[[ exps ^ (s) : tys ]].](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-60-320.jpg)




![Record Types
rules
[[ RecordTy(fields) ^ (s) : ty ]] :=
new s_rec,
ty == RECORD(s_rec),
NIL() <! ty,
distinct D(s_rec)/Field
| error $[Duplicate declaration of field [NAME]] @ NAMES,
Map2[[ fields ^ (s_rec, s) ]].
[[ Field(x, t) ^ (s_rec, s_outer) ]] :=
Field{x} <- s_rec,
Field{x} : ty !,
[[ t ^ (s_outer) : ty ]].
let
type point = {x : int, y : int}
var origin : point := point { x = 1, y = 2 }
in origin.x
end](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-66-320.jpg)
![Record Creation
rules
[[ r@Record(t, inits) ^ (s) : ty ]] :=
[[ t ^ (s) : ty ]],
ty == RECORD(s_rec) | error $[record type expected],
new s_use, s_use -I-> s_rec,
D(s_rec)/Field subseteq R(s_use)/Field
| error $[Field [NAME] not initialized] @r,
Map2[[ inits ^ (s_use, s) ]].
[[ InitField(x, e) ^ (s_use, s) ]] :=
Field{x} -> s_use,
Field{x} |-> d,
d : ty1,
[[ e ^ (s) : ty2 ]],
ty2 <? ty1 | error $[type mismatch].
let
type point = {x : int, y : int}
var origin : point := point { x = 1, y = 2 }
in origin.x
end](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-67-320.jpg)
![Record Field Access
rules
[[ FieldVar(e, f) ^ (s) : ty ]] :=
[[ e ^ (s) : ty_e ]],
ty_e == RECORD(s_rec),
new s_use, s_use -I-> s_rec,
Field{f} -> s_use,
Field{f} |-> d,
d : ty.
let
type point = {x : int, y : int}
var origin : point := point { x = 1, y = 2 }
in origin.x
end](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-68-320.jpg)



![Resolution Calculus with Edge Labels
s the resolution relation for graph G.
collection JNKG is the multiset defined
DG(S)), JR(S)KG = ⇡(RG(S)), and
`G p : S 7 ! xD
i }) where ⇡(A) is
ojecting the identifiers from a set A of
iven a multiset M, 1M (x) denotes the
nes the resolution of a reference to a
as a most specific, well-formed path
n through a sequence of edges. A path
ng the atomic scope transitions in the
of steps:
l, S2) is a direct transition from the
pe S2. This step records the label of
s used.
, yR
, S) requires the resolution of ref-
n with associated scope S to allow a
rrent scope and scope S.
nds with a declaration step D(xD
) that
path is leading to.
ion in the graph from reference xR
i
`G p : xR
i 7 ! xD
i according to
. These rules all implicitly apply to
omit to avoid clutter. The calculus
n in terms of edges in the scope graph,
isible declarations. Here I is the set of
vice needed to avoid “out of thin air”
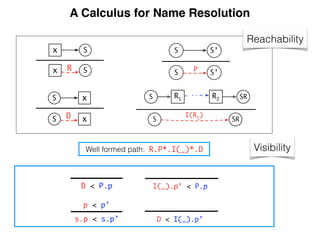
Well-formed paths
WF(p) , labels(p) 2 E
Visibility ordering on paths
label(s1) < label(s2)
s1 · p1 < s2 · p2
p1 < p2
s · p1 < s · p2
Edges in scope graph
S1
l
S2
I ` E(l, S2) : S1 ! S2
(E)
S1
l
yR
i yR
i /2 I I ` p : yR
i 7 ! yD
j yD
j S2
I ` N(l, yR
i , S2) : S1 ! S2
(N)
Transitive closure
I, S ` [] : A ⇣ A
(I)
B /2 S I ` s : A ! B I, {B} [ S ` p : B ⇣ C
I, S ` s · p : A ⇣ C
(T)
Reachable declarations
I, {S} ` p : S ⇣ S0
WF(p) S0
xD
i
I ` p · D(xD
i ) : S ⇢ xD
i
(R)
Visible declarations
I ` p : S ⇢ xD
i
8j, p0
(I ` p0
: S ⇢ xD
j ) ¬(p0
< p))
I ` p : S 7 ! xD
i
(V )
Reference resolution
xR
i S {xR
i } [ I ` p : S 7 ! xD
j
I ` p : xR
i 7 ! xD
j
(X)
G, |= !N
JN1KG ✓ JN2KG
G, |= N1
⇢
⇠ N2
(C-SUBNAME)
t1 = t2
G, |= t1 ⌘ t2
(C-EQ)
Figure 8. Interpretation of resolution and typing constraints
Resolution paths
s := D(xD
i ) | E(l, S) | N(l, xR
i , S)
p := [] | s | p · p (inductively generated)
[] · p = p · [] = p
(p1 · p2) · p3 = p1 · (p2 · p3)
Well-formed paths
WF(p) , labels(p) 2 E
Visibility ordering on paths
label(s1) < label(s2)
s1 · p1 < s2 · p2
p1 < p2
s · p1 < s · p2
Edges in scope graph
S1
l
S2
I ` E(l, S2) : S1 ! S2
(E)
S1
l
yR
i yR
i /2 I I ` p : yR
i 7 ! yD
j yD
j S2
I ` N(l, yR
i , S2) : S1 ! S2
(N)
Transitive closure
I, S ` [] : A ⇣ A
(I)
B /2 S I ` s : A ! B I, {B} [ S ` p : B ⇣ C
I, S ` s · p : A ⇣ C
(T)
Reachable declarations
I, {S} ` p : S ⇣ S0
WF(p) S0
xD
i
I ` p · D(xD
i ) : S ⇢ xD
i
(R)
Visible declarations
I ` p : S ⇢ xD
i
8j, p0
(I ` p0
: S ⇢ xD
j ) ¬(p0
< p))
I ` p : S 7 ! xD
i
(V )
Reference resolution
xR
S {xR
} [ I ` p : S 7 ! xD
C := CG
| CTy | CRes | C ^ C | True
CG
:= R S | S D | S l
S | D S | S l
R
CRes := R 7! D | D S | !N | N ⇢
⇠ N
CTy := T ⌘ T | D : T
D := | xD
i
R := xR
i
S := & | n
T := ⌧ | c(T, ..., T) with c 2 CT
N := D(S) | R(S) | V(S)
Figure 7. Syntax of constraints
scope graph resolution calculus (described in Section 3.3). Finally,
we apply |= with G set to CG
.
To lift this approach to constraints with variables, we simply
apply a multi-sorted substitution , mapping type variables ⌧ to
ground types, declaration variables to ground declarations and
scope variables & to ground scopes. Thus, our overall definition of
satisfaction for a program p is:
(CG
), |= (CRes
) ^ (CTy
) (⇧)](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-72-320.jpg)


 := let (r, s) = EnvE [{xR
} [ I, ;](Sc(xR
))} in
(
U if r = P and {xD
|xD
2 s} = ;
{xD
|xD
2 s}
Envre [I, S](S) :=
(
(T, ;) if S 2 S or re = ?
Env
L[{D}
re [I, S](S)
EnvL
re [I, S](S) :=
[
l2Max(L)
⇣
Env
{l0
2L|l0
<l}
re [I, S](S) Envl
re [I, S](S)
⌘
EnvD
re [I, S](S) :=
(
(T, ;) if [] /2 re
(T, D(S))
Envl
re [I, S](S) :=
8
><
>:
(P, ;) if S
I
l contains a variable or ISl[I](S) = U
S
S02
⇣
ISl[I](S)[S
I
l
⌘
Env(l 1re)[I, {S} [ S](S0)
ISl
[I](S) :=
(
U if 9yR
2 (S
B
l I) s.t. R[I](yR
) = U
{S0 | yR
2 (S
B
l I) ^ yD
2 R[I](yR
) ^ yD
S0}](https://image.slidesharecdn.com/typeanalysis-161019115633/85/Type-analysis-76-320.jpg)










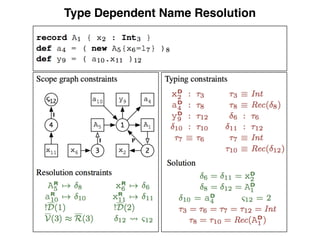
This document discusses type-dependent name resolution in programming languages. It notes that sometimes type information is needed before name resolution can be performed, such as when resolving names in records where the record fields depend on the types. It gives an example where a program defines two records A and B, with B containing a field of type A, and names must be resolved through the record types. The document suggests that name resolution and type checking/inference can often be done in either order for languages, but type information is sometimes necessary for resolving some names.





























































































