Download as PDF, PPTX







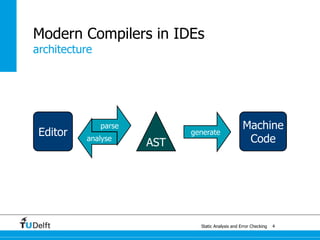





















![class Main {
!
public static void main(String[] args) {
System.out.println(new Fac().fac(10));
}
}
!
class Fac {
!
public int fac(int num) {
int num_aux;
if (num < 1)
num_aux = 1;
else
num_aux = num * this.fac(num - 1);
return num_aux;
}
}
Static Analysis and Error Checking 13](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-29-320.jpg)



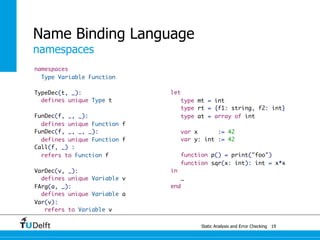





![Tiger
type system
E ⊢ e1 : array of t
E ⊢ e2 : int
E ⊢ e1[e2] : t
Static Analysis and Error Checking 18
E ⊢ e1 : int
E ⊢ e2 : int
E ⊢ e1 + e2 : int
E ⊢ e1 : int
E ⊢ e2 : int
E ⊢ e1 < e2 : int
E ⊢ e1 : string
E ⊢ e2 : string
E ⊢ e1 < e2 : int](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-39-320.jpg)






![Static Analysis and Error Checking 26
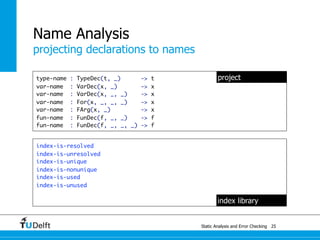
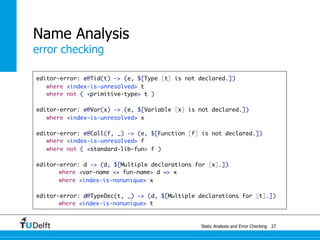
test outer name [[
let type t = u
Testing
name binding
type [[u]] = int
var x: [[u]] := 0
in
x := 42 ;
let type u = t
var y: u := 0
in
y := 42
end
end
]] resolve #2 to #1
test inner name [[
let type t = u
type u = int
var x: u := 0
in
x := 42 ;
let type [[u]] = t
var y: [[u]] := 0
in
y := 42
end
end
]] resolve #2 to #1](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-51-320.jpg)
![Static Analysis and Error Checking 27
test integer constant [[
let type t = u
type u = int
var x: u := 0
in
x := 42 ;
let type u = t
var y: u := 0
in
y := [[42]]
end
Testing
type system
end
]] run get-type to IntTy()
test variable reference [[
let type t = u
type u = int
var x: u := 0
in
x := 42 ;
let type u = t
var y: u := 0
in
y := [[x]]
end
end
]] run get-type to IntTy()](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-52-320.jpg)
![Static Analysis and Error Checking 28
Testing
constraints
test undefined variable [[
let type t = u
type u = int
var x: u := 0
in
x := 42 ;
let type u = t
var y: u := 0
in
y := [[z]]
end
end
]] 1 error
test type error [[
let type t = u
type u = string
var x: u := 0
in
x := 42 ;
let type u = t
var y: u := 0
in
y := [[x]]
end
end
]] 1 error](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-53-320.jpg)
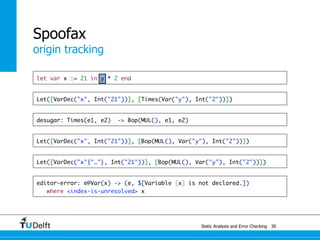
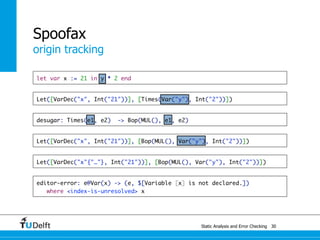
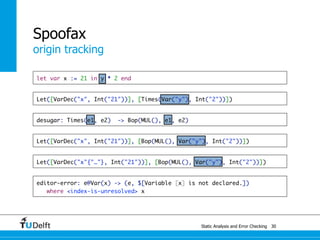
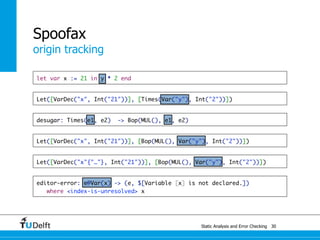
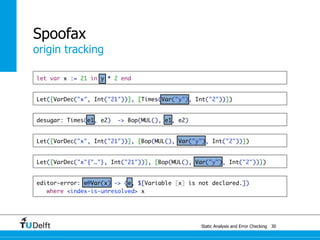





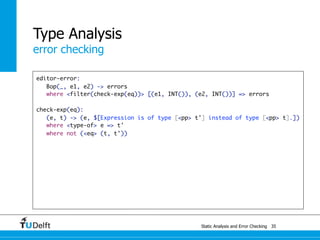


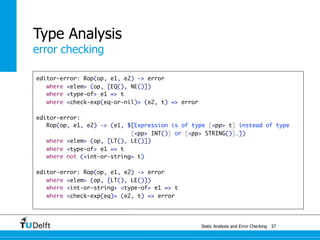

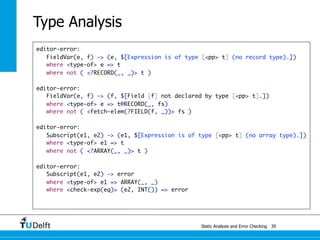


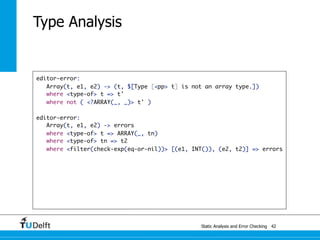


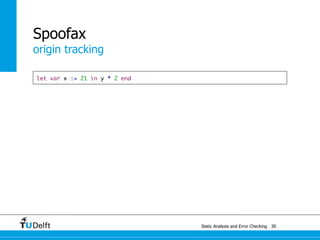
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-78-320.jpg)
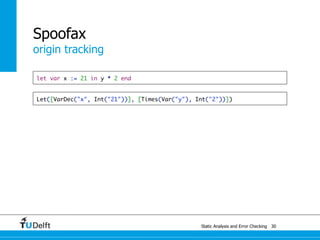
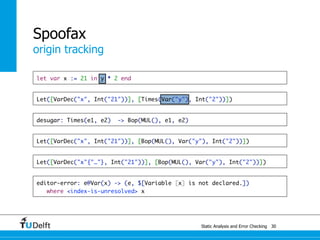
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-79-320.jpg)
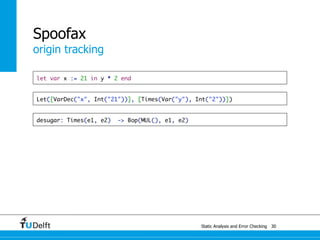
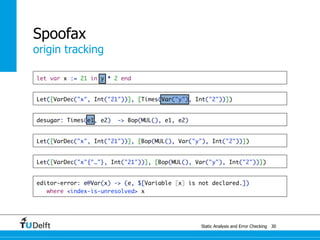
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-80-320.jpg)
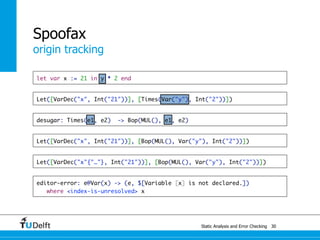
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-81-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-82-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-83-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-84-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-85-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-86-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-87-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-88-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-89-320.jpg)
![Static Analysis and Error Che4c8king 48
Spoofax
origin tracking
let var x := 21 in y * 2 end
Let([VarDec("x", Int("21"))], [Times(Var("y"), Int("2"))])
desugar: Times(e1, e2) -> Bop(MUL(), e1, e2)
Let([VarDec("x", Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Let([VarDec("x"{"…"}, Int("21"))], [Bop(MUL(), Var("y"), Int("2"))])
Var(x): ty
where definition of x: ty
else error "…" on x](https://image.slidesharecdn.com/cc-analysis-100915062336-phpapp02/85/Declarative-Semantics-Definition-Static-Analysis-and-Error-Checking-90-320.jpg)







The document discusses static analysis and error checking in compiler construction. It covers several key topics: - The static analysis process of parsing source code, checking for errors, and generating machine code. - Name analysis, binding, and scoping during static checking and for editor services like refactoring and code generation. - Testing static semantics including name binding, type systems, and constraints. - Restricting context-free languages using static semantics and judgements of well-formedness and well-typedness. - Formal type systems including those for Tiger language examples involving types, expressions, and scoping.