Bloom filters are a space-efficient probabilistic data structure for representing a set in order to support membership queries. They allow for false positives but not false negatives. The document discusses how bloom filters work using hash functions to set bits in a bit vector, allowing for fast set membership checks. It also covers extensions like counting bloom filters that can support deletions by incrementing and decrementing counters, and variations like distance-sensitive bloom filters and bloomier filters.



![Web Caching
• Summary Cache: [Fan, Cao, Almeida, & Broder]
If local caches know each other’s content...
…try local cache before going out to Web
• Sending/updating lists of URLs too expensive.
• Solution: use Bloom filters.
• False positives
– Local requests go unfulfilled.
– Small cost, big potential gain](https://image.slidesharecdn.com/tutorial9bloomfilters-130928092003-phpapp02/75/Tutorial-9-bloom-filters-4-2048.jpg)

![Bloom Filters
Start with an m bit array, filled with 0s.
Hash each item xj in S k times. If Hi(xj) = a, set B[a] = 1.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0B
0 1 0 0 1 0 1 0 0 1 1 1 0 1 1 0B
To check if y is in S, check B at Hi(y). All k values must be 1.
0 1 0 0 1 0 1 0 0 1 1 1 0 1 1 0B
0 1 0 0 1 0 1 0 0 1 1 1 0 1 1 0B
Possible to have a false positive; all k values are 1, but y is not in S.](https://image.slidesharecdn.com/tutorial9bloomfilters-130928092003-phpapp02/75/Tutorial-9-bloom-filters-6-2048.jpg)
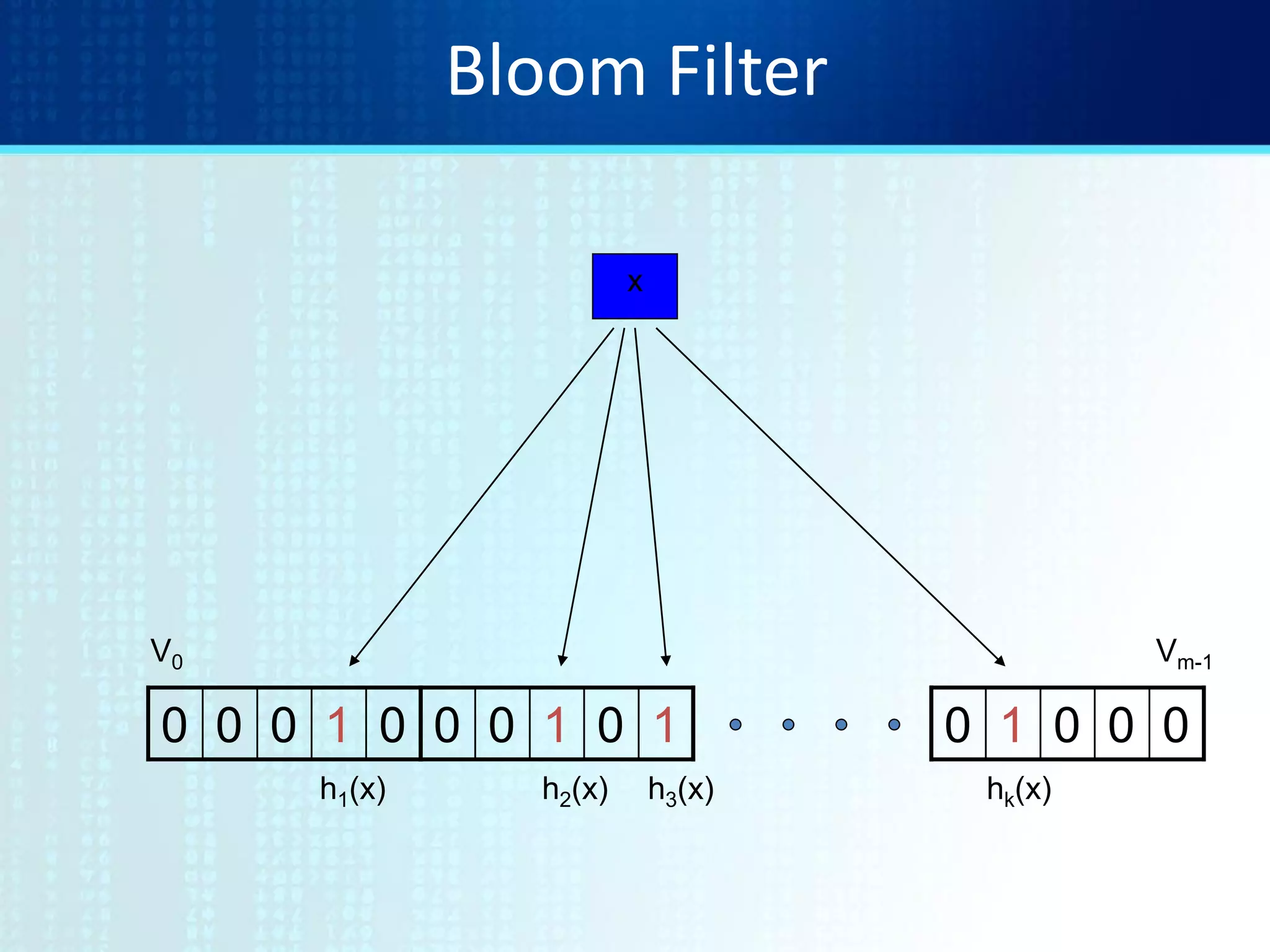


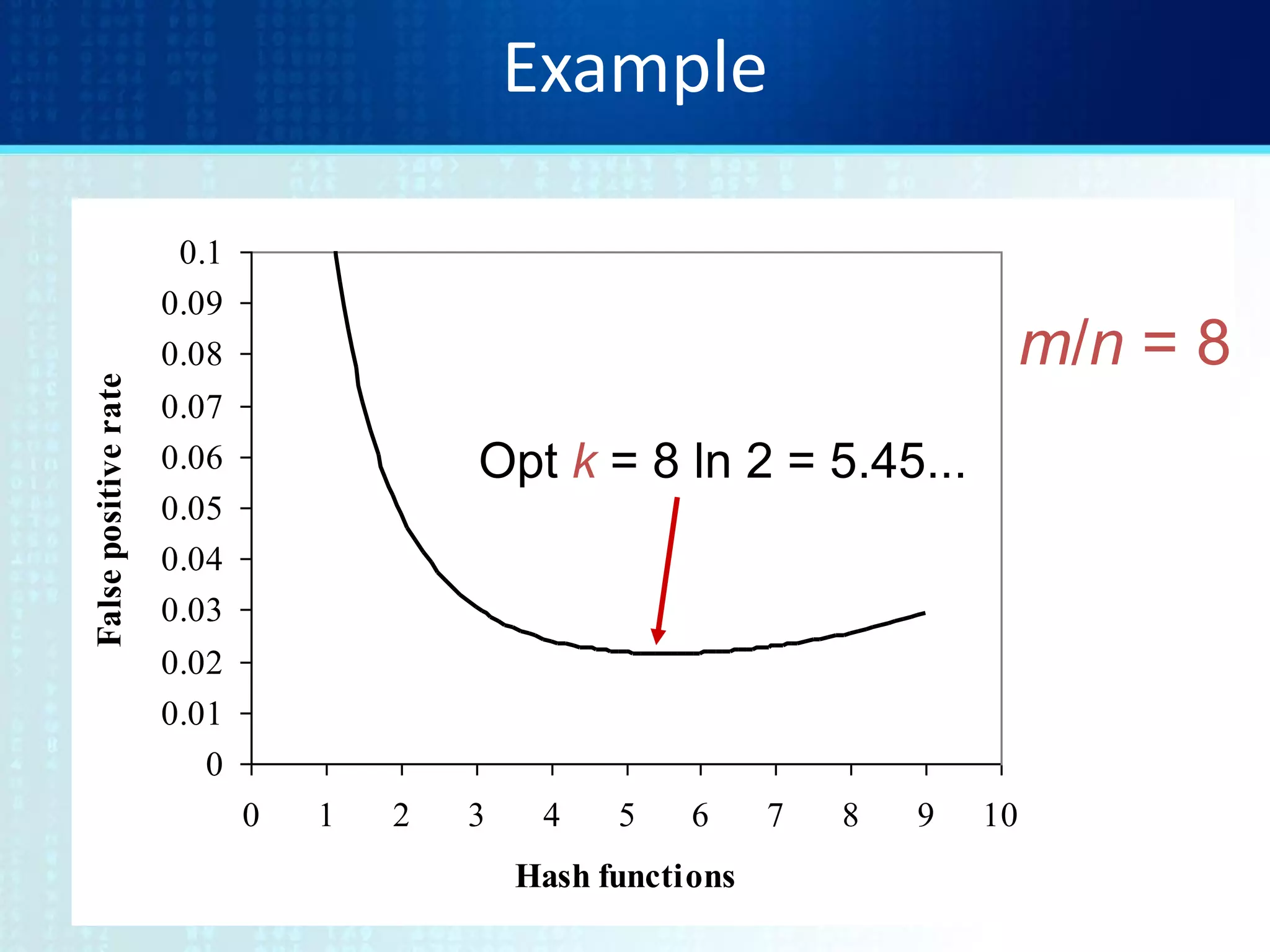
![Tradeoffs
• Three parameters.
– Size m/n : bits per item.
• |U| = n: Number of elements to encode.
• hi: U[1..m] : Maintain a Bit Vector V of size m
– Time k : number of hash functions.
• Use k hash functions (h1..hk)
– Error f : false positive probability.](https://image.slidesharecdn.com/tutorial9bloomfilters-130928092003-phpapp02/75/Tutorial-9-bloom-filters-11-2048.jpg)





![Counting Bloom Filters
Start with an m bit array, filled with 0s.
Hash each item xj in S k times. If Hi(xj) = a, add 1 to B[a].
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0B
0 3 0 0 1 0 2 0 0 3 2 1 0 2 1 0B
To delete xj decrement the corresponding counters.
0 2 0 0 0 0 2 0 0 3 2 1 0 1 1 0B
Can obtain a corresponding Bloom filter by reducing to 0/1.
0 1 0 0 0 0 1 0 0 1 1 1 0 1 1 0B](https://image.slidesharecdn.com/tutorial9bloomfilters-130928092003-phpapp02/75/Tutorial-9-bloom-filters-17-2048.jpg)


![Extension: Distance-Sensitive Bloom Filters
• Instead of answering questions of the form
we would like to answer questions of the form
• That is, is the query close to some element of the set, under
some metric and some notion of close.
• Applications:
– DNA matching
– Virus/worm matching
– Databases
• Some initial results [KirschMitzenmacher]. Hard.
.SyIs
.SxyIs ](https://image.slidesharecdn.com/tutorial9bloomfilters-130928092003-phpapp02/75/Tutorial-9-bloom-filters-20-2048.jpg)
![Extension: Bloomier Filter
• Bloom filters handle set membership.
• Counters to handle multi-set/count tracking.
• Bloomier filter [Chazelle, Kilian, Rubinfeld, Tal]:
– Extend to handle approximate functions.
– Each element of set has associated function value.
– Non-set elements should return null.
– Want to always return correct function value for set
elements.
– A false positive returns a function value for a non-null
element.](https://image.slidesharecdn.com/tutorial9bloomfilters-130928092003-phpapp02/75/Tutorial-9-bloom-filters-21-2048.jpg)















































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



