Downloaded 225 times








![IsMember(Table,Key)
1. i=0
2. Repeat
3. i=i+1
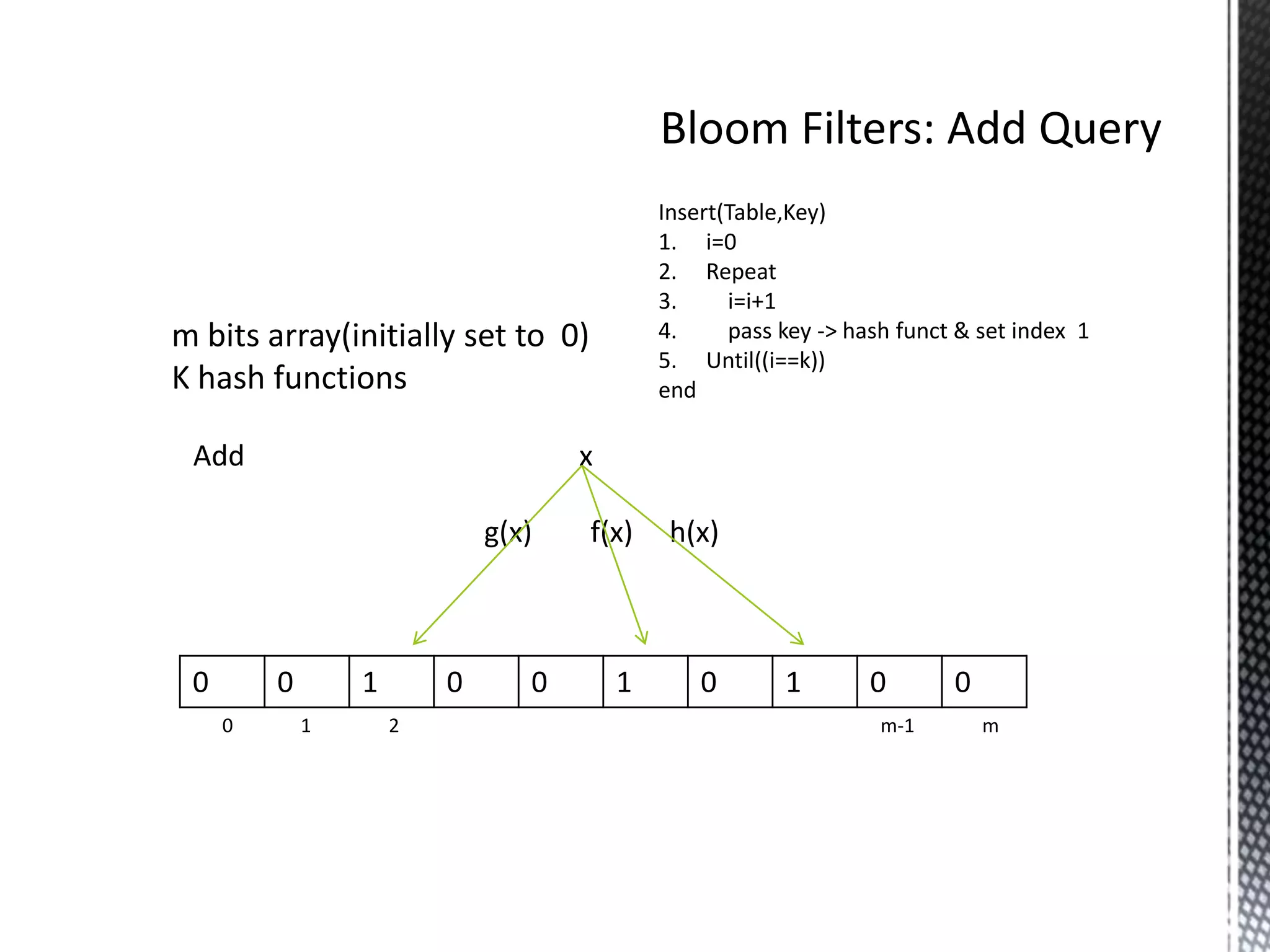
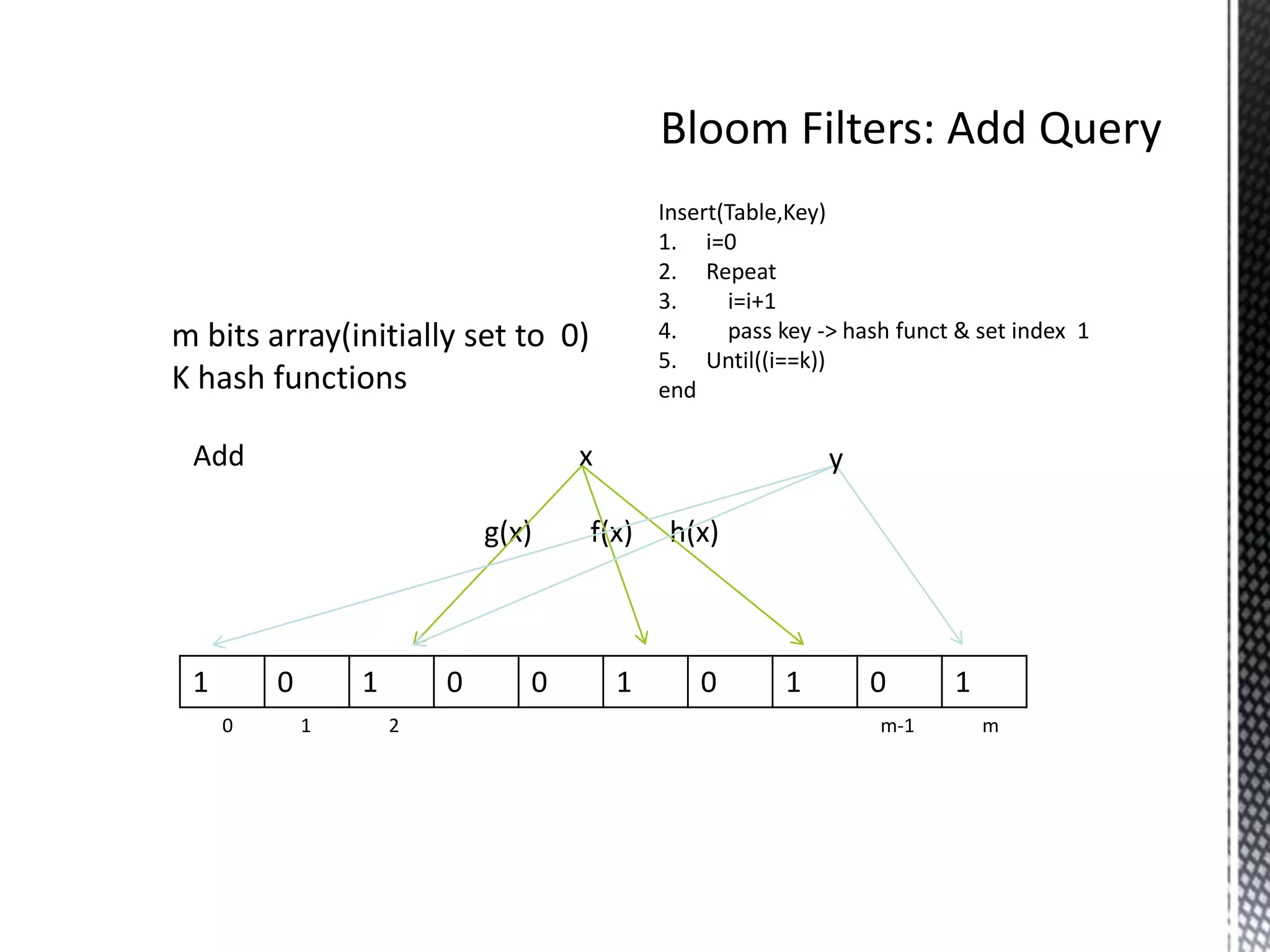
m bits array(initially set to 0) 4. hi is the ith hash funct
K hash functions 5. until((i=k) Or(IsSet(Table[hi(key)])))
6. if(i=k) then
7. return true
8. Else
9. return false
end
1 0 1 0 0 1 0 1 0 1
0 1 2 m-1 m
Search y
It return true as y is there in set S](https://image.slidesharecdn.com/bloomfilters-130409222908-phpapp01/75/Bloom-filters-11-2048.jpg)



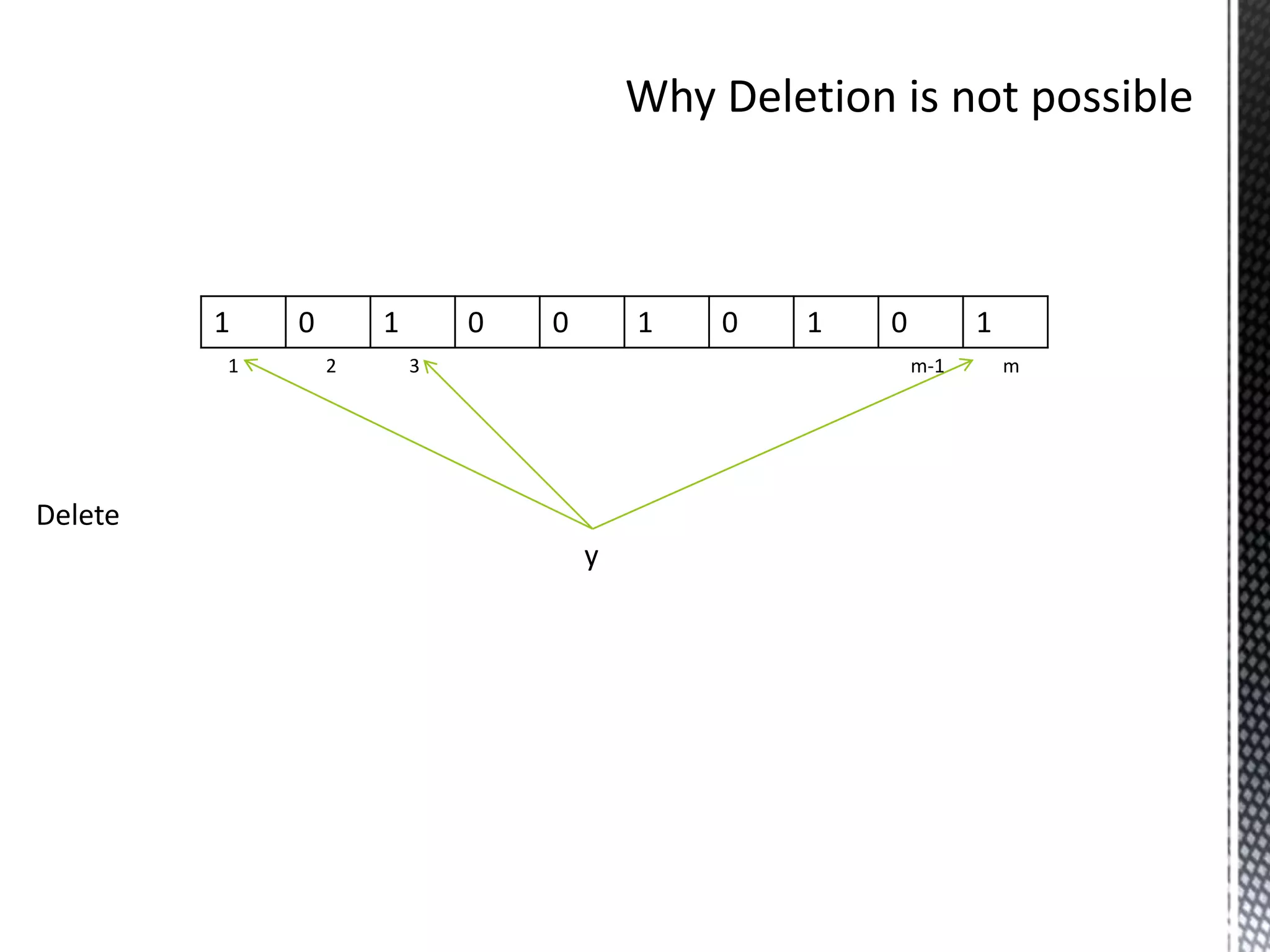
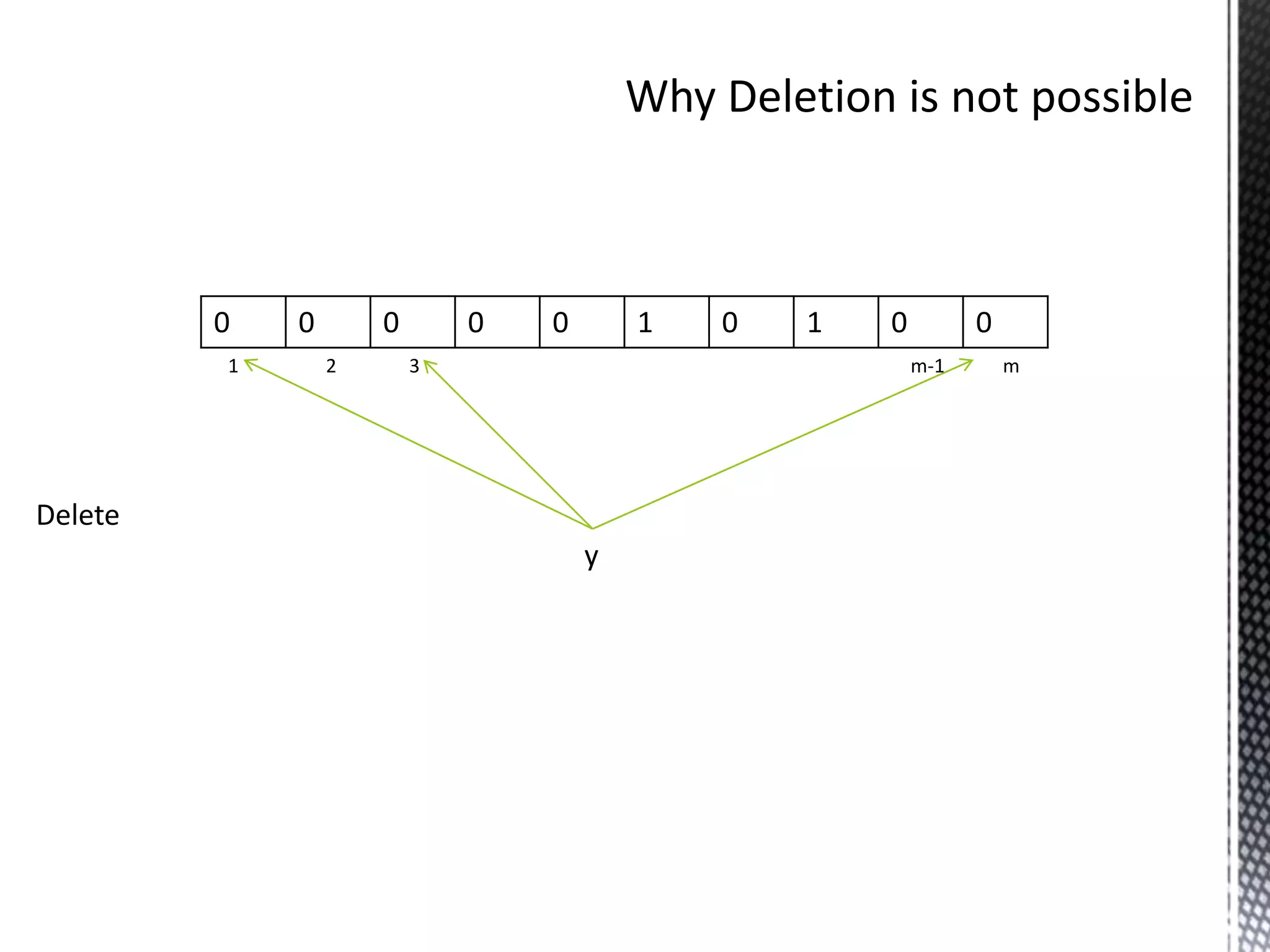

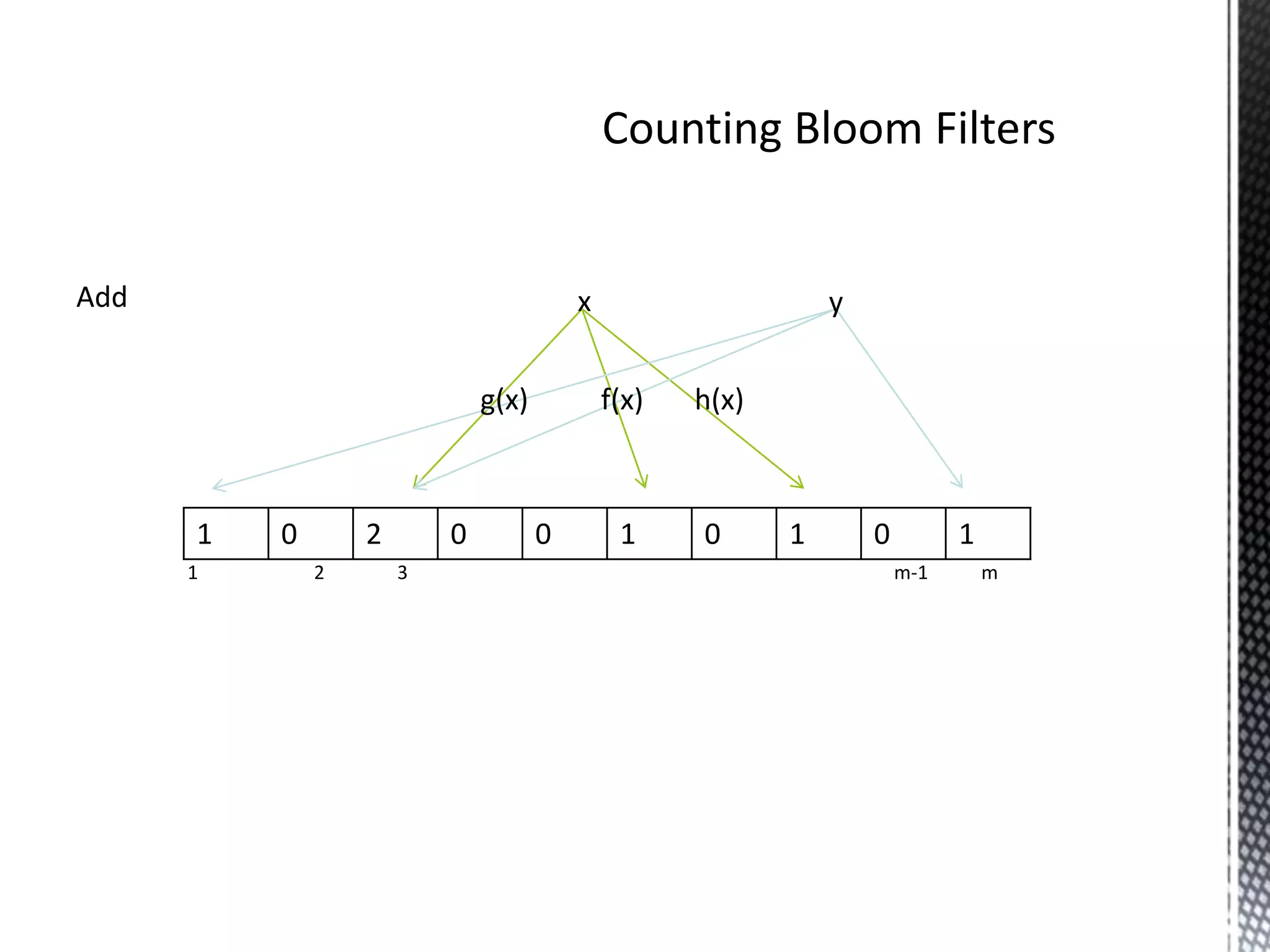






The document discusses Bloom filters, which are compact data structures used to represent sets probabilistically. Bloom filters allow membership queries to determine if an element is in a set, but may return false positives. They provide a more space-efficient alternative to other data structures like hash tables. The key properties of Bloom filters are that they require less memory than other solutions, allow fast membership checking, and never return false negatives, though they can return false positives. Several applications of Bloom filters are also mentioned such as spell checkers, password checking, and caching.



































































