




![Making Data scale
• Key-Value store
• Map <K,V>
• Plus events, listeners, processors,
location awareness and more…
[Oracle Coherence, GemFire,
Gigaspaces – and now Hazelcast]](https://image.slidesharecdn.com/01neilavery-151130124806-lva1-app6892/85/EVOLVING-PATTERNS-IN-BIG-DATA-NEIL-AVERY-6-320.jpg)







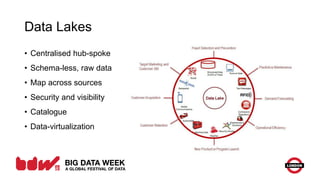
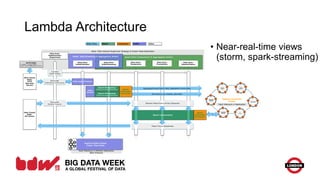
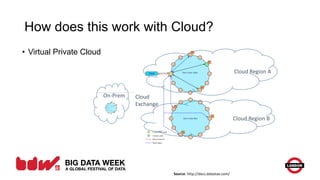






The document discusses evolving patterns in big data usage, including enterprise data caching using massive key-value stores, enterprise messaging pipes using Kafka, and NoSQL as a service. It also covers data lakes for centralized raw data storage and Lambda architecture for near real-time and batch processing. Current trends include growing Cassandra usage, Kafka for scalable messaging, and containerization and cloud adoption. Future areas may include graph databases, Spark evolution, and data virtualization.





































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















