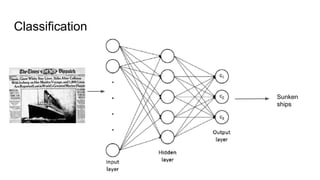
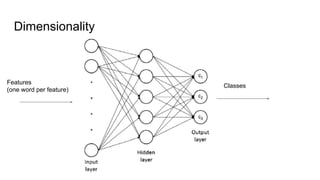
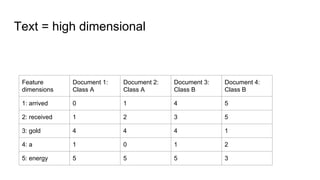
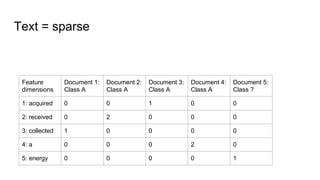
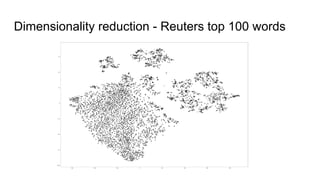
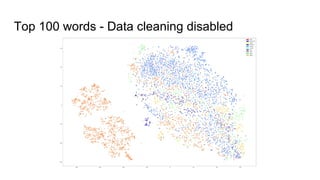
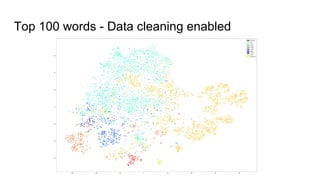
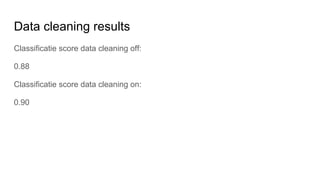
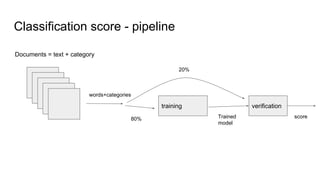
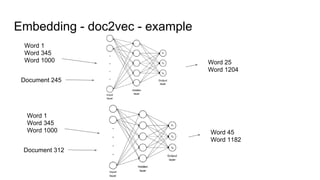
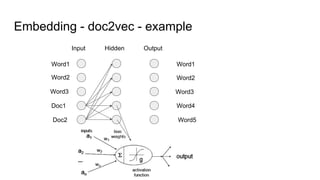
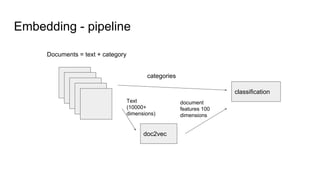
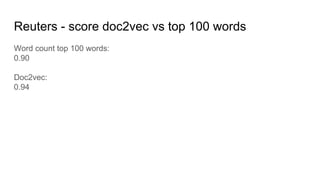
The document discusses text classification and different techniques for performing classification on text data, including dimensionality reduction, text embedding, and classification pipelines. It describes using dimensionality reduction techniques like TSNE to visualize high-dimensional text data in 2D and how this can aid classification. Text embedding techniques like doc2vec are discussed for converting text into fixed-dimensional vectors before classification. Several examples show doc2vec outperforming classification directly on word counts. The document concludes that extracting the right features from data is key and visualization can provide insight into feature quality.