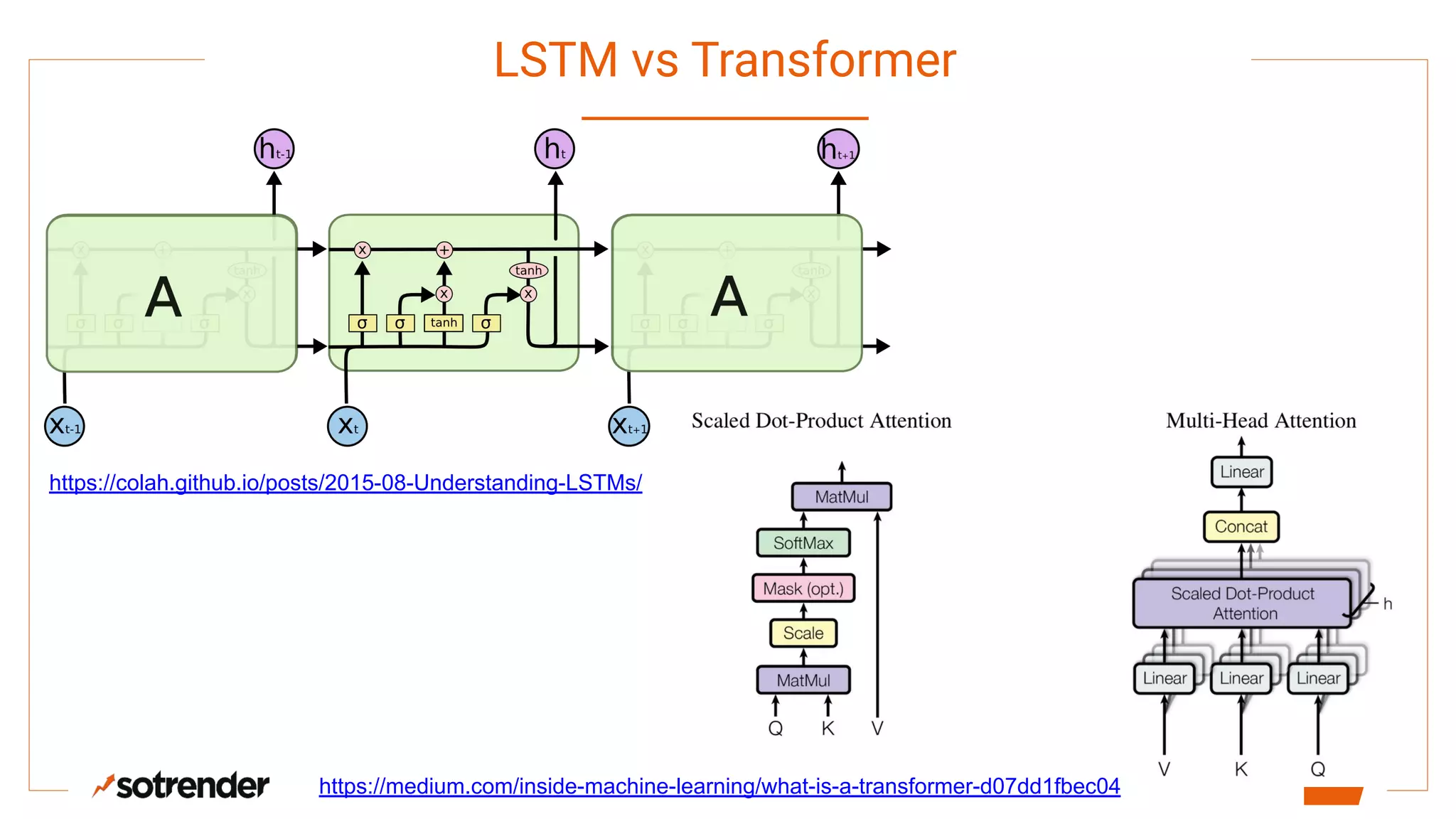
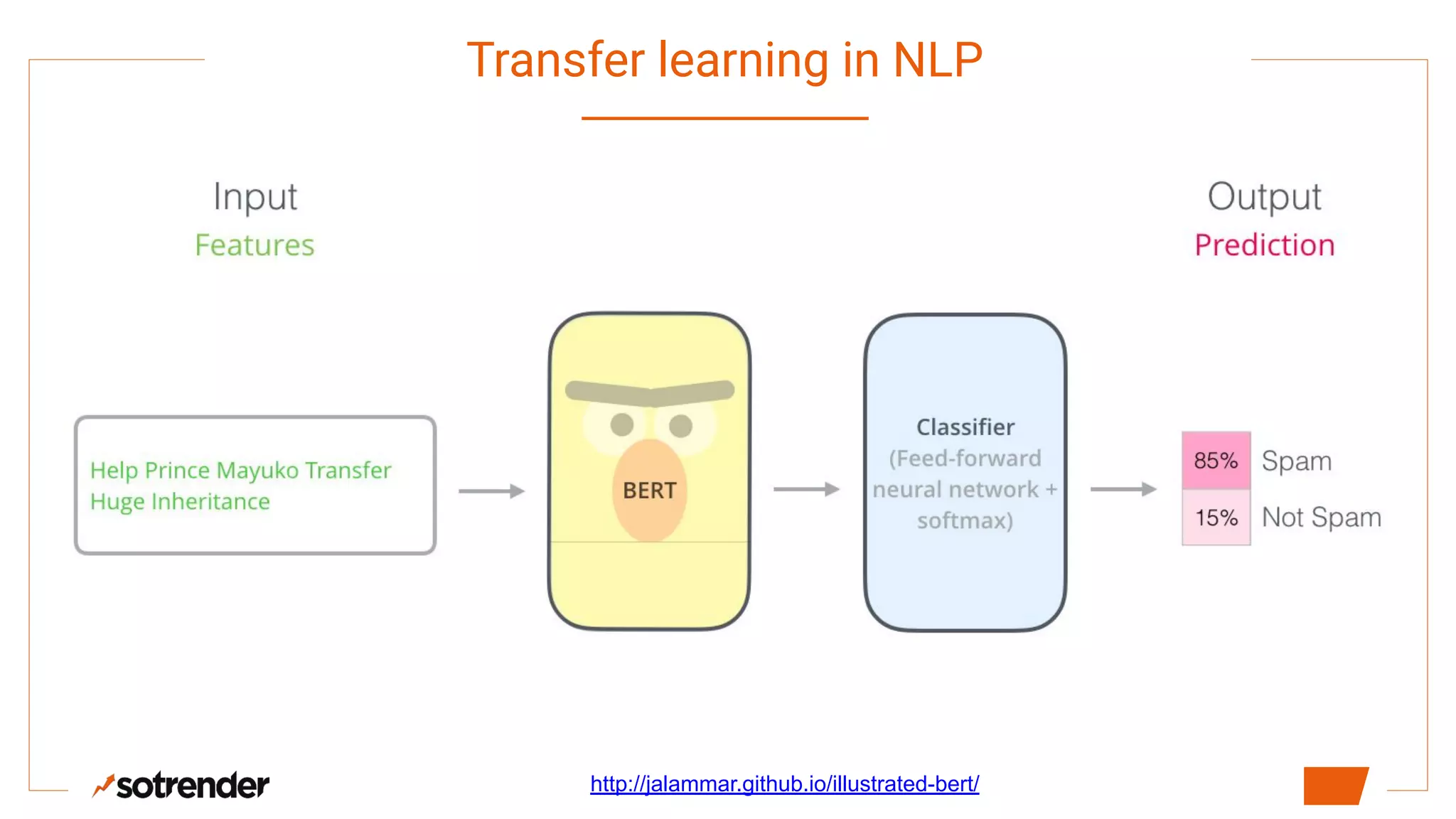
Transfer learning in NLP has become important for business. Contextual word embeddings like ELMo and BERT provide context-dependent representations of words that address issues with earlier static embeddings. While shallow embeddings are easy to train and small in size, they cannot represent different meanings of words or handle out-of-vocabulary words. Contextual embeddings provide context-aware representations but require more complex neural architectures, while transformer-based models like BERT can be used for embeddings or fine-tuning but are very large in size and require significant computing resources to train.


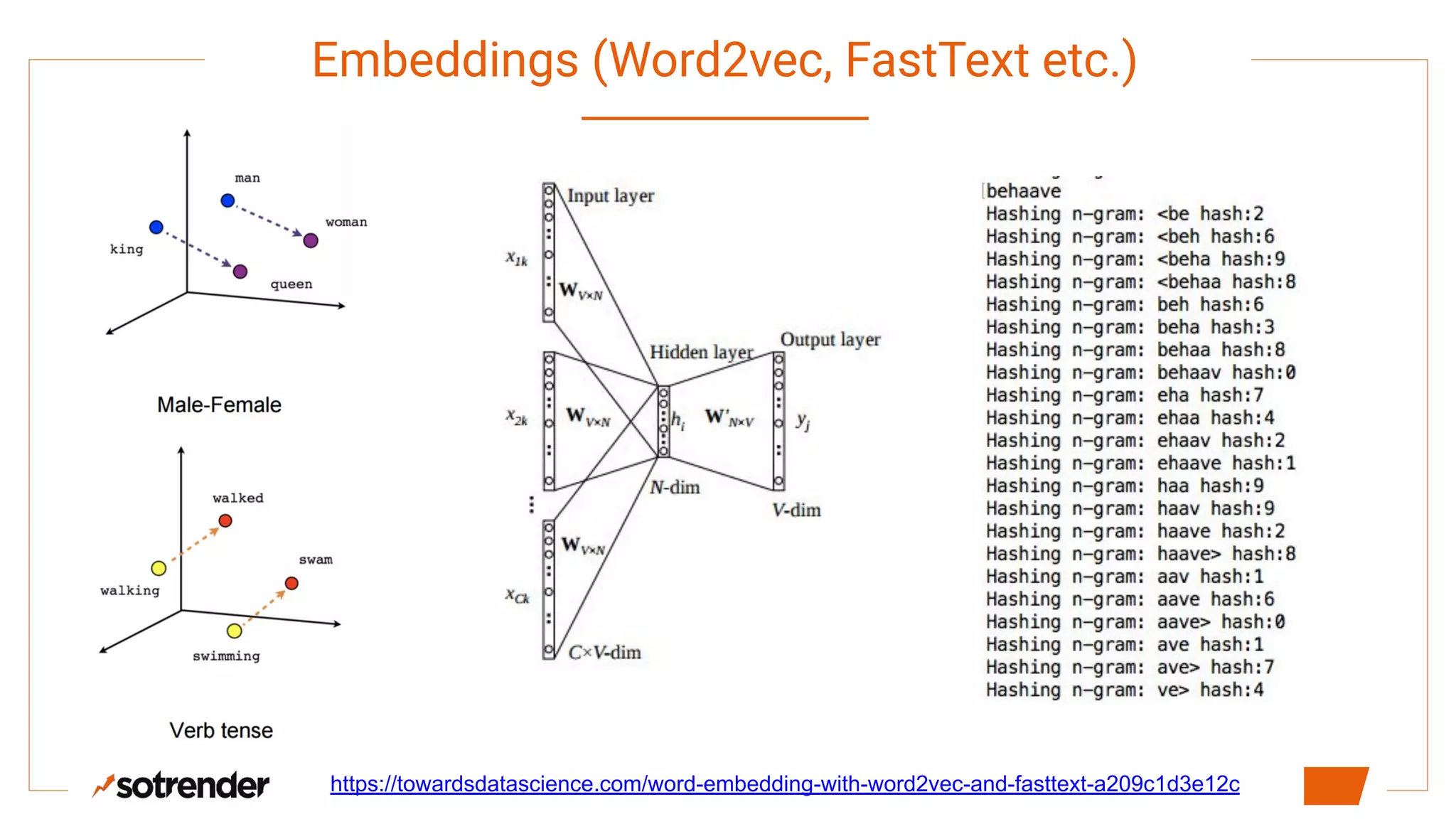
![So what is wrong with that?
[0.0, 0.0, …, 0.0]](https://image.slidesharecdn.com/dss2019-transferlearninginnlp-190614163955/75/DSS-2019-Transfer-Learning-in-Nlp-4-2048.jpg)