Downloaded 50 times

















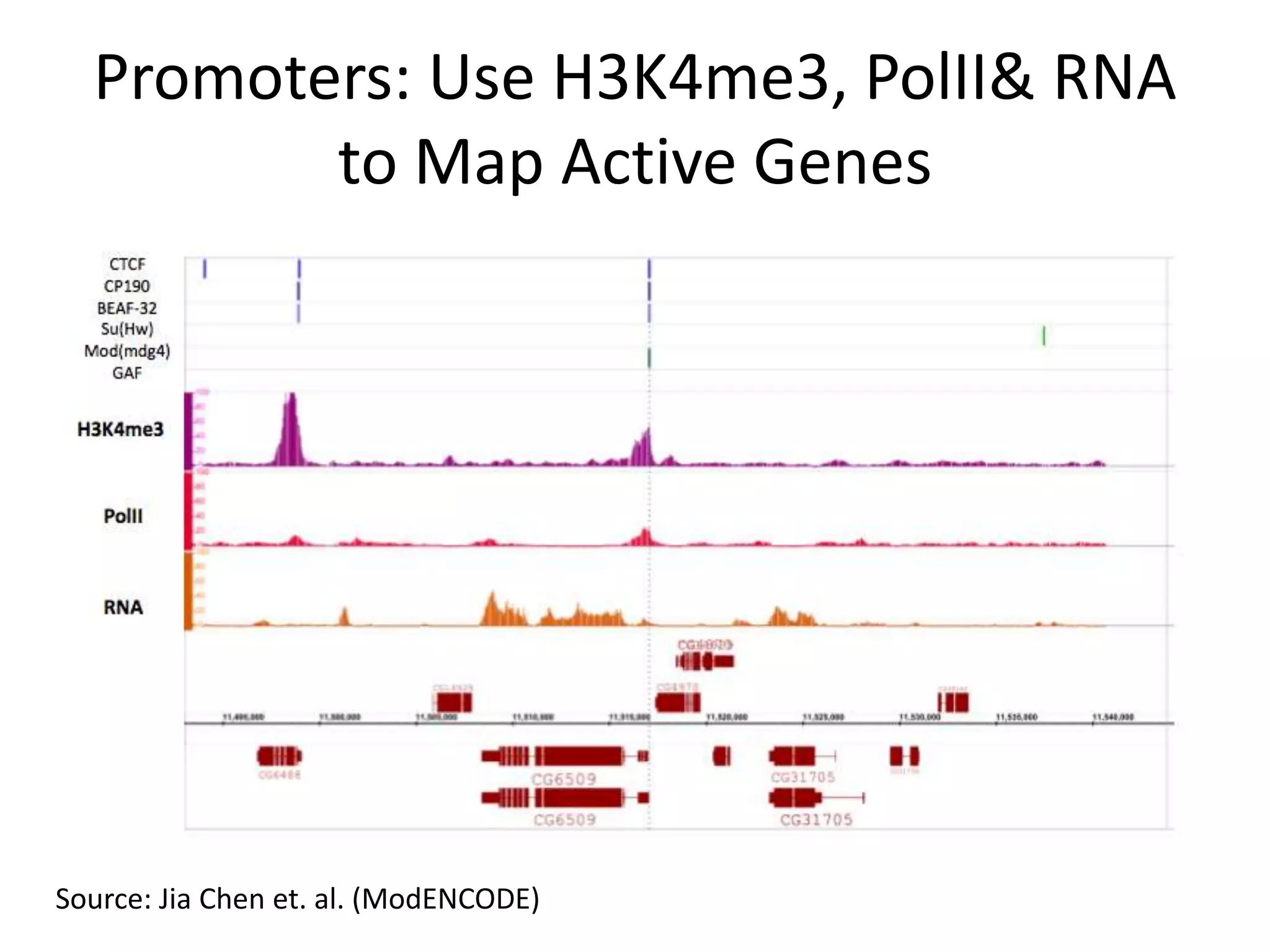
![Active Gene - MethodK4Me3 to TSS distanceGene Activeness: Label a transcript t as XYZX=1 if a H3K4Me3 binds in [-1800, min(2200, TranscriptLength)]Y=1 if a Pol II binds in [-1800, min(2200, TranscriptLength)]Z=1 if at least one exon has ≥30% covered by RNA, and in total ≥10% covered by RNA.Pol II to TSS distanceSource: Jia Chen et. al. (ModENCODE)](https://image.slidesharecdn.com/grossman-transformation-systems-biology-into-large-data-science-12-07-09-091220094943-phpapp02/75/The-Transformation-of-Systems-Biology-Into-A-Large-Data-Science-30-2048.jpg)

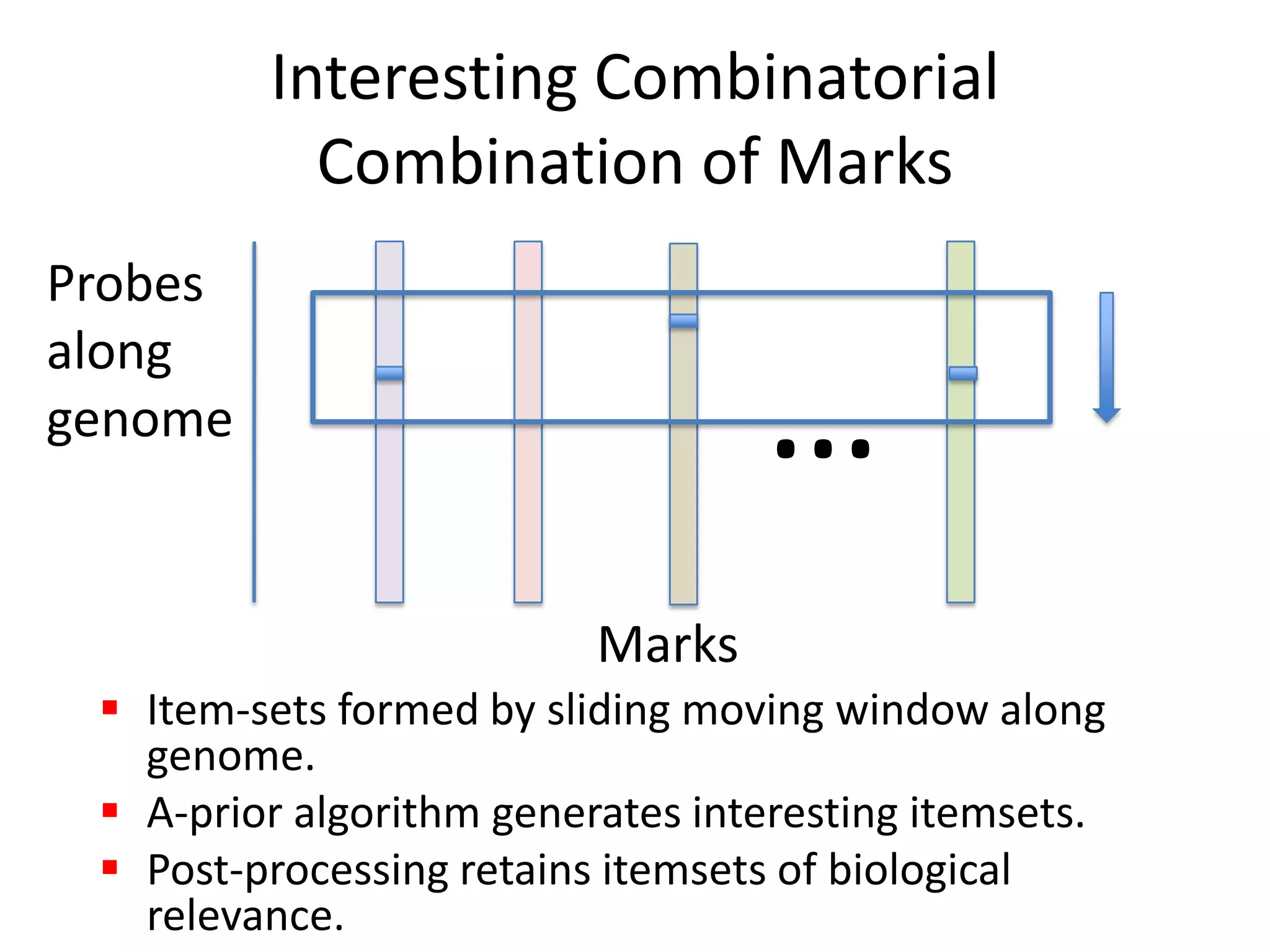


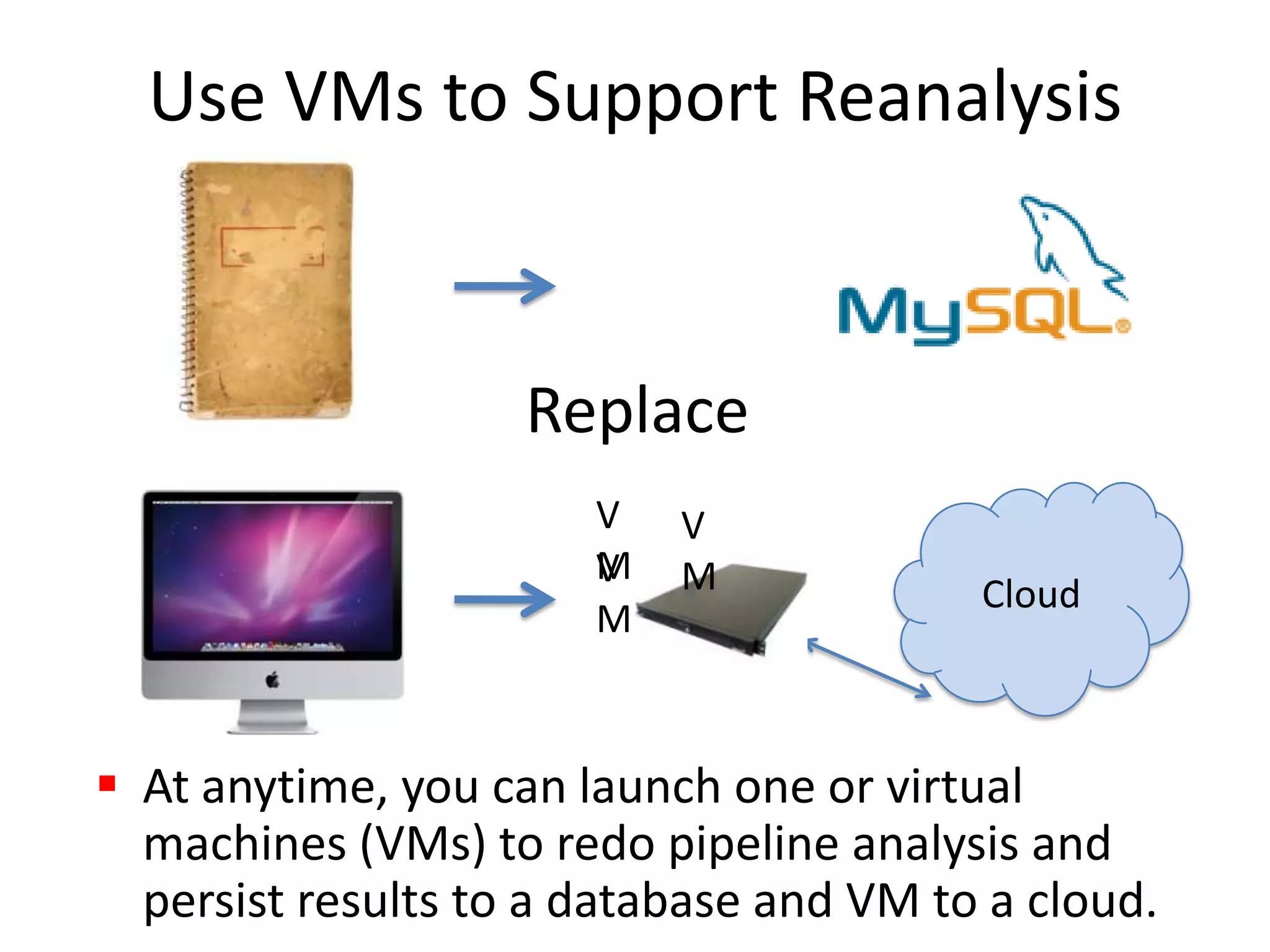




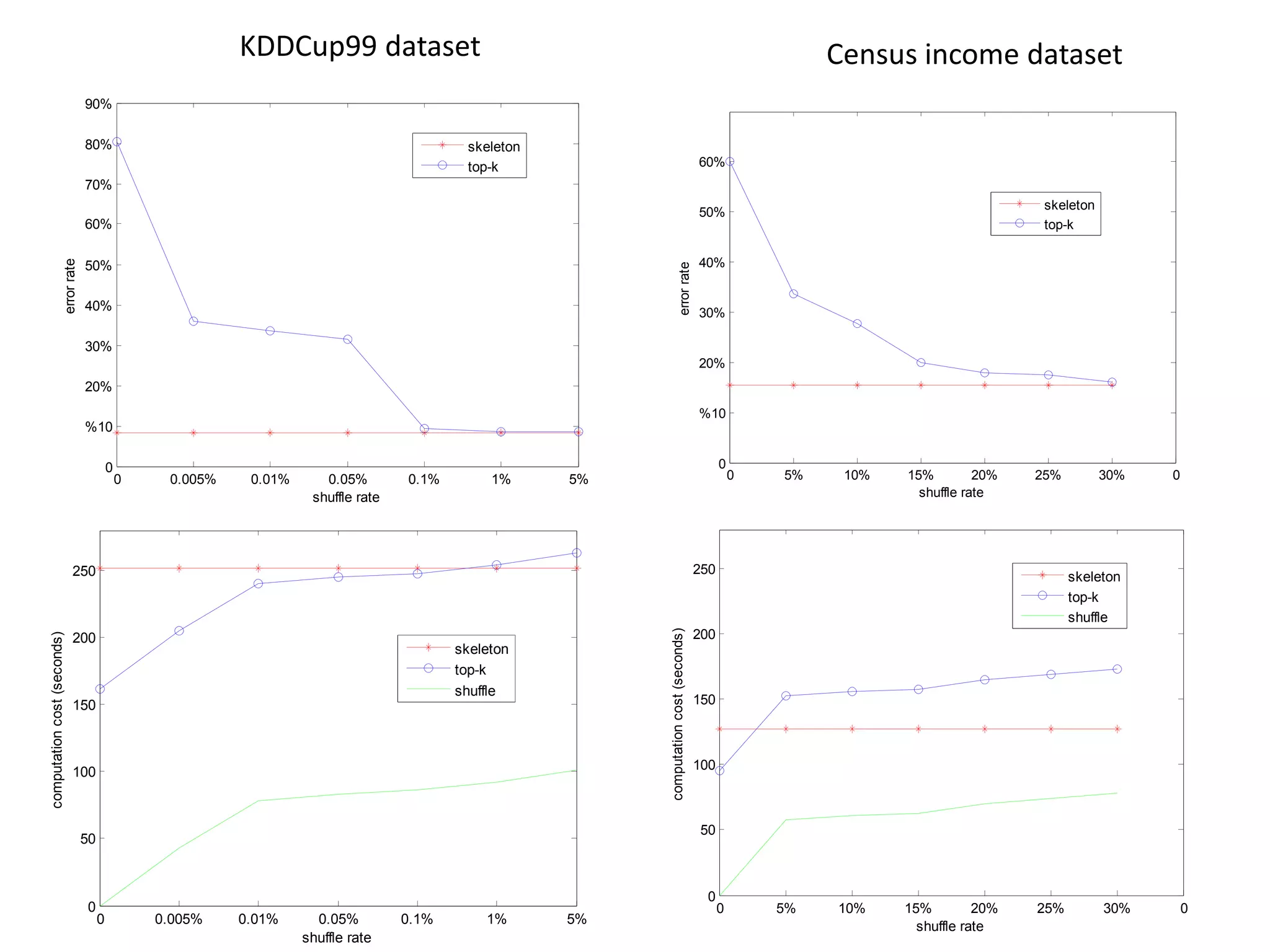


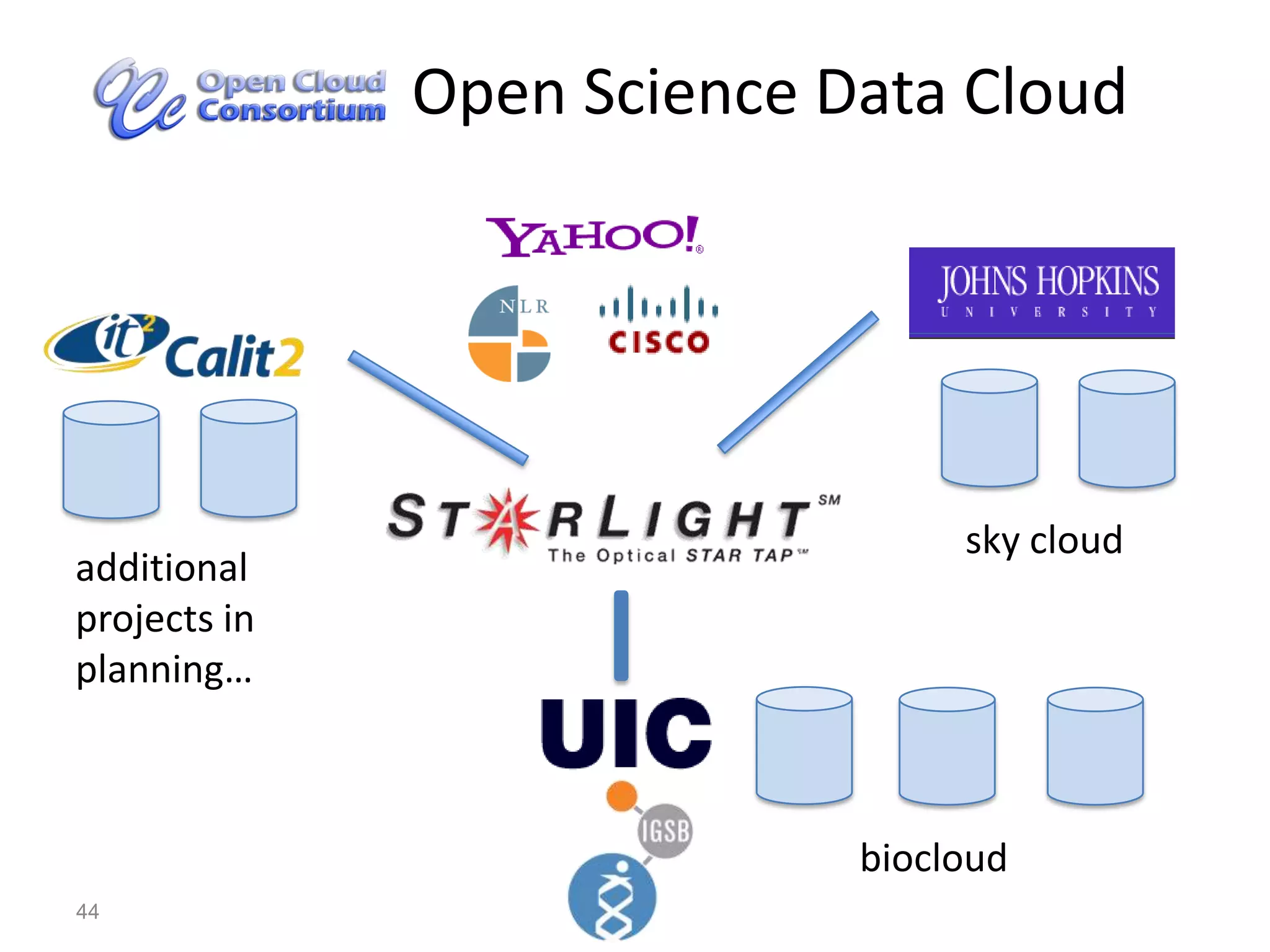





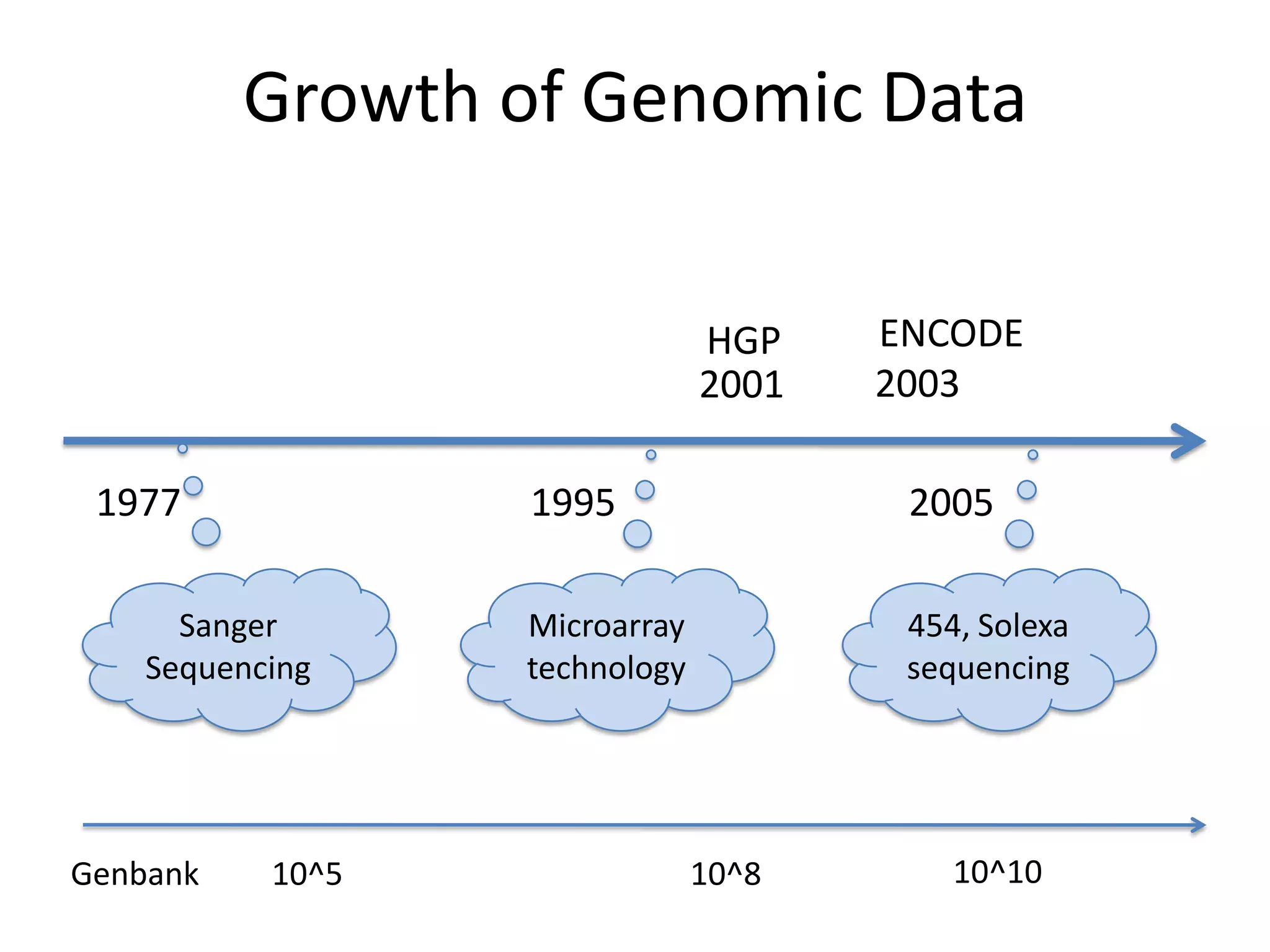
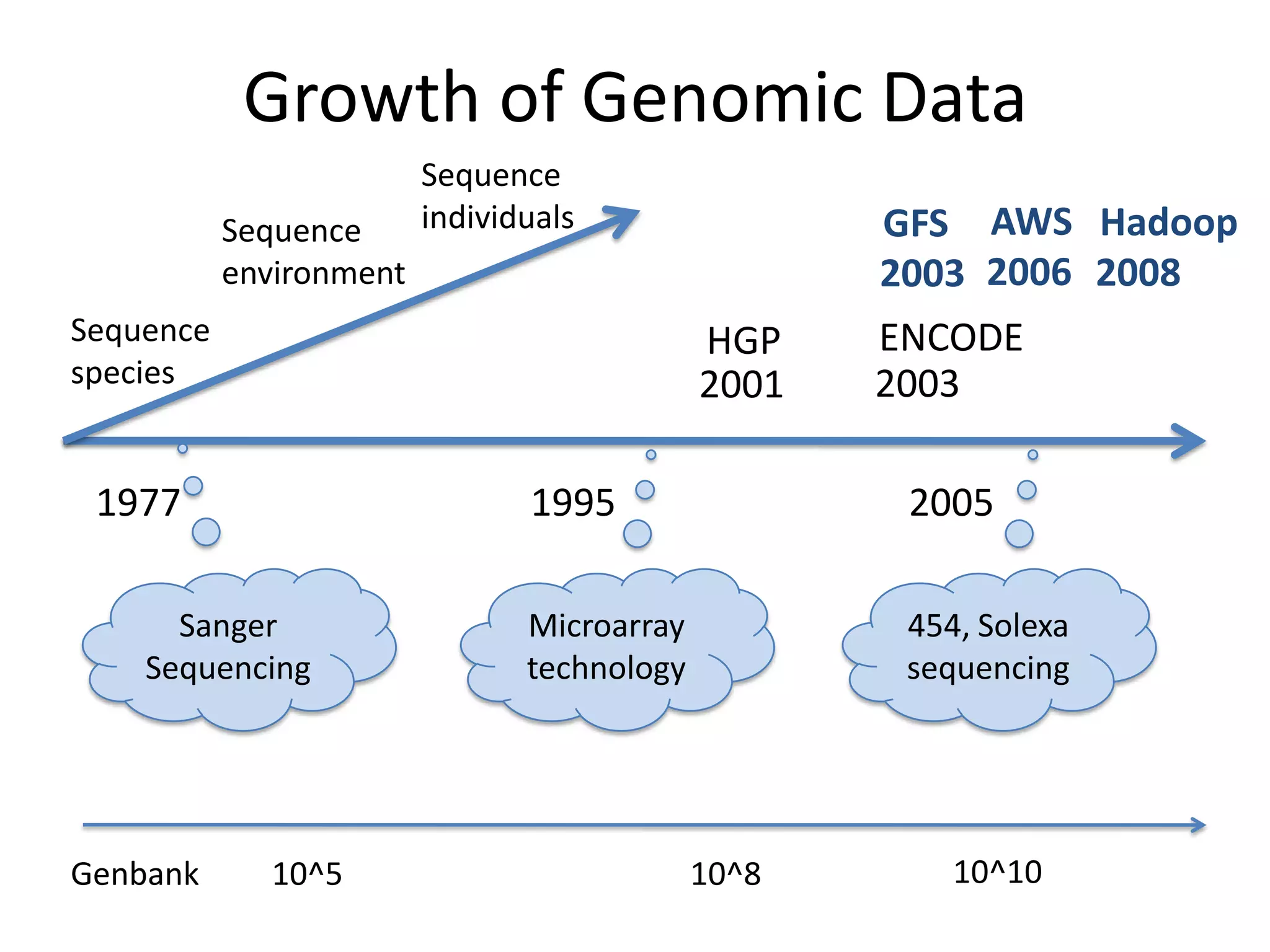
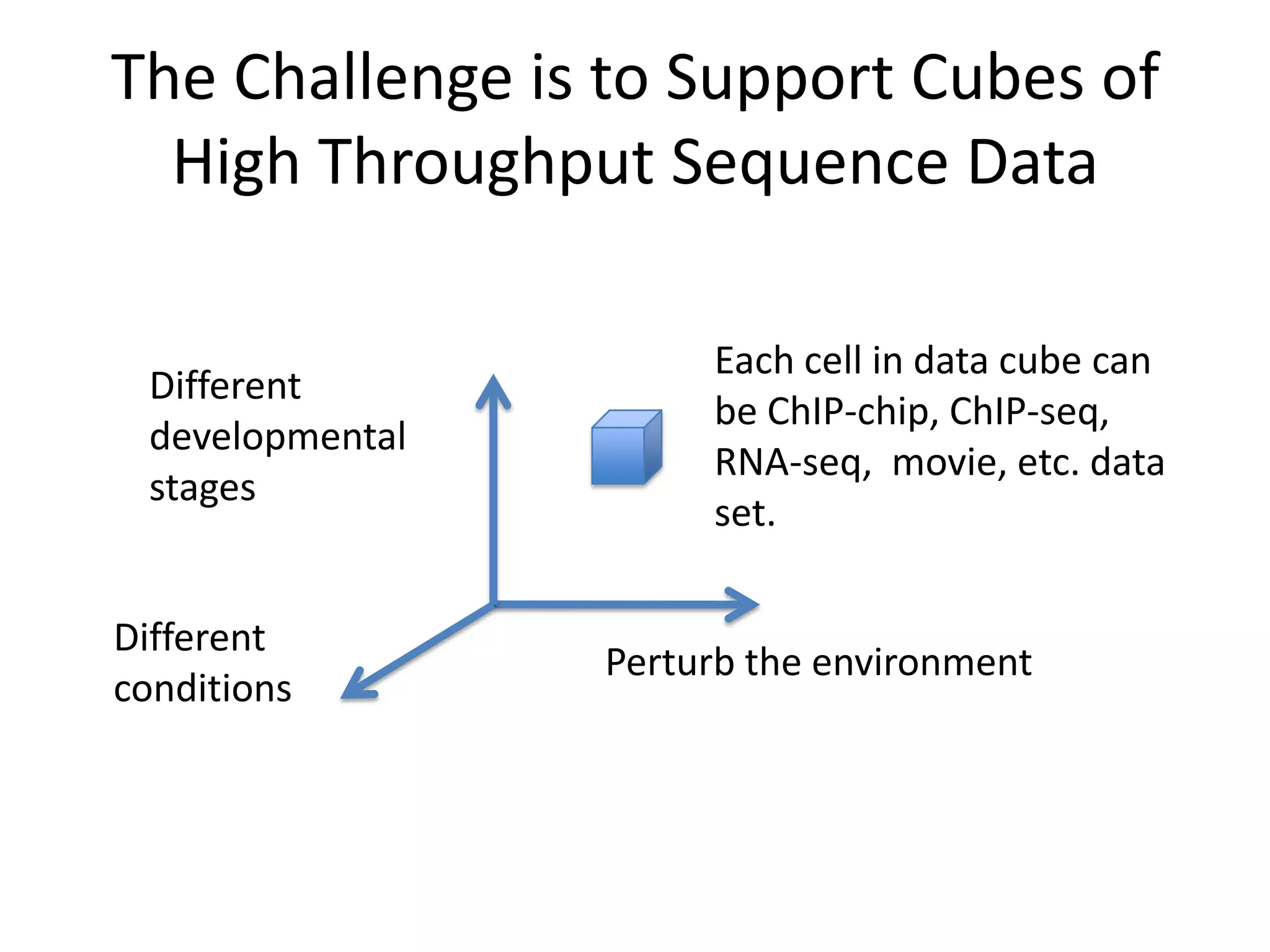
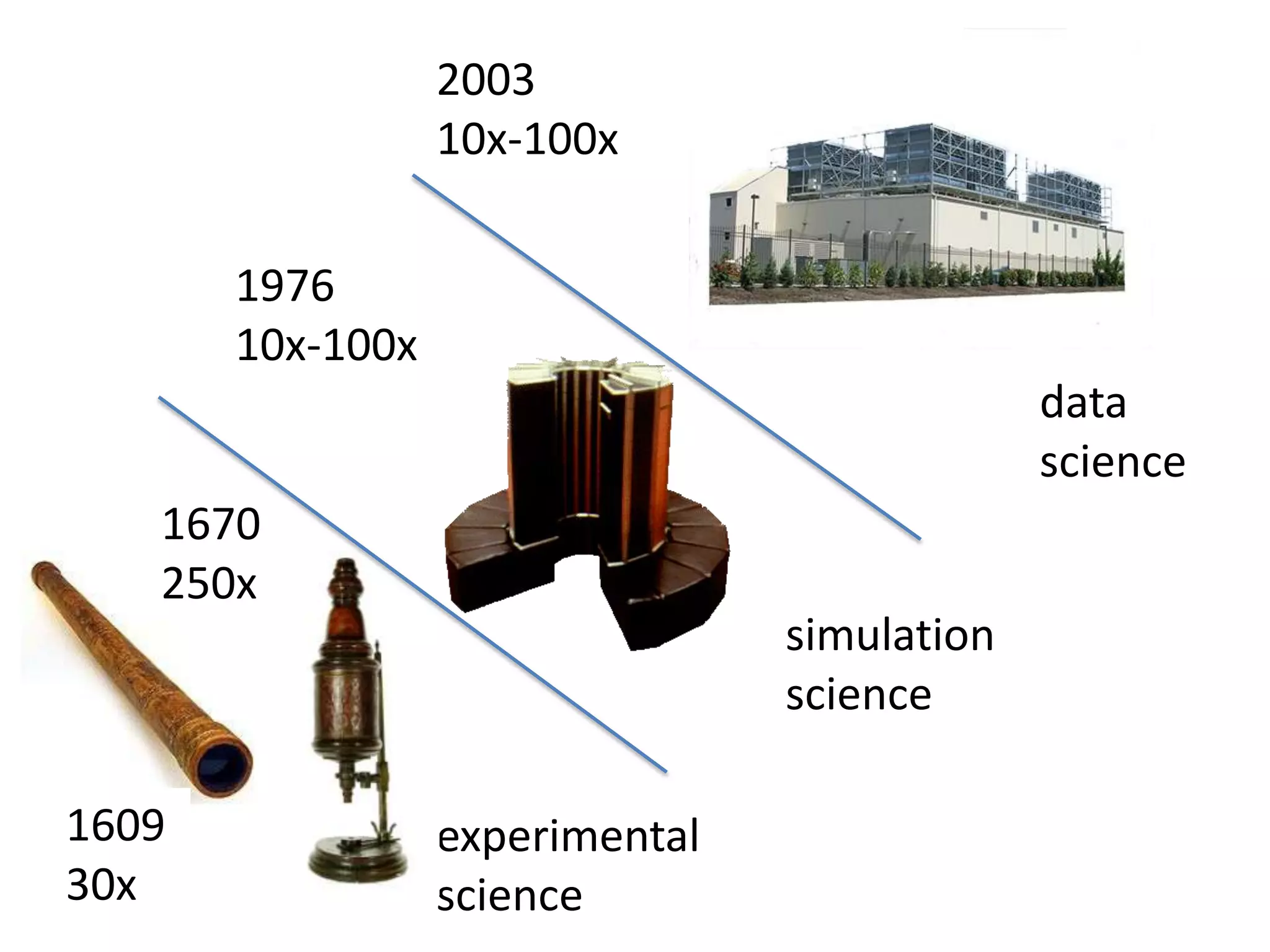
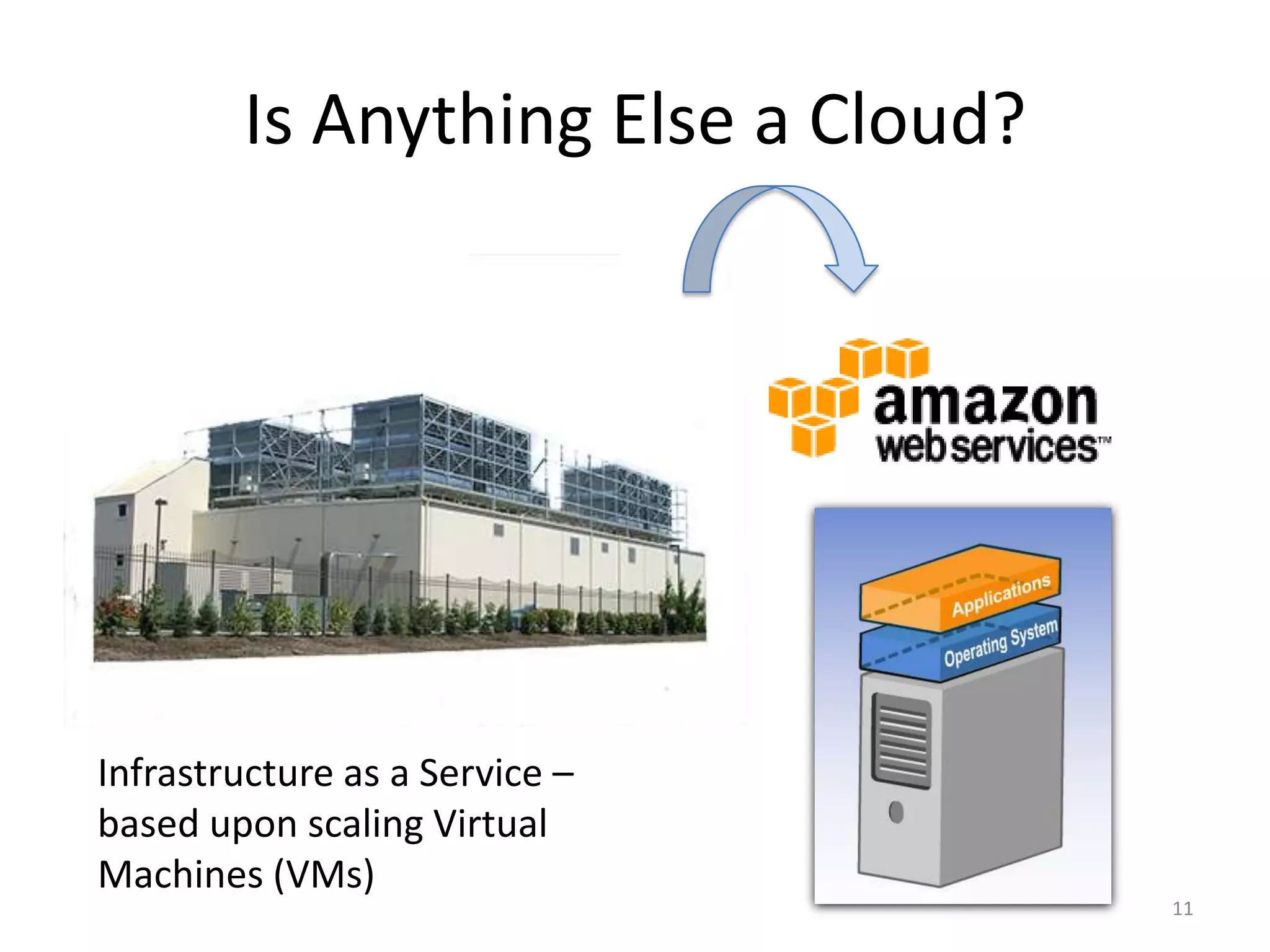
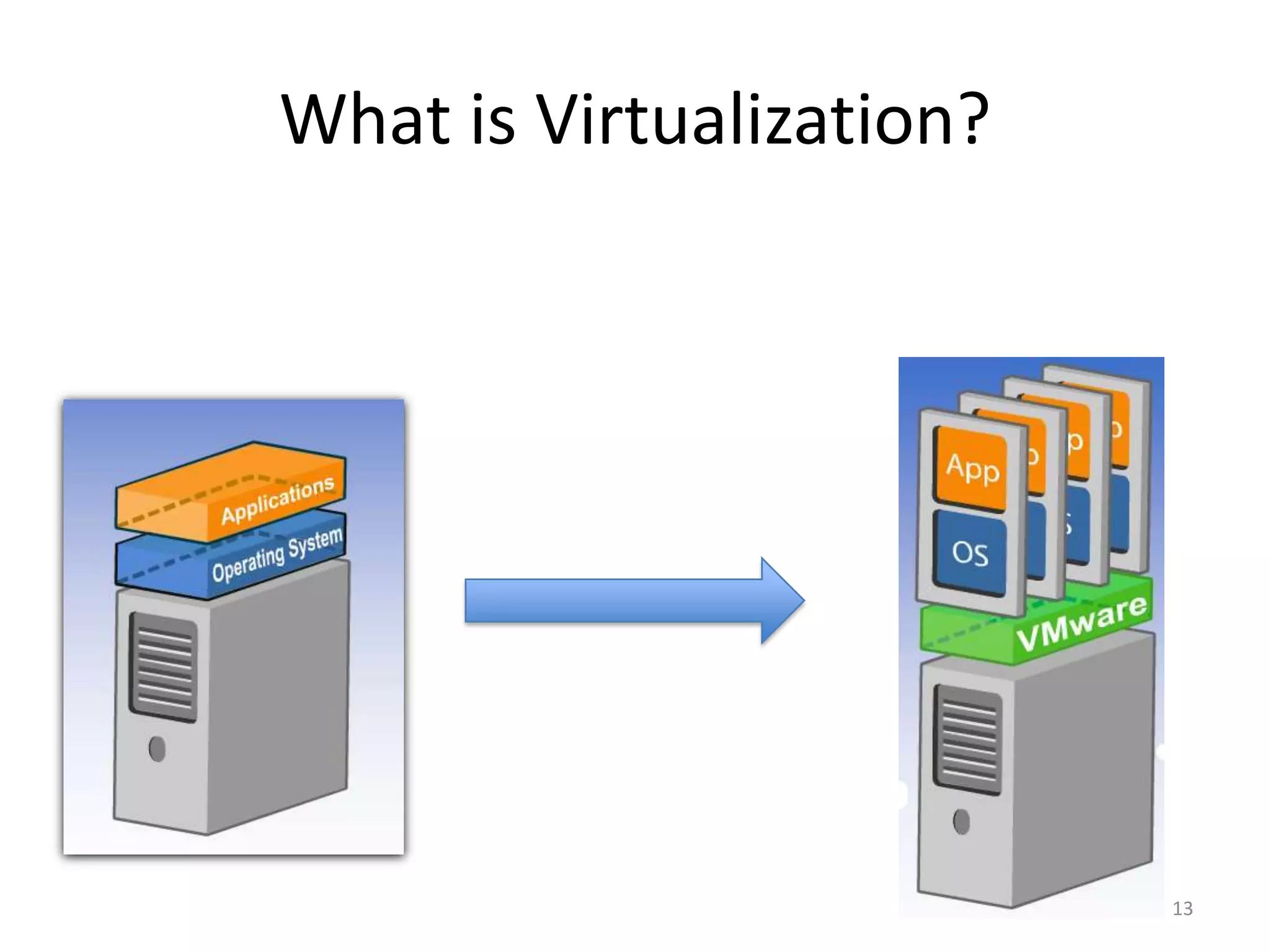
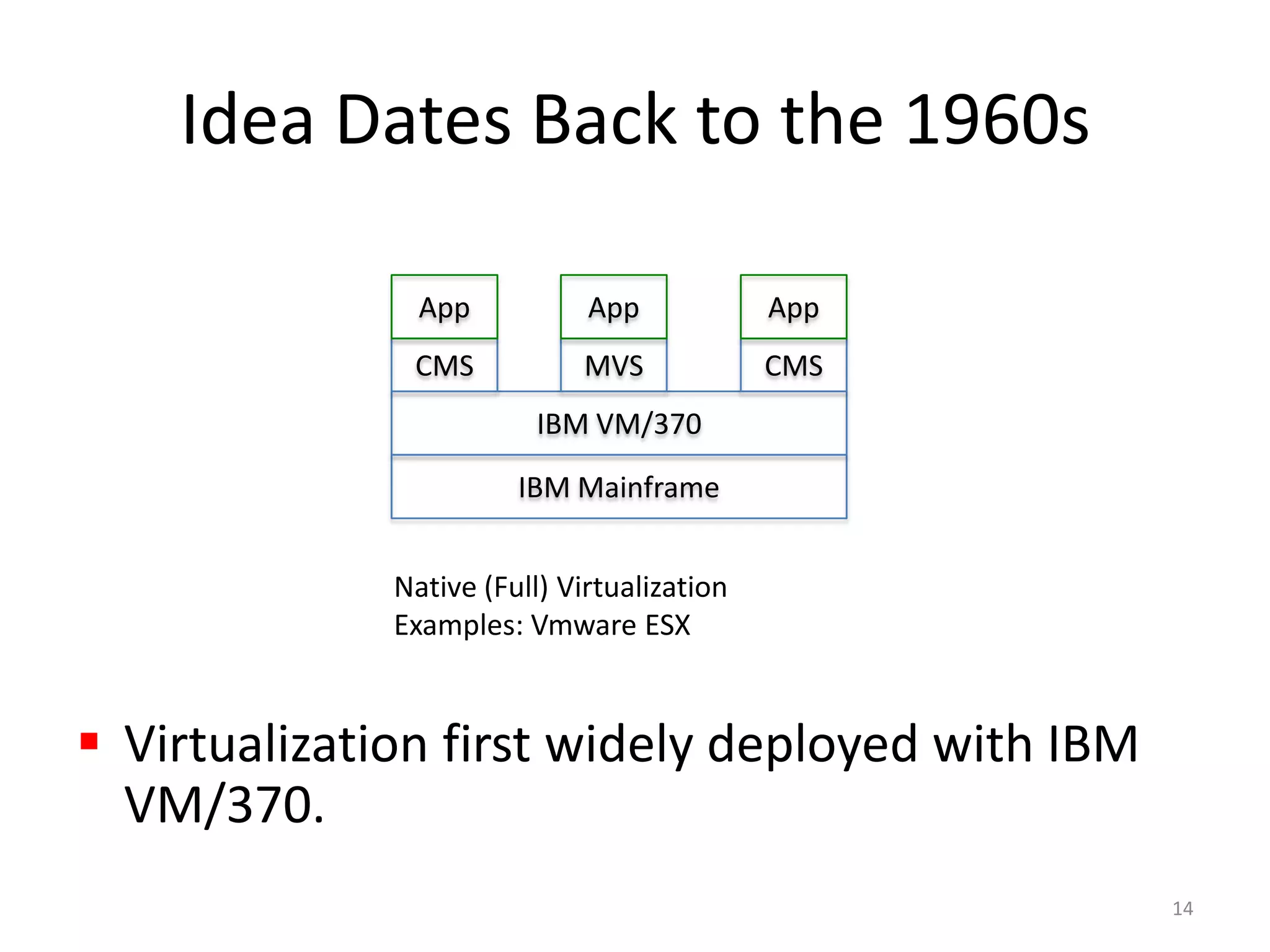
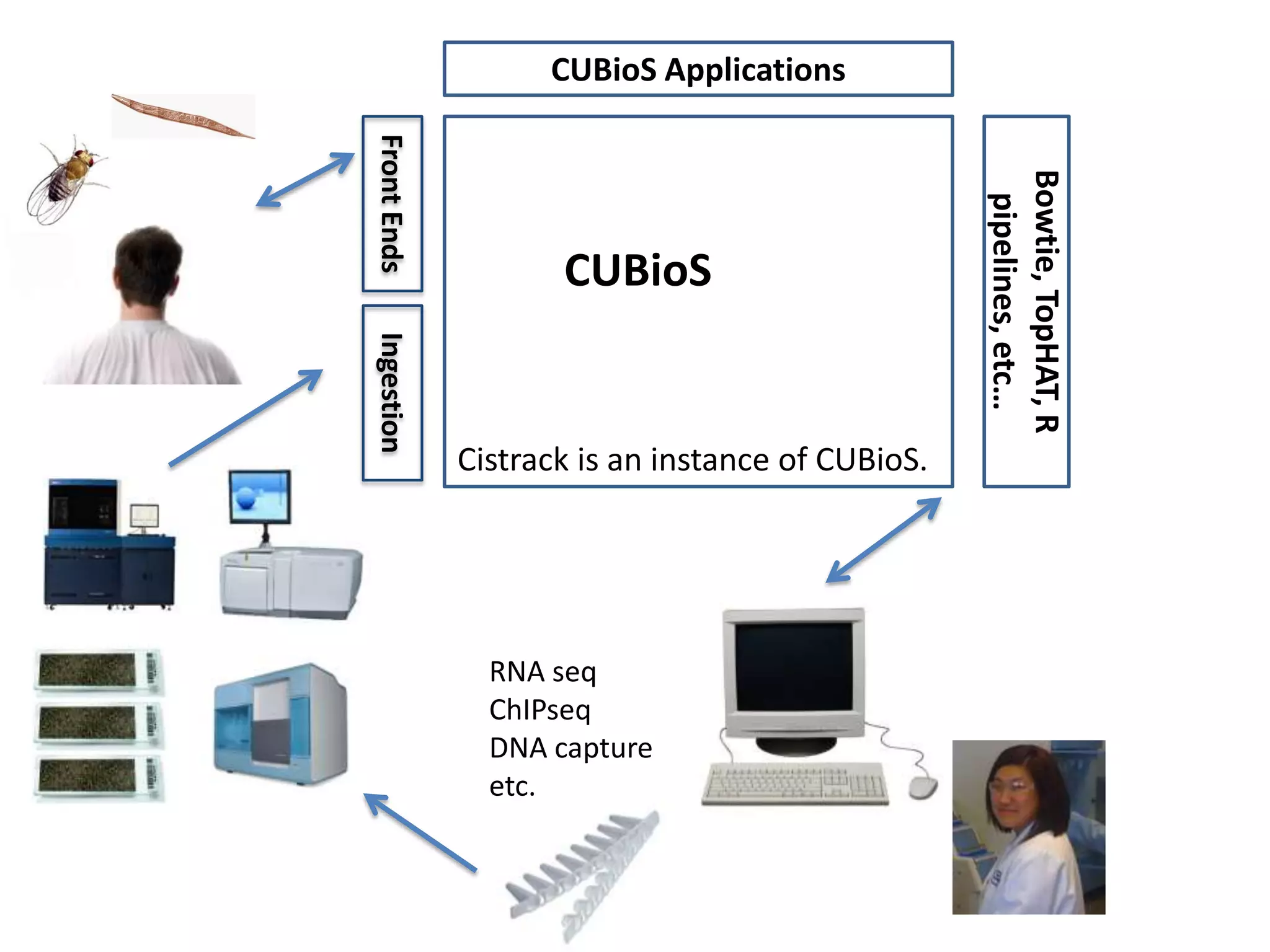
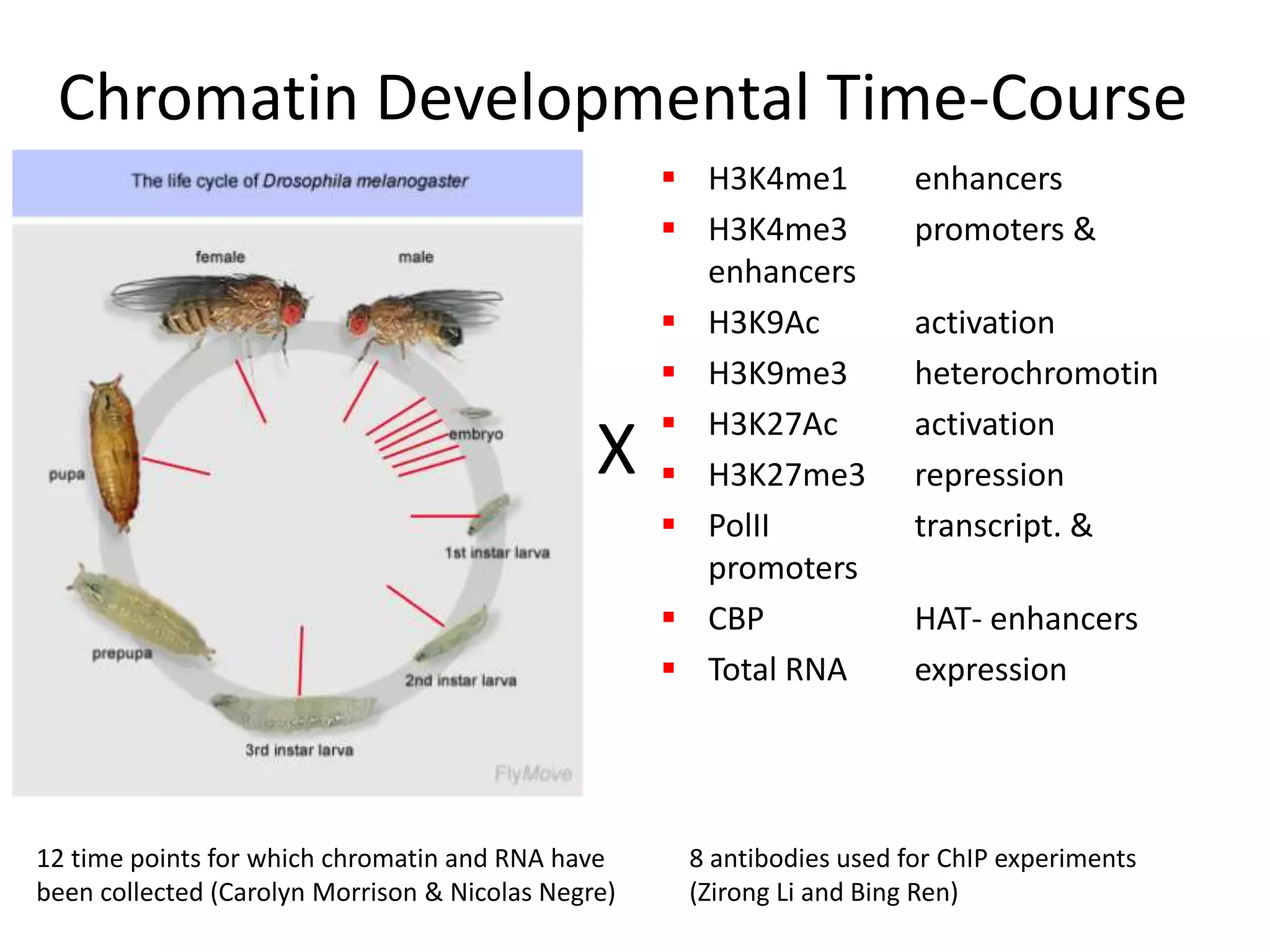
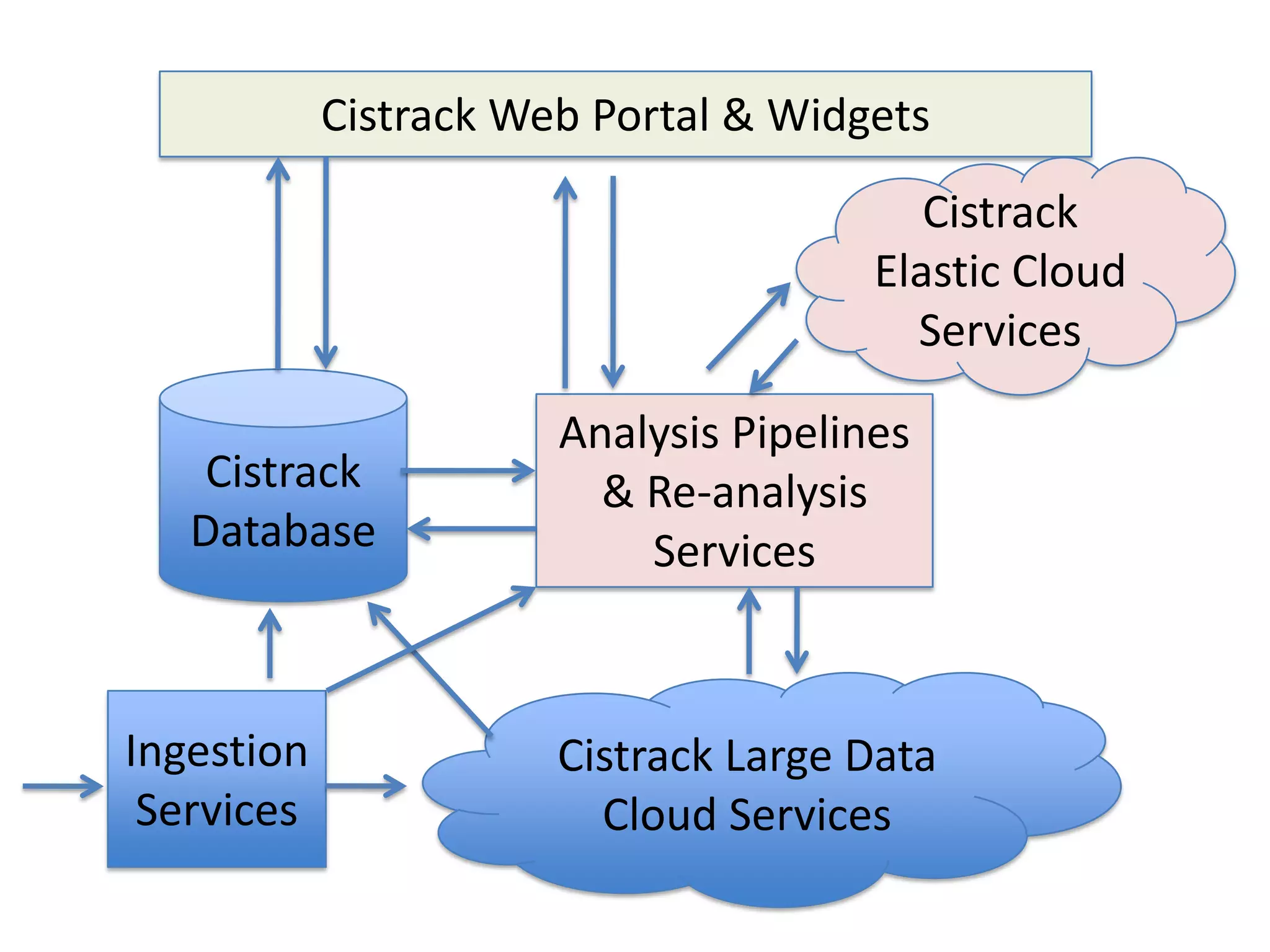
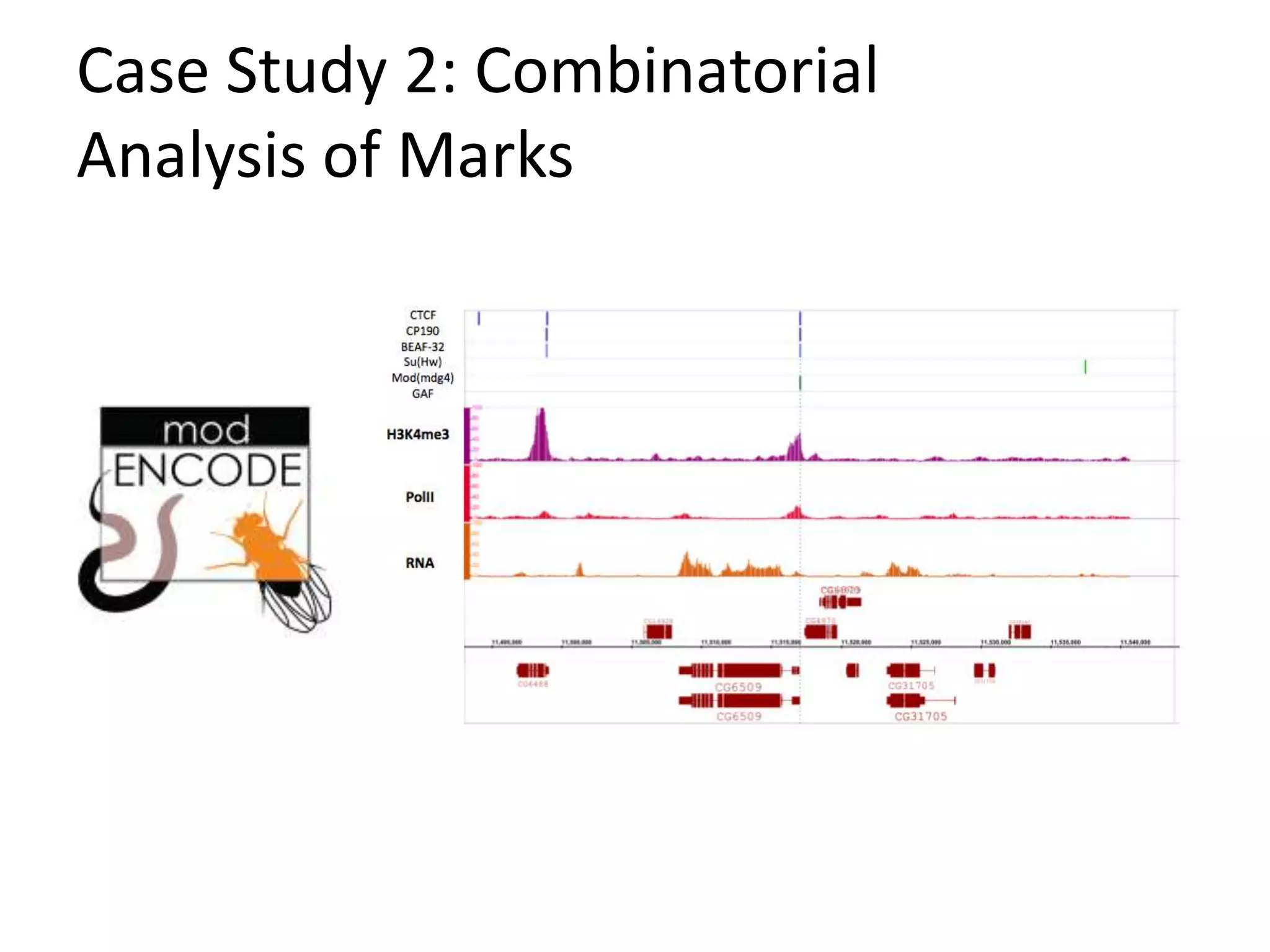
Systems biology is becoming a data-intensive science due to the exponential growth of genomic and biological data. Large projects now produce petabytes of data that require new computational infrastructure to store, manage, and analyze. Cloud computing provides elastic resources that can scale to support the increasing data needs of systems biology. Case studies show how clouds are used for large-scale data integration and analysis, running combinatorial analysis over genomic marks, and enabling reanalysis of biological data through elastic virtual machines. The Open Cloud Consortium is working to provide open cloud resources for biological and biomedical research through testbeds and proposed bioclouds.










































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












